There is a not-very-healthy series of attacks on the RCUK’s policy of insisting on funded articles carrying CC-BY licences wherever possible. They emanate mainly from non-scientists and, unfortunately, it seems necessary for me to counter this. I will simplify the criticisms of RCUK policy to:
- It is forcing scientists to publish elsewhere than their journal of choice.
- It is a waste of money (“Green is cheaper”).
These are perhaps oversimplifications but the whole situation is extremely messy (the publishers help to create lots of FUD, academics are arrogant, and libraries have not taken a coherent position). Any more complex argument is based on irreconcilable starting points. I concentrate on (2). I don’t believe (1) represents the RCUK’s position. And personally I am not in favour of journals. I think megajournals such as PLoS, or ArXiV (as overlaid by the mathematicians) are completely satisfactory for scientific *peer-review and communication*. The only remaining value of journals today is to add a perceived “value” to a scientist’s work. And most of the wasted expense of publication is because academics cannot be bothered to review other scientists – they rely on journal rankings, decided by an archaic metric and unaccountable commercial companies.
To (2). There is a huge waste of money in #scholpub because of its non-competitiveness and inefficiencies. It costs 7 USD to put a paper in Arxiv and perhaps 250 to review it. Current journals charge 2000-7000 USD per paper (whether “Gold” or “Green”). There is no evidence that mainstream heavy-traffic subscription journals where “Green” is practicised cost less than “Gold”. It’s simply that in one case the university bears the cost while in others the funder bears it. In most (but not all) the cost of subscriptions and of author charges is ultimately borne by the taxpayer (in subscription the students also pay). I don’t know the figures, but the average price of a mainstream subscription journal article is around 5000 USD, considerably higher that than the average APC. This process is not subject to the market = the good is not substitutable.
There are huge inefficiencies in the current subscription model. Here are some:
- Typesetting (ca 100 USD per paper). The main effect of typesetting is to destroy quality. The papers submitted to ArXiV are of higher typographical quality than mainstream journals (my analysis)
- Salesforce. Why should readers pay for this. In OA they don’t
- Flashy mastheads on journals. These server no scientific purpose and destroy parts of the scientific communication.
- Provision of paywall technology. Subscribers have to pay for this.
- High-paid lawyers to sue pirates. Readers have to pay for them.
IN OA none of these are necessary. If you really want double-column PDF with publishers’ logos and arcane reference formatting I can supply Open software that will convert the ArXiV material.
Because the funding comes from different places any move from subscription to APCs (article processing charges) will cost money. I agree. But I think the problem will be shortlived.
- The funders have coordinated their policy in a way that 15 years of university neglect have failed to do. This coordination will lead to much greater pressure on publishers to provide value-for-money. If the publishers didn’t feel the pressure why are they squealing so loudly? Why SOPA/ Why PIPA? And, I discover today, the hydra-like TPP (http://en.wikipedia.org/wiki/Trans-Pacific_Strategic_Economic_Partnership which is – I gather – even worse than ACTA). The funders have the potential to – at least in part – regulate the publishers.
- CC-BY provides far more value than its detractors give it credit for. CC-BY gives real value beyond the ability to re-use. Let’s look at some:
- It can be mined and indexed. No robot can understand licences from non-CC publishers (cf RSC) because no human can. Therefore no mining.
- It can be repurposed. I can extract all the maps of biodiversity and collate them. I can annotate them. I can correct errors automatically. I can do this for 10,000 in an hour.
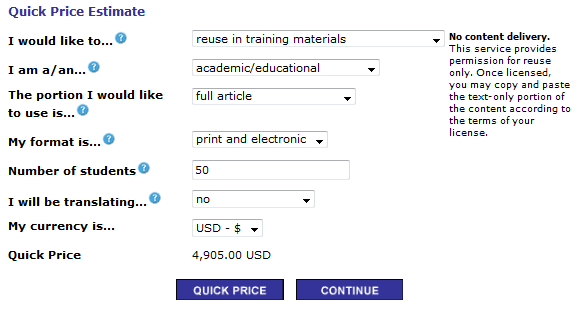
- It can be used for teaching. In New Zealand the Copyright Clearance system forbids fair use. It’s almost impossible to teach without paying huge amounts of money. The University of Auckland pays 1-2 million in permissions for teaching. For teaching
Let’s assume the RCUK support 10,000 papers per year. What’s the added cost of CC-BY? Multiply the sums and you get 10 million GBP (OK,you say, it’s more because of the current Gold hybrid charges. But when you have a determined customer then prices will fall.) Even this figure is far more than it should be.
But I would argue they have added significant value. Let’s ask whether 10,000 peer-reviewed collated papers would be valuable for teaching. I am sure that many universities would jump at the chance. Because in teaching there is much more substitutability. I will always use CC-BY MDPI Materials Science publications for teaching in preference to RSC or ACS because those are not CC-BY. It’s substitutable. And for teaching MDPI papers are almost certainly as good as RSC. Acta Cryst E papers can be used instead of RSC for crystallography.
I’m guessing, therefore, that world universities pay about 1 billion for permissions to use teaching materials. The RCUK CC-BY could cut this considerably for many countries. And if, say, they issued a free collection of all their output it would be really handy.
And I’ll turn it into semantic form for re-use.
The criticism of CC-BY looks at only one small part of the equation. In the larger picture CC-BY provides far more public good. It’s a pity that it will cost early adopters. But countries can and should and do act unilaterally for the good of humankind.
Aid though the free provision of scientific knowledge is probably one of the most politically acceptable and valuable methods.

















{kind=link}