My non-profit organization contentmine.org has the goal of making contentmining universally available to everyone through three arms:
- Advocacy. Why it’s so valuable and why you should convince others and why restrictions should be removed.
- Community. We need a large vibrant public community of practice .
- Tools. We need to be able to do this easily.
There is a lot of apathy and a considerable amount of push-back and obfuscation (mainly from mega-publishers) and it’s important that we do things correctly. So 4 of us wrote a document on how to do it responsibly:
Responsible Content MiningMaximilian Haeussler, Jennifer Molloy,Peter Murray-Rust and Charles Oppenheim
The prospect of widespread content mining of the scholarly literature is emerging, driven by the promise of increased permissions due to copyright reform in countries such as the UK and the support of some publishers, particularly those that publish Open Access journals. In parallel, the growing software toolset for mining, and the availability of ontologies such as DBPedia mean that many scientists can start to mine the literature with relatively few technical barriers. We believe that content mining can be carried out in a responsible, legal manner causing no technical issues for any parties. In addition, ethical concerns including the need for formal accreditation and citation can be addressed, with the further possibility of machine-supported metrics. This chapter sets out some approaches to act as guidelines for those starting mining activities.…Content mining refers to automated searching, indexing and analysis of the digital scholarly literature by software. Typically this would involve searching for particular objects to extract, e.g. chemical structures, particular types of images, mathematical formulae, datasets or accession numbers for specific databases. At other times, the aim is to use natural language processing to understand the structure of an article and create semantic links to other content.
and we gave a typical workflow (which will be useful when we discuss copyright).
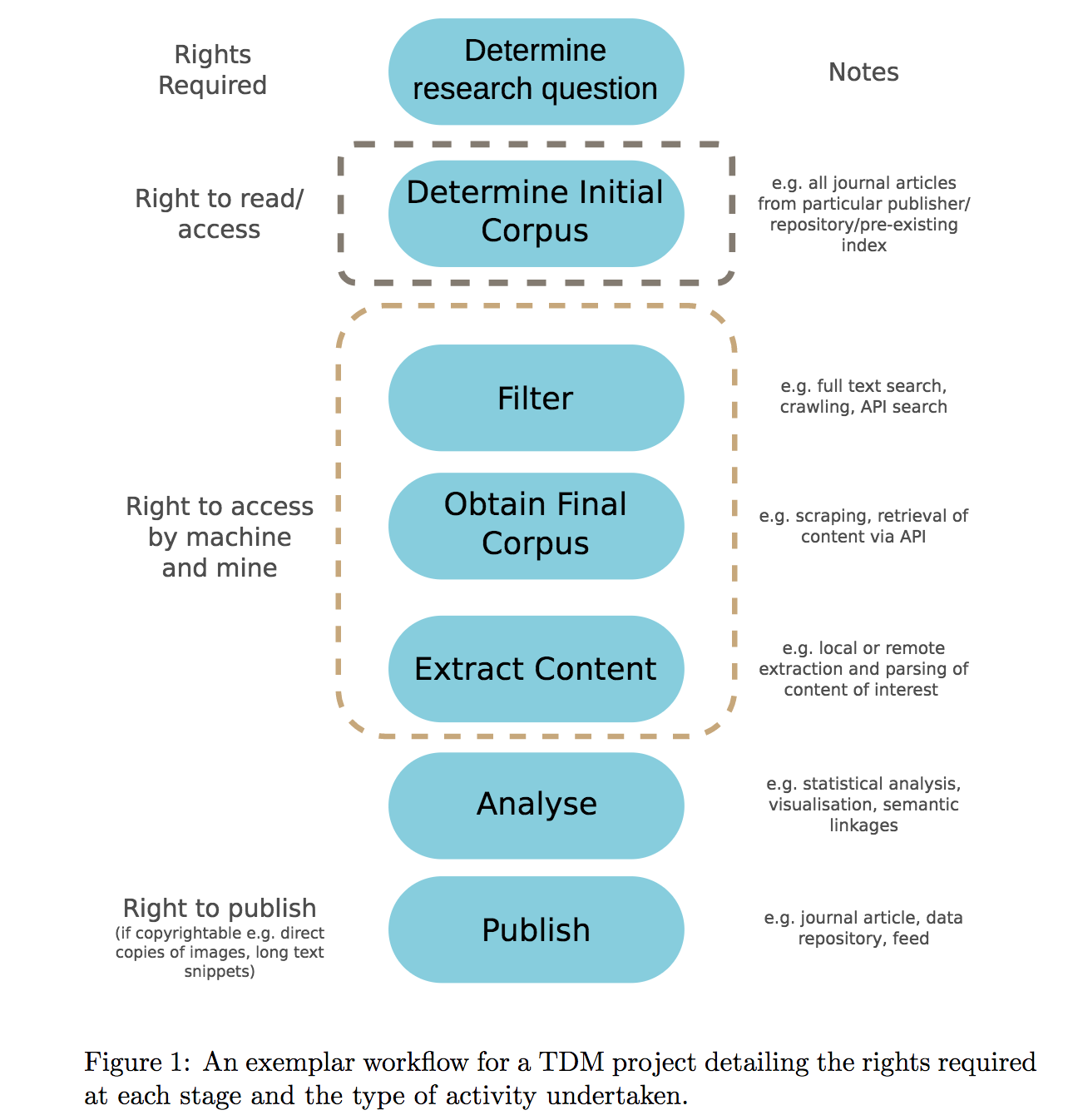
Of course there are variants, and particularly where we start with bulk downloading and then searching. For example we are now downloading all Open content, processing it and indexing against Wikidata. There is little point in everybody doing the same thing and, because the result is Open, everyone can share the results of processing.
We’ll use this diagram in later posts.