I have the huge opportunity to present a vision of the future of science at @WikimaniaLondon (Friday 2014-08-08:1730) . I am deeply flattered. I am also deeply flattered that the Wikipedians have created a page about me (which means I never have to write a bio!). And that I have been catalogued as an Activist in the Free culture and open movements.
I have always supported Wikipedia. [Purists, please forgive “Wikipedia” as synonym for Wikimedia, Wikispecies, Wikidata…). Ten years ago I wrote in support of WP (recorded in http://www.theguardian.com/media/2009/apr/05/digital-media-referenceandlanguages ):
The bit of Wikipedia that I wrote is correct.
That was offered in support of Wikipedia – its process , its people and its content. (In Wikipedia itself I would never use “I” , but “we”, but for the arrogant academics it gets the message across). I’ll now revise it:
For facts in physical and biological science I trust Wikipedia.
Of course WP isn’t perfect. But neither is any other scientific reference. The difference is that Wikipedia:
- builds on other authorities
- is continually updated
Where it is questionable then the community can edit it. If you believe, as I do, that WP is the primary reference work of the Digital Century then the statement “Wikipedia is wrong” is almost meaningless. It’s “we can edit or annotate this WP entry to help the next reader make a better decision”.
We are seeing a deluge of scientific information. This is a good thing, as 80% of science is currently wasted. The conventional solution, disappointingly echoed by Timo Hannay (whom I know well and respect) is that we need a priesthood to decide what is worth reading
“subscription business models at least help to concentrate the minds of publishers on the poor souls trying to keep up with their journals.” [PMR: Nature is the archetypal subscription model, and is owned by Macmillan, who also owns Timo Hannay’s Digital Science]. “The only practical solution is to take a more differentiated approach to publishing the results of research. On one hand funders and employers should encourage scientists to issue smaller numbers of more significant research papers. This could be achieved by placing even greater emphasis on the impact of a researcher’s very best work and less on their aggregate activity.”
In other words the publishers set up an elite priesthood (which they have already) and academics fight to get their best work published. Everything else is lowgrade. This is so utterly against the Digital Enlightenment – where everyone can be involved – that I reject it totally.
I have a very different approach – knock down the ivory towers; dissolve the elitist publishers (the appointment of Kent Anderson to Science Magazine locks us in dystopian stasis).
Instead we must open scholarship to the world. Science is for everyone. The world experts in Binomial names (Latin names) of dinosaurs are 4 years old. They have just as much right to our knowledge as professors and Macmillan.
So the next premise is
Most science can be understood by most human-machine symbiotes.
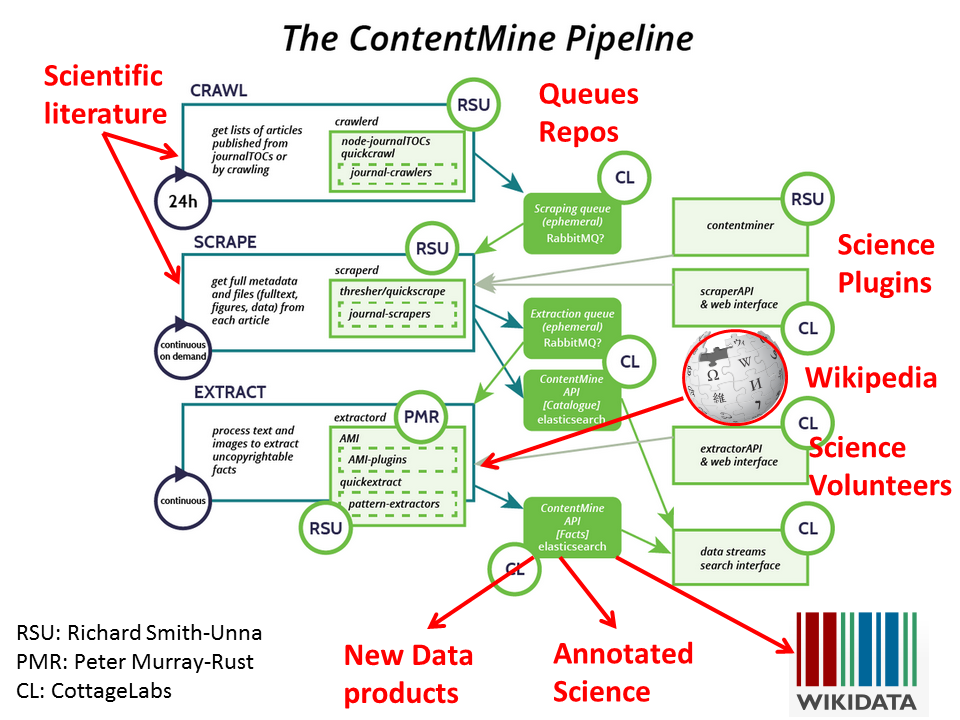
A human-machine scientific symbiote is a social machine consisting of (explained later):
- one (or preferably more) humans
- a discovery mechanism
- a reader-computer
- a knowledgebase
This isn’t science fiction. They exist today in primitive form. A hackathon is a great example of a symbiote – a group of humans hacking on a communal problem and sharing tools and knowledge. They are primitive not because of the technology, but because of our lack of vision and restrictive practices. They have to be built from OPEN components (“free to use, re-use, and redistribute”). So let’s take the components:
-
Humans. These will come from those who think in a Digitally Enlightened way. They need to be open to sharing, putting group above self, of exposing their efforts, of not being frightened, or regarding “failure”as a valuable experience. Unfortunately such humans are beaten down by academia throughout much of the education process, through research; non-collaboration is often a virtue as is conformity. Disregard of the scholarly poor is universal. So either Universities must change or the world outside will change and leave them isolated and irrelevant
-
Discovery. We’ve got used to universal knowledge through Google. But Google isn’t very good for science – it only indexes words, not chemical structures or graphs or identifiers or phylogenetic trees … We must build our own discovery system for science. It’s a simpler task than building a Google – there’s 1.5 million papers a year, add theses and grey literature and it’s perhaps 2 million documents. That’s about 5000 a day or 3 a minute. I can do that on my laptop. (I’m concentrating on documents here – data needs different treatment).
The problem would be largely solved if we had an Open Bibliography of science (basically a list of all published scientific documents). That’s easy to conceive and relatively easy to build.The challenge is sociopolitical – libraries don’t do this any more – they buy rent products from commercial companies – who have their own non-open agendas. So we shall probably have to do this as a volunteer community – largely like Open StreetMap – but there are several ways we can speed it up using the crowd and exhaust data from other processes (such as Open AccessButton and PeerLibrary).
And an index. When we discover a fact we index it. We need vocabularies and identifier systems. IN many subjects these exist and are OPEN but in many more they aren’t – so we have to build them or liberate them. All of this is hard, drawn out sociopolitical work. But when the indexes are built, then they create the scientific search engines of the future. They are nowhere near as large and complex as Google. We citizens can build this if we really want.
3. A machine reader-computer. This is software which reads and processes the document for you. Again it’s not science fiction, just hard work to build. I’ve spent the last 2 years building some of it! and there are others. It’s needed because the technical standard of scholarly publishing is often appalling – almost no-one uses Unicode and standard fonts, which makes PDF awful to read. Diagrams which were created as vector diagrams are trashed to bitmaps (PNGs and even worse JPEGs). This simply destroys science. But, with hard work, we are recovering some of this into semantic form. And while we are doing it we are computing a normalised version. If we have chemical intelligent software (we do!) we compute the best chemical representation. If we have math-aware software (we do) we compute the best version. And we can validate and check for errors and…
4. A knowledge base. The machine can immediately look up any resource – as long as it’s OPEN. We’ve seen an increasing number of Open resources (examples in chemistry are Pubchem (NIH) and ChEBI and ChEMBL (EBI)) .
And of course Wikipedia. The quality of chemistry is very good. I’d trust any entry with a significant history and number of edits to be 99% correct in its infobox (facts).
So our knowledgebase is available for validation, computation and much else. What’s the mass of 0.1 mole of NaCl? Look up WP infobox and the machine can compute the answer. That means that the machine can annotate most of the facts in the document – we’re going to examine this in Friday.
What’s Panthera leo? I didn’t know, but WP does. It’s http://en.wikipedia.org/wiki/Lion. So WP starts to make a scientific paper immediately understandable. I’d guess that a paper has hundreds of facts – we shall find out shortly.
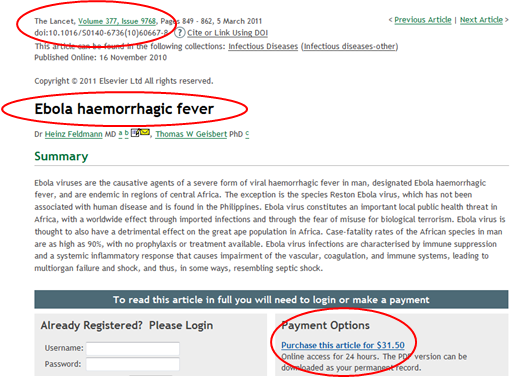
But, alas, the STM publishers are trying to stop us doing this. They want to control it. They want to licence the process. Licence means control, not liberation.
But, in the UK, we can ignore the STM publisher lobbyists. Hargreaves allows us to mine papers for factual content without permission.
And Ross Mounce and I have started this. With papers on bacteria. We can extract tens of thousands of binomial names for bacteria.
But where can we find out what these names mean?
maybe you can suggest somewhere… 🙂