It’s a year since I started TheContentMine (contentmine.org) – a project funded by the Shuttleworth Foundation. In ContentMine we intend to extract all the world’s scientific and medical facts from the scholarly literature and make them available to everyone under permissive Open licences. We have been so busy – writing code, lobbying politically, building the team, designing the system, giving workshops, creating content, writing tutorials, etc. that I haven’t had time to blog.
This week we launched, without fanfare, at a workshop sponsored by Robert Kiley of the Wellcome Trust:

[RK presented with an AMI, the mascot of TheContentMine]
Robert (and WT) have been magnificent in supporting ContentMining. He has advocated, organised, corralled, pushed, challenged over many years. The success of the workshop owes a great deal to him.
On Monday and Tuesday (2015-04-13/14) we ran a 2day workshop – training , hacking and advocacy/policy. We advertised the workshop, primarily for Early Career Researchers and were overwhelmed – FOUR TIMES oversubscribed [1]. Jenny Molloy organised the days, roughly as follows:
- Day1
- tutorials and simple hands on about technology
- aspects of policy and protocols
- planning projects
- Day2
- hacking projects for 6 hours
- 2-hour policy/advocacy session with key UK and EU attendees.
It worked very well and showed that ContentMine is now viable in many areas:
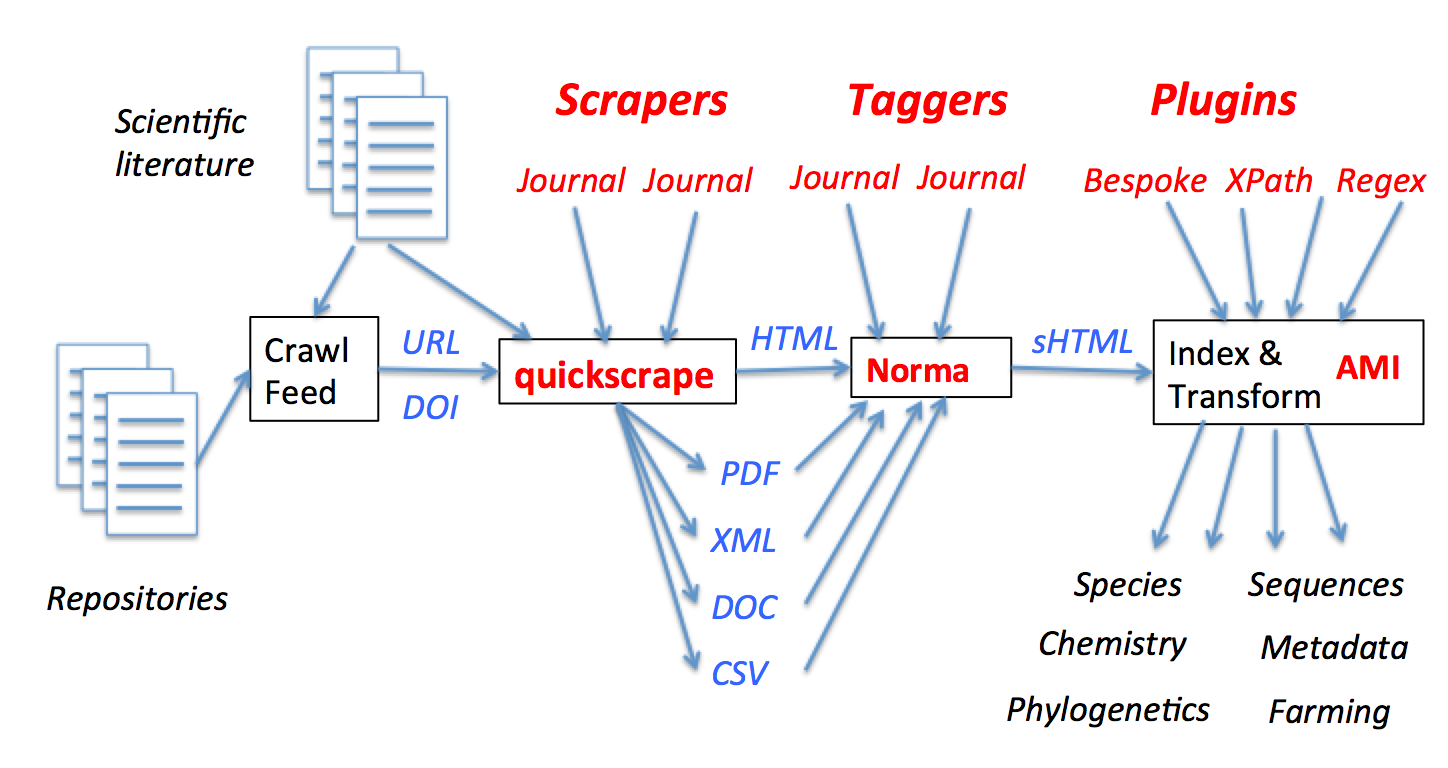
- We have unique software that has a completely new approach to searching scientific and medical literature.
- We have an infrastructure that allows automatic processing of the literature through CRAWLing, SCRAPE-ing, NORMAlising and MINING (AMI).

- We have a back-end/server CATalogue (contracted through CottageLabs) which has ingested and analysed a million articles.
- We have novel search interfaces and display of results.
- We have established that THE RIGHT TO READ IS THE RIGHT TO MINE. in the UK
- We have built a team, and shown how to build communities.
- We have tested training sessions that can be used to train trainers and spread the word.
- And we are credible at the policy level.

[Part of the policy session]
We are delighted that a dozen funders, policy makers, etc came. They included JISC, IPO, LIBER, RLUK, RCUK, HEFCE, CUL, WT, BIS, UbiquityPress, NatureNews. The discussion took for granted that ContentMining is critically important and addressed how it could be suported and encouraged.
My slides for the policy session are at http://www.slideshare.net/petermurrayrust/content-mining-at-wellcome-trust.
I will blog more details later and show more pictures and so will Graham McDawg Steel. But the highlight for me was the speed and effciency of the Early Career Researchers in adopting, using, modifying and promoting the system. They came mainly from bioscience, /medical and ranged from UNIX geeks to those who hadn’t seen a commandline. In their projects they were able to make the CM software work for them and extract facts from the literature. One group wrote additional processing software, another created a novel display with D3.
Best of all they said they’d be happy to learn how to run a workshop and take the ideas and software (which is completely Open Apache2/CC BY/CC0) to their communities.
NOTE: Hargreaves allows UK researchers to mine ANYTHING (that they have legal right to read) for non-commercial use. The publishers cannot stop them, either by technical means or contracts with libraries.
This should make the UK the content-mining capital of the world. Please join us!


")