TL;DR. WE outline the tools and pipeline which ContentMine will show on Sunday at Force2015. They are very general and accessible to everyone….
ContentMine technology and community is maturing quickly. We’ve just had a wonderful three days in Berlin with Johnny West a co-Shuttleowrth Fellow. Johnny runs http://openoil.net/ – a project to find public information about the extractive industries (oil/gas, mining). Technically his tasks and ours are very similar – the information is there but hard to find and locked in legacy formats. So at the last Shuttleworth gathering we suggested we should have a hack/workshop to see how we could help each other.
I thought this would initially be about OCR, but it’s actually turned out that our architecture for text analysis and searching is exactly what Openoil needs. By using regexes on HTML (or PDF-converted-to-HTML) we can find company names and relations, aspects of contracts etc. The immediate point is that ContentMine can be used out-of-the-box for a wider range of information tasks.
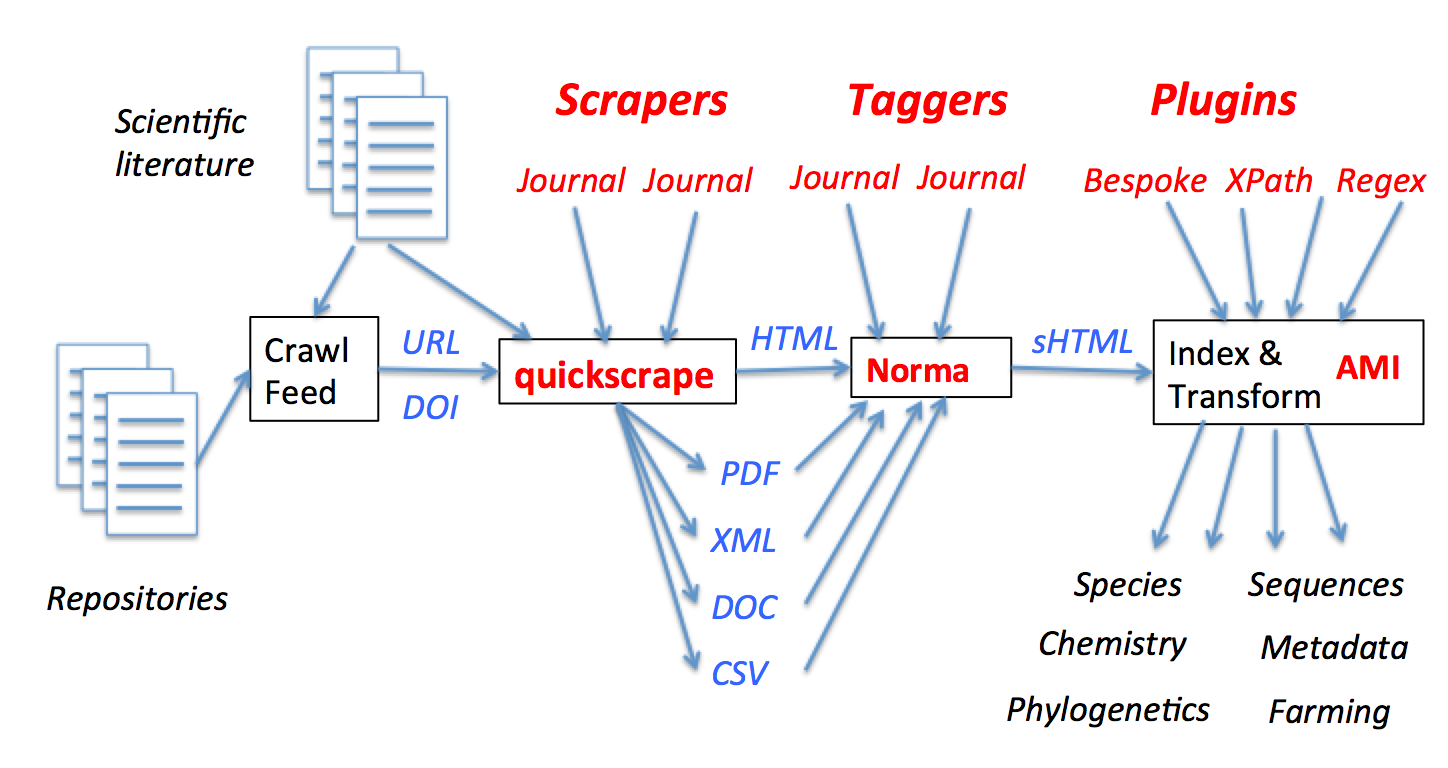
- We start with a collection of documents. Our mainstream activity will be all papers published in a day – somewhere between 2000 – and 3000 (no one quite knows). We need a list of those and there are several sources such as CrossRef or JournalToCs. We may also use publishers’ feeds. The list is usually a list of references – DOIs or URLs which we use in the scraping. But we can also use other sources such as Repositories. (We’d love to find people at Force2015 who would like their repositories searched and indexed – including for thsese (which are currently very badly indexed indeed)). But ContentMine can also be used on personally collections such as hard drives.
- The links are then fed to Richard-Smith-Unna’s quickscrape which can determine all the documents associated with a publication (PDF text, HTML text, XML, supplementary files, images, DOCX, etc.). This needs volunteers to write scrapers but quite a lot of this has already been done. A scraper for a journal can often be written in 30 minutes and there’s no special programming required. This introduces the idea of community. Because ContentMine is Open and kept so the contributions will remain part of the community. We’re looking for community and this is “us” , not “we”-and-“you”. And the community has already started with Rory Aaronson (also Shuttleworth Fellow) starting a sub-project on agriculture (https://openfarm.cc/). We’re going to find all papers that contain farming terms and extracts the FACTs.
The result of scraping is a collection of files. They’re messy and irregular – some articles have only a PDF, others have tens of figures and tables. Many are difficult to read. We are going to scrape these and make them usable. - The next stage is normalization (Norma). The result of Norma’s processing is tagged, structured, HTML – or “scholarly HTML” (http://scholarlyhtml.org/) which a group of us designed 3 years ago. At that time we were thinking of authoring, but because proper scholarship closes the information loop, it’s also an output.
Yes, Scholarly HTML is a universal approach to publishing. Because HTML can carry any general structure, and because it can host foreign namespaces (MathML, CML), and because it has semantic graphics (SVG) and because it has tables and list and because it manages figures and links, it has everything. So Norma will turn everything into sHTML/SVG/PNG.
That’s a massive step forward. It means we have a single simple tested supported format for everything scholarly.
Norma has to do some tricky stuff. PDF has no structure and much raw HTML is badly structured. So we have to use sections for different parts and roles in the document (abstract, introduction, … references, licence…) That means we can restrict the analysis to just one or a few parts of the article (“tagging”). that’s a huge win for precision , speed and usability. A paper about E. coli infection (“Introduction” or “Discussion”) is very different from one that uses E. coli as a tool for cloning (“Materials”). - So we now have normalized sHTML. AMI provides a wide and communty-fuelled set of services to analyze and process this. There are at least three distiint tasks: {a} indexing, (Information retrieval, or classification) where we want to know what sort of a paper it is and find it later (b) information extraction, where we pull out chunks of Facts from the paper (e.g. all the chemical reactions) and (c) transformation, where we create something new out of one or papers – for example calculating the physical properties of materilas from the chemical composition.
AMI does this though a plugin architecture. These can be very sophisticated , such as OSCAR and Chemicaltagger which recognise and interpret chemical names and phrases and are large Java programs in their own right. Or Phylotree which interprets pixel diagrams and turns them into semantic NexML trees. These took years. But at the other end we can search text for concepts using reguar expressions and our Berlin and OpenFarm experience shows that people can learn these in 30 minutes!
In summary, then, we are changing the way that people will search for scientific information, and changing the power balance. Currently people wait passively for large organizations to create push-button technology. If it does what you want fine (perhaps, if you don’t mind snoop-and-control) ; if it doesn’t, you;re hosed. With ContentMine YOU == WE decide what we want to do, and then just do it.
We/you need y/our involvement in autonomous communities.
Join us on Sunday. It’s all free and Open.
It will range from very straightforward (using our website) to running your own applications in a downloadable virtual machine which you control. No programming experience required but bring a lively mind. It will help if we know how many are coming and if you download the virtual machine beforehand, jsut to check it works. easy, but takes a bit of time to download 1,8 GB.
H
Pingback: FORCE2015 Workshop: How ContentMine works for you and what you can bring – ContentMine