We are delighted that Craig James has suggested making the molecular format SMILES an Open activity. Egin Willighagen writes:
08:03 28/09/2007,Craig James wants to make SMILES an open standard, and this has been received with much enthusiasm. SMILES (Simplified molecular input line entry specification) is a de facto standard in chemoinformatics, but the specification is not overly clear, which Craig wants to address. The draft is CC-licensed and will be discussed on the new Blue Obelisk blueobelisk-smiles mailing list.Illustrative is my confusion about the sp2 hybridized atoms, which use lower case element symbols in SMILES. Very often this is seen as indicating aromaticity. I have written up the arguments supporting both views in the CDK wiki. I held the position that lower case elements indicated sp2 hybridization, and the CDK SMILES parser was converted accordingly some years ago. A recent discussion, however, stirred up the discussion once more (which led to the aforementioned wiki page).You can imagine my excitement when I looked up the meaning in the new draft. It states: The formal meaning of a lowercase “aromatic” element in a SMILES string is that the atom is in the sp2 electronic state. When generating a normalized SMILES, all sp2 atoms are written using a lowercase first character of the atomic symbol. When parsing a SMILES, a parser must note the sp2 designation of each atom on input, then when the parsing is complete, the SMILES software must verify that electrons can be assigned without violating the valence rules, consistent with the sp2 markings, the specified or implied hydrogens, external bonds, and charges on the atoms..
PMR: This is excellent. The problem with specifications is that it is VERY difficult to describe them so that independent groups can interpret them consistently. I spent some years helping with the XML effort and apparently simple ideas could cause huge debates. (e.g. namespaces…) It’s well known that some constructs in computer languages, such as
int i = 6;
int j = i++ * i++;
i = i++;
cause enormous confusion. What are the results? (Try to work it out, then try it out and then find the “right answer” (your compiler may surprise you) [*].
Back to chemistry. Almost all formats have been proprietary. That means that there is unlikely to be much useful interactive public help from the originators, and the only check is likely to be a binary executable. When I joined the pharma industry and started trying to get some standards, one software company threatened to sue anyone who published their molecular file formats. It’s slightly better now, but IMO the responsibility for the current appalling situation lies with the pharma industry which has had no effective interest is standardising anything and is now paying the price. (It can only survive by using information, and until it makes this standard and largely free it won’t).
That’s a major reason for developing CML (Chemical Markup Language). CML is open, and uses open standards (XML). It’s much larger than SMILES, and there are places where it is defined less well than we would like, but at least it’s open and that can happen.
SMILES is very widely used. Creating an open standard will take more effort than might appear. The “aromatic” or “lower case” concept is extremely difficult to define. I don’t understand the definition:
The formal meaning of a lowercase “aromatic” element in a SMILES string is that the atom is in the sp2 electronic state.
I don’t believe that SMILES has anything to do with electronic states and I think it should simply be a means for counting atoms, formal bonds and electrons. Is there a difference between Cn(C)C and CN(C)C ? The first represents a planar transition state of trimethylamine, the second a pyramidal ground state.
But the positive point is that I have the chance to make this view and other the chance to support it, modify it or challenge it. Just like Wikipedia, the Blue Obelisk uses the court of public opinion. And we have the exciting position that a “Web 2.0” community is now about to lead the chemoinformatics world.
Maybe the pharma industry will take us seriously. And, wonder of wonders, might actually come into the open, say so, and offer some support.
[*] actually both are undefined and may give different answers







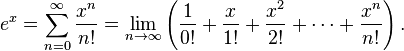



September 24th, 2007 at 9:27 pm ePeter,
I have to take exception to some of your claims. The chemical formula drawing is not the only way of communicating the compound. In fact there are really much better ways of doing this, though not necessarily the best for a human to readily read. The InChI or smiles or 3-D coordinates really capture more information in a more reusable and less likely to be error-ridden way (especially the 3-D coordinates). The chemical formula drawing is not even unique, as we have seen in your examples.
Furthermore, Totally Synthetic had many arbitrary decisions to make in how to represent the structure. I have modified this structure in a few simple ways to make this point:
Note that I have changed the orientation of the terminal isopropyl/OH groups and the way the amide connects to ring A. With regard to ring B, the wedges here are actually NOT how it has to be. Note that the carbons of ring B are not stereocenters. The structure is drawn to try to indicate that ring B sort of π-stacks above ring E. This may or may not be true. Furthermore, the oxygen of the ring could in fact be pointing backwards. In my representation, I decided not to indicate any of this 3-D relationship.
Now I am not claiming that my structure is better than the original. My claim, however, is that Totally Synthetic made some creative decisions in making this presentation, and thus it should be protected.