At contentmine.org we have been working hard to create a platform for extracting facts from the literature. It’s been great to create a team – CottageLabs (CL) and I have worked together for over 5 years and they know better than me what needs to be built. Richard (RSU) is more recent but is a wonderful combination of scientist, hacker and generator of community.
Community is key to ContentMine. This will succeed because we are a community. We aren’t a startup that does a bit for free and then sells out to FooPLC or BarCorp and loses vision and control. We all passionately believe in community ownership and sharing. Exactly where we end up will depend on you as well as us. At present the future might look like OpenStreetMap, but it could also look like SoftWareCarpentry or Zooniverse. Or even the Blue Obelisk.
You cannot easily ask volunteers to build infrastructure. Infrastructure is boring, hard work, relatively unrewarding and has to be built to high standards. So we are very grateful to Shuttleworth for funding this. When it’s prototyped, with a clear development path, the community will start to get involved.
And that’s started with quickscrape. The Mozilla science sprint created a nucleus of quickscrape hackers. This proved we (or rather Richard!) had built a great platform that people could build one and create per-journal and per-publishers scrapers.
So here’s our system. Don’t try to understand all of it in detail – I’ll give a high-level overview.
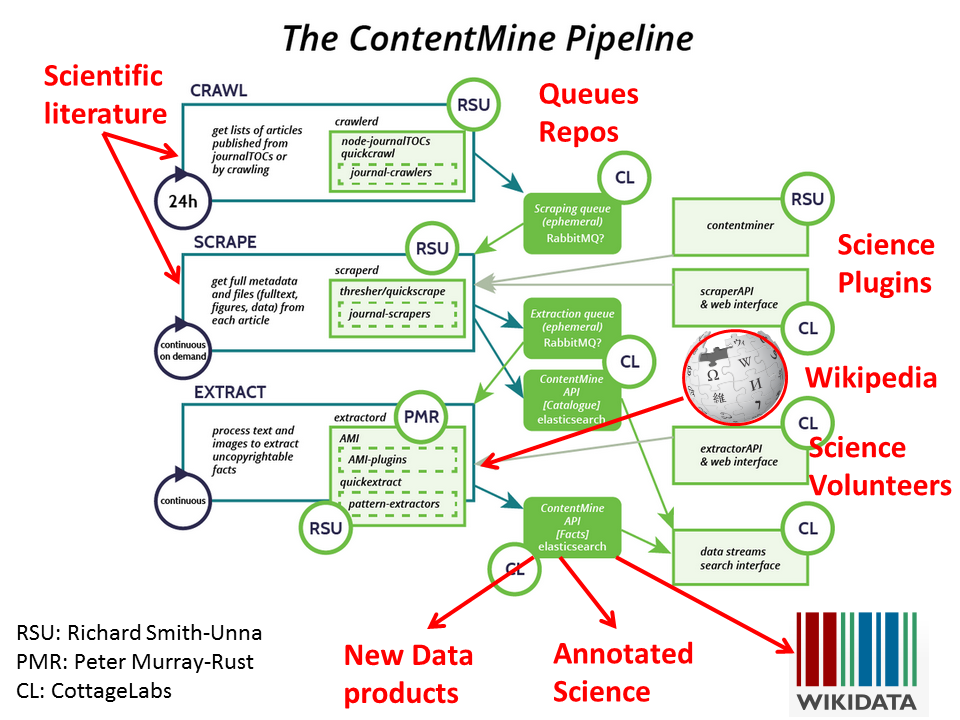
CRAWL: we generate a feed of some or all of the scientific literature. Possible sources are JournalToCs, CrossRef, doing it ourselves, gathering exhaust fragments. We’d be happy not to do it if there are stable, guaranteed sources. The result of crawling is a stream of DOIs and or bibliographic data passed to a QUEUE to be passed to …
SCRAPE: This extracts the components of the publications – e.g. abstract, fulltext, citations, images, tables, supplemental data, etc. Each publisher (or sometimes each journal) requires a scraper. It’s easy to write these for Richard’s quickscrape platform, which includes the scary Spooky, Phantom and Headless. A scraper takes between 30 minutes and and 2 hours so it’s great for a spare evening. The scraped components are passed to the next queue …
EXTRACT. These are plugins which extract science from the components. Each scientific disciplines requires a different plugin. Some are simple and can be created either by lookup against Wikipedia or other open resources; or by creating regular expressions (not as scary as they sound). Others, such as those interpreting chemical structure diagrams or phylogenetics trees have taken more effort (but we’ve written some of them).
The results can be used in many ways. They include:
- new terms and data which can go direct;y into Wikidata – we’ve spent time at Wikimania exploring this. Since facts are uncopyrightable we can take them from any publication whether or not it’s #openaccess
- annotation of the fulltext. This can be legally done on openaccess text.
- new derivatives of the facts – mixing them, recoputing them, doing simulations and much more
Currently people are starting to help writing scrapers and if you are keen let us kn0w on the mailing list https://groups.google.com/forum/#!forum/contentmine-community
This is incredible, Peter. I look forward to hacking and volunteering to help this mission to advance science and society, at large.
Pingback: How contentmine.org will extract 100 million scientific facts – ContentMine