CKAN was pioneered by the Open Knowledge Foundation as an Open Source tool to make government and related data more easily available. Governments love it, because it’s good and it’s free and it’s open. But why would we use it for science?
Because it’s good and it’s free and it’s open.
The Comprehensive Knowledge Archive Network (CKAN) is a web-based
open source data management system for the storage and distribution of data, such as spreadsheets and the contents of databases. It is inspired by the package management capabilities common to open source operating systems like Linux, and is intended to be the “apt-get of Debian for data”.[2]
Its code base is maintained by the Open Knowledge Foundation. The system is used both as a public platform on thedatahub.org[3] and in various government data catalogues, such as the UK’s data.gov.uk,[4] the Dutch National Data Register, the United States government’s “data.gov 2.0”[5] and the Australian government’s “Gov 2.0”.[6]
SOUTH Australian state government has also joined the ranks of many jurisdictions world-wide in making government data freely available to the public on CKAN platform[7]
Well if Barrack Obama uses it, it must be good. But how to use it?
You can use it in private , without permission,of course (that’s what Open Source means). But the OKFN runs a public server and Chuff (@okfn_okapi) spoke very nicely to Mark Wainwright who set up an Organization: November25). Chuff asked for petermr to be an admin.
It’s very easy. You just enter some metadata and tip the data in. And here what it looks like
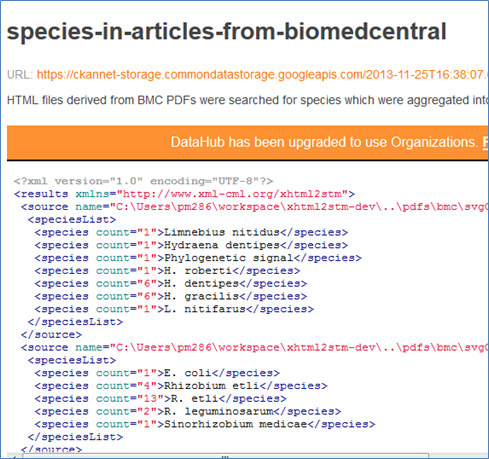
This is the prototype. The animals know that Hydraena dentipes and H. dentipes are the same, so they’ll replace all H. with Hydraena. (probably before the data gets in). There’s between 5 and 20 species per paper full-text, but often far more in the diagrams and tables (their speciality).
So soon they will have the best collection of published animals in the scientific literature…
.. and the best plants, and bacteria and …
It’s easy to add metadata to CKAN, and we’ll do it by machine. That means we can search the literature by species.
And soon (maybe Wednesday) by:
- Chemistry
- Sequences
- Phylogenetic trees
- Identifiers.
- And whatever YOU can contribute (it’s easy)
So if this excites you – and it should – please let us know.