A lot of our discussion in Jailbreaking related to technical issues, and this is a – hopefully readable – overview.
PDF is a page description format (does anyone use pages any more? other than publishers and letter writers?) which is designed for sighted humans. At its most basic it transmits a purely visual image of information, which may simply be a bitmap (e.g. a scanned document). That’s currently beyond our ability to automate (but we shall ultimately crack it). More usually it consists of glyphs (http://en.wikipedia.org/wiki/Glyph the visual representation of character). All the following are glyphs for the character “a”.
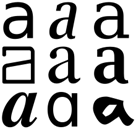
The minimum that a PDF has to do is to transmit one of these 9 chunks. It can do that by painting black dots (pixels) onto the screen. Humans can make sense of this (they get taught to read but machines can’t. So it really helps when the publisher adds the codepoint for a character. There’s a standard for this – it’s called Unicode and everyone uses it. Correction: MOST people, but NOT scholarly publishers. Many publishers don’t include codepoints at all but transmit the image of the glyph (this is sometimes a bitmap, sometimes a set of strokes (vector/outline fonts)). Here’s a bitmap representation the first “a”.
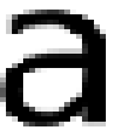
You can see it’s made of a few hundred pixels (squares). The computer ONLY knows these are squares. It doesn’t know they are an “a”. We shall crack this in the next few months – it’s called Optical Character Recognition OCR and usually done by machine learning – we’ll pool our resources on this. Most characters in figures are probably bitmapped glyphs, but some are vectors.
In the main text characters SHOULD be represented by a codepoint – “a” is Unicode codepoint 97. (Note that “A” is different and codepoint 65 – I’ll use decimal values). So every publishers represent “a” by 97?
Of course not. Publishers PDFs are awful and don’t adhere to standards. That’s a really awful problem. Moreover some publishers use 97 to mean http://en.wikipedia.org/wiki/Alpha . Why?? because in some systems there is a symbol font and it only has Greek characters and they use the same numbers.
So why don’t publishers fix this? It’s because (a) they don’t care and (b) they can extract more money from academia for fixing it. They probably have the correct codepoint in their XML but they don’t let us have this as they want to charge us extra to read it. (That’s another blog post). Because most publishers use the same typesetters these problems are endemic in the industry. Here’s an example. I’m using BioMedCentral examples because they are Open. I have high praise for BMC but not for their technical processing. (BTW I couldn’t show any of this from Closed publishers as I’d probably be sued).

How many characters are there in this? Unless you read the PDF you don’t know. The “BMC Microbiology” LOGO is actually a set of graphics strokes and there is no indication it is actually meaningful text. But I want to concentrate on the “lambda” in the title. Here is AMI2’s extracted SVG/XML (I have included the preceding “e” of “bacteriophage”)
<text stroke=”none” fill=”#000000″ svgx:fontName=”AdvOT46dcae81″
svgx:width=”500.0″ x=”182.691″ y=”165.703″ font-size=”23.305″
font-weight=”normal”>e</text>
<text stroke=”none” fill=”#000000″ svgx:fontName=”AdvTT3f84ef53″
svgx:width=”0.0″ x=”201.703″ y=”165.703″ font-size=”23.305″
font-weight=”normal”>
l</text>
Note there is NO explicit space. We have work it out from the coordinates (182.7 + 0.5*23 << 201.7). But the character 108 is a “l” (ell) and so an automatic conversion system creates

This is wrong and unacceptable and potentially highly dangerous – a MU would be convtered to an “EM”, so Micrograms could be converted to Milligrams.
All the systems we looked at yesterday made this mistake except #AMI2. So almost all scientific content mining systems will extract incorrect information unless they can correct for this. And there are three ways of doing this:
- Insisting publishers use Unicode. No hope in hell of that. Publishers (BMC and other OA publishers excluded) in general want to make it as hard as possible to interpret PDFs. So nonstandard PDFs are a sort of DRM. (BTW it would cost a few cents per paper to convert to Unicode – that could be afforded out of the 5500 USD they charge us).
- Translating the glyphs into Unicode. We are going to have to do this anyway, but it will take a little while.
- Create lookups for each font. So I have had to create a translation table for the non-standard font AdvTT3f84ef53 which AFAIK no one other than BMC uses and isn’t documented anywhere. But I will be partially automating this soon and it’s a finite if soul-destroying task
So AMI2 is able to get:

With the underlying representation of lambda as Unicode 955:
So AMI2 is happy to contribute her translation tables to the Open Jalibreaking community. She’d also like people to contribute, maybe through some #crowdcrafting. It’s pointless for anyone else to do this unless they want to build a standalone competitive system. Because it’s Open they can take AMI2 as long as they acknowledge it in their software. Any system that hopes to do maths is almost certainly going to have to use a translator or OCR.
So glyph processing is the first and essential part of Jailbreaking the PDF.
I don’t often defend publishers but in this case (and I know that this isn’t generally the case) BMC do provide a machine readable version (http://www.biomedcentral.com/content/download/xml/1471-2180-11-174.xml). This could be used for training AMI2?
I guess the ideal situation is that wherever a licence is applied that enables re-use, a re-usable version of the relevant content exists! (i.e. not PDF…).
Thanks Mark,
As I said I have reasonable praise for BMC in some fields. But in this case they actually have the correct character in the XML (λ) so WHY create a different one in an unstandard undocumented font for the PDF. Is the XML being used to generate the PDF? In which case why not use a Unicode-compliant font rather than a non-Unicode font. (I have had private comfirmation of the horror of this from another expert who says it’s almost impossible to recreate this algorithmically).
And the XML is not the complete document. There are no figures, any figures in EPS are destroyed to PNGs, etc. I do not yet believe the XML from most publishers is equivalent to the PDF or necessarily og high quality.
And remember that when I publish with them I have to pay them to do this.
Agree completely. I guess they would say PDF for humans (i.e. no intention to make it ‘hackable’), XML for machines. The figures referenced by the XML are actually retrievable (e.g. Fig 1 is http://www.biomedcentral.com/content/download/figures/1471-2180-11-174-1) but obviously only bitmaps.
And BMC use a non-standard XML schema, unlike e.g. PeerJ who use JATS:
http://blog.peerj.com/post/47445954946/pubmed-central-pubmed-and-scopus-indexing-peerj
Mark.