In the previous post AMI2 showed the need and the problems of dealing with fonts. In summary, if all fonts carry Unicode codePoints it’s trivial to extract the codepoints and assert they are Unicode. Since SVG uses Unicode by default, passing the codes will mean SVGPlus can both “understand” them and render them. Unfortunately many PDF files in the STM literature are difficult or ambiguous for AMI2 to understand.
Remember that AMI2 has no emotions or social judgment. She does not understand “bad”, “awful”. She uses words like “complicated”, “fragile”, “ambiguous”, “impossible”. If they are difficult it’s more work, but possible. If they are ambiguous, AMI2 can sometimes be given rules, heuristics or even probabilistic methods. If they are impossible, AMI2 says she can’t give an answer.
AMI2-PDF2SVG has now had a look at the following PDF sources:
- Manuscripts on Arxiv. These are authors’ preprints, although in many cases they don’t differ significantly from the publisher’s version of record. They are probably produced by practising scientists using LaTeX or Word. Most authors will have already created several previous documents so they will understand how to do it.
- Theses from Institutional repositories. These are also mainly authored by graduate students using Word or LaTeX (though we don’t know). They may be the first documents students author, though many will have published one or more scholarly articles.
- Published PDFs from STM publishers. PMR is trying to find “Open Access” examples so they can be quoted from. We don’t know how these are authored. However PMR’s best guess is that the publishers receives the author’s manuscript in LaTeX or word, annotates or corrects it in some way, and sends it off to third party typesetting companies. (If any publisher wishes to correct this, please do). There is some evidence from the fonts used that some typesetters deal with more than one publisher – and I got a list of three from someone who knew the industry.
AMI2 is particularly concerned with “high” codepoints – i.e. above 255. These are used for symbols (e.g. Greek letters, maths symbols, graphical symbols (circles, squares, etc)) and certain punctuation (e.g. smart quotes and dashes). It really matters getting these right.
AMI2’s initial findings (from a very small sample) are:
- Arxiv manuscripts were easy to process and had few ambiguities and most of the symbols are correctly rendered. It appears that Unicode is commonly used. Math equations (especially from Word) may be problematic.
- Theses are fairly similar (except where they include publishers’ PDFs).
- STM publishers PDFs are very variable. Some are easy but many are complex, ambiguous and not infrequently impossible at this stage
The problems across all PDFs are:
- Codepoints are not Unicode and the encoding is unknown. It has to be guessed from the Font
- Many PDFonts do not have FontDescriptors. The FontDescriptor is the standard way of finding whether a character is italic, symbol, etc. and finding the FontFamily
- Some Fonts do not even have Fontnames. Others have font names that are Opaque (e.g. AdvP4C4E51).
In the problem cases the PDF only displays because the Glyphs are actually included. It’s possible in PDFBox to ask for the glyphs and get bitmaps or outline (scalable) fonts. That’s OK for sighted humans, but no one else.
So we have the following subproblems:
- Map an undocumented codepoint in an undocumented font to Unicode.
- Interpret a glyph bitmap/outline as a Unicode codepoint.
How do we solve this? We use the wonderful resource that is StackOverflow. Nearly 4 million questions have been asked on SO and most have had highly competent answers. So I asked SO about translating Mathematical-Pi-One points (e.g. “H11001”) to Unicode:
http://stackoverflow.com/questions/13188587/conversion-of-mathematicalpi-symbol-names-to-unicode
Conversion of MathematicalPI symbol names to Unicode
|
up vote 8 down vote favorite 2 |
I am processing PDF files and wish to convert characters to Unicode as far as possible. The MathematicalPI family of character sets appear to use their own symbol names (e.g. “H11001”). By exploration I have constructed a table (for MathematicalPI-One) like: Can anyone point me to an existing translation table like this (ideally for all MathematicalPI sets). [I don’t want a graphical display of glyphs as that means each has to be looked up as a Unicode equivalent.] |
After 2 days no answers. This is unusual – you normally get answers within an hour or even minutes. So it’s an obscure question with possibly no clear answer. But on SO you earn points for good questions and answers. Because I had 8500 points, I could offer a “bounty”. This means that I give others points to answer my question. And I got answers. They are good, and are as good as possible as there is no Open translation table. But after a discussion it appeared that Adobe had published a table of MathPi code points and the glyphs. Here’s a snippet:
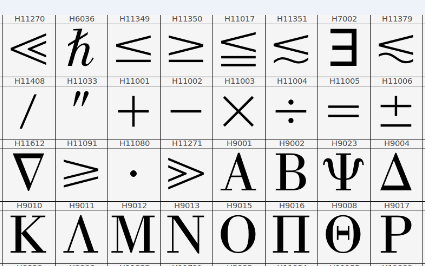
So “H11011” looks like a plus and quacks like a plus (i.e. it is found where a plus sign makes sense). We can therefore write H11001 => U+002B. But what about H11017, for example. How do we find the Unicode point out of 100,000 possibilities?
That’s where one of the answers was so valuable. They’d discovered “shapecatcher” – an excellent tool created by Benjamin Milde. Here’s his thesis

And he has now developed shapecatcher using this technology. Shapecatcher has a large part of the Unicode character set along with (open) glyphs and he has developed the tool to map a bitmap onto possible characters, reporting the probability for each. Let’s try it on H11017:
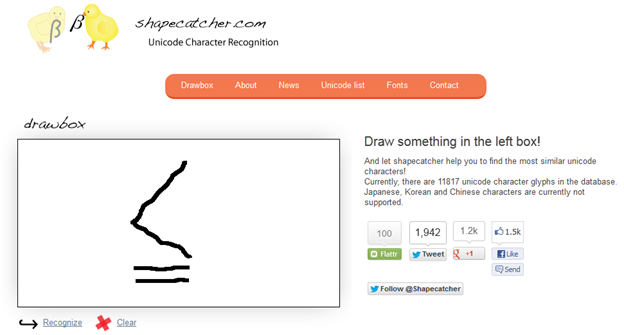
And here’s my best effort (I’m in Perth airport without a mouse so it’s straggly)
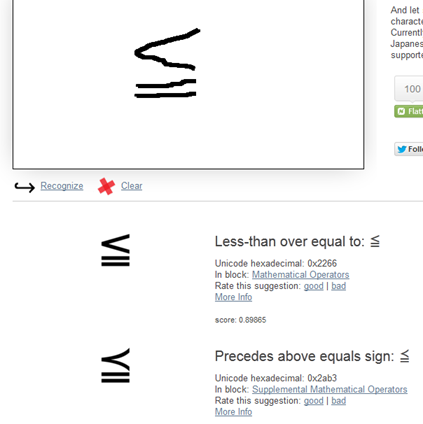
Brilliant. It has a clear Unicode point and my wobbly picture got it right.
I think Benjamin’s technology has a great deal to offer.
Sand it’s an excellent example of why making theses Open is a Good Idea.