I posted yesterday about an article in PLoS ONE where I criticized the author/editor/publisher for destroying semantic data. /pmr/2011/07/16/how-to-share-data-and-how-not-to/ It has generated 11 replies and you should read them before this post so as to get all points of view.
It turns out it is the PLoS system that carries out this transformation. There are several vigorous defences of PLoS so I will try to be objective.
The first, and IMO fundamental, concern is that this is a system which (however good or bad) is developed by the publisher and thrust on authors, reviewers and readers/re-users. That is true of almost all publishers and it is one of the MOTSIs – that we have handed over to publishers the representation of our knowledge. In the print era this might have been acceptable but in the century of the semantic web I find it inexcusable. PLoS is no worse than others and because it’s Open it exposes its XML (closed publishers do not, of course do this).
What I have objected to is that the information submitted by the authors is transformed (in my case without my knowledge or consent) to a dumbed down version. Here is an example (from our paper on text-mining http://www.plosone.org/article/info%3Adoi%2F10.1371%2Fjournal.pone.0020181#pone-0020181-t001 );
What we submitted: (I don’t like submitting images but sometimes it is the only way
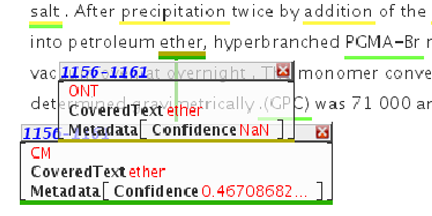
It’s quite readable to young sighted humans. Now here is the “Powerpoint-friendly” version:

Cameron (below) argues that most “readers” will want to display the included material as a slideshow. But this is systematic destruction of the information (by reducing the resolution when it wasn’t necessary).
I’ll take Cameron and others replies and comment – as objectively as I can. BTW I use “PLoS” because we can expect some answers, but the arguments below are generic (they may differ in detail from publisher to publisher).
>>> FWIW the review process is done entirely via PDFs so it is not straightforward to tell what the native format of any part of the paper is for the reviewer. I would agree that this is bad but its consistent with most of the journal systems I’ve worked with. Obviously this makes reviewing for data formats difficult or impossible but what’s probably worse is that it discourages you from asking the question. In some ways the BMC system is better in this respect because the files are there in front of you with big icons saying what the format is.
PMR>> exactly so. The reviewers have to accept what the journal thrusts on them. It’s impossible for them to get close to the data. So this is a publisher-enforced policy that hinders the publication of semantic information. Not what the data *is* but what it looks like. How many reviewers might like to cut and paste (or better) the authors’ data into their own data analysis tool? This is true for most publishers – they send reviewers the PDFs because it’s easier for the publishers. IMO this leads to poorer science because it’s impossible for the reviewers to have access to the data (even if submitted)
>>>However I think I disagree with Peter about the destruction element here. The html version of the paper is explicitly designed in the PLoS system for human reading (admittedly by sighted people). I actually find that floating window and the ability to click through figures very useful and I’d imagine that it makes that process simple if everything, figures and tables, are the same format. Given that the tabular data is available in the XML [PMR I’ll address that later], which is where you’d go to dig out data, I don’t think its a question of destruction but of differing priorities.
PMR>> OK, who determines the priorities. Not the authors, although they pay PLoS for the publication. The reviewers?? The editors?? Or PLoS management.
>>>The person who wants to cut and paste the numbers from the table is going to be annoyed but the person who wants to grab the figure and drop it into a presentation is going to be happy. And I suspect the latter may be the more common re-use case.
PMR>> I am surprised. I would have thought that many readers actually want to have access to the data – in data form – on their machine. I don’t spend my time presenting other people’s published material as parts of slide shows, but maybe I am the exception. Where I do I would not drag-n-drop an unreadable Powerpoint friendly table – I would create it is a form where the audience could read the most important bits. Maybe I would have to do some editing and cropping…
>>> The ideal would obviously be to have both, contextually presented depending on what the user (human or machine) wants. PLoS have focussed very hard on making their html rendering attractive to human readers and have as a result pulled into a situation where html downloads are much greater than pdf downloads which I would see as a good thing.
PMR>> I would agree that HTML is far better than PDF and HTML5 is better than HTML and Scholarly HTML should be what we aim for.
>>. The price, with limited resources, is things like this which are suboptimal obviously.
PMR: This I fail to see. If you already have tables marked up in XML it’s trivial, yes really trivial, to convert them to HTML tables. It would take me 30 minutes to write a stylesheet to extract the tables and translate them to HTML (trhey are effectively that already). And putting the links in to the HTML shouldn’t be rocket science
>>>What would a system look like that achieved all of these goals – presenting the easily cut and pasted whole for those who wanted it, plus the cut and pasted data for the humans who want that, plus the marked up data for those who want that? At least there’s a DOI for each element so a content negotiation scheme would in principle be possible. It also re-raises the question of standardising the form in which a paper points to its data on an external service such as Dryad – how should that link be made machine discoverable in a general way?
PMR>> exactly. My concern was that by turning semantic tables into images the publisher(s) give the impression they don’t care about data. BMC (to pick another Open Access publisher) does care about data. So should PLoS
Andy Turner>>> It is easy to find the XML for the table in the article XML
PMR>> yes – and I found it. J It gives no explanation on what it is, how to use it, whether you need special tools, etc.
AT>>>and it has an XLink so there is perhaps really very little to find issue with about this.
PMR>> The Xlink in the XML points to an IMAGE (see mimetype). And that’s what I take issue with.
AT>>> Perhaps the enhancement wanted is to add buttons for XML (small, medium and large) i.e. XML Table Values Only, XML Table with Metadata and context links, XML for the article. Perhaps also there could be a download package for all this as zip, tar.gz etc…
PMR>> Exactly. This would be a big enhancement. And if PLoS and BMC and EGU and IUCr and… (maybe even some closed access publishers) all used the same approach it would solve the problem. Because which reader or re-user wants a different approach to each publisher?
QUESTION. Yes, I can find the XML and – because I understand XML – I can locate the tables and I can write a stylesheet to extract them. But most people can’t. Is there something I’m overlooking? An open set of tools that everyone except me has access to? Or is it actually cutting and pasting each individual field out of the XML?
I wonder how many publishers research their users needs and test how their users actually interact with the journal interface? How do they know “most readers want to display material in a slide show?”
Thanks Laura,
I agree.
Distinguish between “users” (which often means purchasing officers) and “readers” who now don’t really matter.
Hi, I am an avid (rabid) proponent of open data and of open data standards, but I have to say, in this post and the last one, I have a hard time understanding what you are complaining about.
You say it is about the destruction of the semantic content, but I don’t see it. In the example you gave, which seems to be about this figure in particular: http://www.plosone.org/article/slideshow.action?uri=info:doi/10.1371/journal.pone.0020181&imageURI=info:doi/10.1371/journal.pone.0020181.g006, the journal gives several different formats that you can download it in, including “original TIFF”. It seems to me that you cherry-picked the “powerpoint” version to prove your point, because the “original TIFF” version has very nice, high resolution. Anybody could use that high-res version to insert into their powerpoint, of course. And note that all of these methods are meant for human consumption — for machines, they even provide the XML.
Your original post was about the rendering of a summary table as an image in an article. In this post you say that it is really trivial to render the HTML table, but I can tell you from experience that it is not. The way that PLoS decides to render the table for human consumption is designed to give them the best control over the layout of the table in terms of row height and column width — rather than leaving it up to the browser. It really is excrutiatingly hard to get all different types of tables to render well in all different browsers. I agree that it might be nice if they also provided a “download HTML version” on their table window, but that’s just a feature request.
I’d also say that I don’t this is indicative of any issues about the problems of handing “over to publishers the representation of our knowledge”. These kinds of issues will always come up, as long as there is any separation between producers and disseminators of content. And there always will be that separation. You might be different, but the vast majority of scientists and authors are not going to take the time and care to make sure that all of their data is rendered correctly, in all the various permutations of formats and media types. At PMC, I sit in meetings all the time where we have to try to weigh what we think are the needs of our various users, and we use sophisticated ways to try to find out what those are, and I’m sure the folks at PLoS do the same.
Sorry to be critical — I’m a big fan of your blog. But in this case I just don’t see that there’s any real issue here.
Thanks very much Chris,
I understand your points – I think we have somewhat different viewpoints.
Let’s say I prefer the way that (say) BMC publishes XLS while you prefer data summarized in images. If the NLM DTD becomes standard thorughout publishing and if the tools to use it are easily available then I’ll probably shift somewhat.
Best