Typed and scraped into Arcturus
The following recent story in the Times Higher Educational Supplement (the “mainstream” magazine for HE in the UK) shows why we desperately need a clear basis for discussing data. I’ll comment inline, but initially just to make it clear that the fuss and hyperbole is because there is no communal framework for understanding and addressing the problem. Also to remind readers of this blog that the UK has a Freedom Of Information Act (FoI) which allows any citizen to make a request to a public body (government, local government, universities, public research establishments) for information, It is the law, and a reply must be delivered within 20 working days and there are only a few grounds for refusal.
The background is “Climategate” (http://en.wikipedia.org/wiki/Climatic_Research_Unit_email_controversy ) where the FoI was used repeatedly to try to extract data from the CRU at the University of East Anglia (UK). Ultimately there were email leaks and several public enquiries. I shan’t address the facts or the rights and wrongs other than to note that there was a complete lack (failure) of understanding between the requesters of the information (data on climate research) and those from whom it was requested.
My contention is that some of the problem has arisen because we have no framework for understand who has a right to what data when. The use of a legal instrument (FoI) is inappropriate for scientific communication and serves to highlight the work we need to do to create a framework.
The article is http://www.timeshighereducation.co.uk/story.asp?sectioncode=26&storycode=412475&c=2 and I shall quote some of it and some of the comments (I justify everything as fair use/comment).
A ruling that FoI laws require him to share unpublished data has shocked a researcher […] Michael Baillie began analysing the rings in Irish oak trees more than 30 years ago […]
Michael Baillie began analysing the rings in Irish oak trees more than 30 years ago […]
But three decades on, the FoI laws have been used by a science blogger, Douglas Keenan, to obtain data collected by the emeritus professor of palaeoecology at Queen’s University Belfast over the course of a career investigating catastrophic environmental events.
After a three-year battle to get the university to release the data, some of which are yet to be published by the academic himself, Dr Keenan won a ruling from the Information Commissioner in April that said that Queen’s owned the data and must release it.
PMR: The critical aspects here are “some of which are yet to be published by the academic himself” and “a three-year battle” and “Queen’s owned the data”. Whether the science has been published, whether the timescale is appropriate and “who owns the data” are going to be key questions. I haven’t read more than this article – I suspect the Information Commissioner had little precedent to go by and made an appropriate decision in the circumstances. I personally would dispute that Queen’s owned the data (I don’t think data can normally be owned). But this is the essence of exposing the problems.
The precedent has important implications for academics, raising issues similar to those highlighted in last week’s report by Sir Muir Russell into the so-called Climategate affair at the University of East Anglia.
Until now, researchers have published data at the time of their choosing, through the normal academic channels and in the context of the overall objectives of their work.
The decision in the Queen’s case indicates that any interested party can use FoI laws to request any data belonging to a UK university, whether they form part of an academic’s published work or whether they are still raw.
PMR: In the UK much law is by precedent, so if this was a court case this would set a precedent. I don’t know whether the Commissioner’s statements have the same force. But precedents can be overturned by later judgments. I certainly would not regard this as absolute.
Professor Baillie said the Information Commissioner’s ruling demonstrated how ill-equipped universities were to deal with the dilemmas this posed. “I think the problem is that no one has ever defined university data, either for academics like me or for the university as an institution.”
He said his professional relationship with Queen’s had been formed in a less managerial age, one untroubled by modern demands for public accountability.
“There was nothing in our old academic contracts about data and responsibility for data,” he said, adding that ownership of research data had never been discussed.
“As far as we were concerned, it was our data because the issue of who owned them never arose: the data belonged to the people who made the measurements,” he explained.
PMR: All this is true. It is the uncertainty that causes the problem and why we have to address it
This attitude is no longer acceptable, according to the Russell report, which criticised UEA for not being open enough with climate change sceptics who requested information under FoI legislation. It said the university had “failed to recognise not only the significance of statutory requirements (under the FoI Act), but also the risks to the reputation of the university and, indeed, to the credibility of UK climate science”.
PMR: Climategate involved data supporting previous publications and where the timescales were considerable. Many request for data had been made (under FoI) and almost all had been refused. This at least points to a systemic problem over several years which should have been addressed. I don’t think it generalizes.
However, the Information Commissioner’s decision in the Queen’s case raises concerns that third parties could disrupt projects, with FoI requests potentially forcing the early release of data gathered as part of longitudinal research.
PMR: This is a concern but it is manageable if we create the right infrastructure. Timescales for release are now critical.
The Joint Information Systems Committee, which supports the use of IT in UK higher education, has commissioned a consultancy firm to produce guidance on the issue, which is due to be published in September.
“The big lesson is that a lot of the rules governing what people thought were exemptions didn’t stand up to analysis by the Information Commissioner’s office,” said Simon Hodson, programme manager at Jisc.
PMR: Yes. We are delighted to be working with JISC who have funded projects where we are bringing greater Openness to data and procedures.
[Professor Baillie] explained: “An FoI request granted by the commissioner leaves the university on the back foot. It also leaves people like me with loads of data that we are still exploiting on the back foot. Clearly each university needs to have a definite policy on the release of research data.”
PMR: Agreed. And that is why we are trying to help formulate policies.
… and now some reader comments …
-
Dorothy Bishop 16 July, 2010
Data sharing has become standard practice in the field of genetics. Obviously, when this was first raised, researchers were worried about others stelaing a march on them, but guidelines have been developed to protect the interests of researchers, and overall the availability of data on the web seems to be of benefit to both researchers and the general community. See:
http://www.genome.gov/Pages/Research/WellcomeReport0303.pdf
PMR: exactly. Some fields have solved this years ago – it’s important to learn from them.
-
Mary 16 July, 2010
I’m curious to know how this FoI ruling will apply to cases where university researchers such as myself who are industry funded and have non-disclosure agreements in place (as opposed to being funded from government grants or the university itself). Does the FoI act overrule the non-disclosure agreements signed between the university and external (non-govt) funding sources? This has the potential to see industry funding dry up in a flash…
-
Bill Cooke 16 July, 2010
Mary has a point. I possess elite-interview data gathered with a promise of confidentiality. It would be very difficult to share any part of this without compromising confidentiality. In the longer run, interviewees are just likely to say “no” to interview requests, are they not ?
PMR: I would be amazed if this happened, and if it did there would be an appeal which would be won. UK has an element of commonsense in its legal system (perhaps not enough…)
Ellie Dewar 17 July, 2010
Government will need to think very carefully before extending its ‘transparency principles’ to research data. Fields benefiting from open data release are those where data is an end-product of the research – these are an exception not the rule. Making data open takes time and effort. Diverting researchers from work they have been educated at great expense to do, to do something they see as damaging to their own interest, their industry collaborators, and their research goals might not be a great idea. As someone recently said, it is like forcing a sculptor to ‘openly release’ the lump of stone they are working on before it is a sculpture. Leave PIs to decide what to make open and when, at least until they have published.
PMR: premature worry.
-
Shabba 18 July, 2010
The ESRC and MRC expect their PIs to place data in national repositories, and rightly so, this work is done at public expense. In my field, (Health Services Research), research ethics committees rightly restrict access to unanonymized data about people and organizations, but NHS [UK National Health Service] trusts are also required to audit data collection undertaken by universities. We are careful to tell participants in our studies that what they say may be anonymized but that this may not adequately conceal their identity, and further, that anonymization and confidentiality are not the same thing. None of our data is immune from subpoena, and there are many public agencies that can demand to see it (the police and HMRC [HM Revenue and Customs], for example). In this context, FoI is only one possible way in which seemingly private research data is in fact very public. The most important thing is to be forthcoming and sensible about it ~ and definitely not make the bollocks of this kind of thing that happened with the climate resarchers at UEA!
PMR: Yes. We must always be prepared to be accountable and sensible,
-
Chris Rusbridge 19 July, 2010
It’s important to note in this case that the ruling was based on Environmental Information Regulations (EIRs) rather than freedom of Information. Exceptions in EIR are stricter. Also the details of the Information Commissioner’s ruling at http://www.ico.gov.uk/uploadre/documents/decisionnotices/2010/fs_50163282.pdf show that procedural issues were part of the problem. This is not all as bleak as it’s painted!
PMR: Exactly so. (Chris has recently retired from running the UK’s Digital Curation Centre)
-
Rodney Breen 20 July, 2010
In answer to Mary and Bill, the Freedom of Information Act has exemptions to protect data which is collected with a reasonable expectation of confidentiality, and data which is commercially sensitive. Under the Scottish Act, there is specific protection for research data. There is no reason why material for which researchers have legitimate need for protection should need to be disclosed.
PMR: Exactly. The clearer that these issues are made the less likelihood of problems.
-
Douglas J. Keenan 20 July, 2010
I am the Douglas Keenan mentioned in the article. The article’s claim that the ICO decision “indicates that any interested party can use FoI laws to request any data belonging to a UK university, whether they form part of an academic’s published work or whether they are still raw” is false. Indeed, the FoI Act (Section 22) states that information is exempt from request if “the information is held by the public authority with a view to its publication, by the authority or any other person, at some future date”. The real situation is that Baillie has had almost all the data for over 30 years, has published many papers based on the data, is now retired, and yet claims the data as his private property–and the ICO rejected Baillie’s claim. The ICO decision is obviously reasonable, and the article is misleading. There is more about what happened, including detailed documentation, on my web site:
http://www.informath.org/apprise/a3900.htm
.
-
Mike Baillie 23 July, 2010
Just to provide a little closure on the issue of Irish tree-ring data and Freedom of Information I would like to point out a flaw in Mr Keenan’s logic (20 July, above).
Mr Keenan tells active academics that their data is safe because the FoI specifically exempts information held “with a view to its publication, by the authority or any other person, at some future date”. This must imply (given that the tree-ring data had to be released) that there was no intention to publish the tree-ring data by anyone at Queen’s University Belfast; otherwise the data should have been exempted. How did Mr Keenan know that there was no intention to publish? The answer is simple, he stated on his web-site that QUB had closed the tree-ring laboratory. The same tone can be detected in his statement above.
So to put the record straight, the tree-ring laboratory at QUB is not closed, it is staffed and remains active. Apart from undertaking tree-ring research and offering a commercial dating service for oak samples, it continues to publish. Two books and some 20 single and joint authored papers have been published between January 2005 and June 2010. Other publications are with editors and in the pipeline. The intention has always been for existing staff and emeritus professors to publish all the dated tree-ring data. Yet despite all that, the ICO saw fit to find against QUB and force release of the raw tree-ring research data.
So the message that comes out of the Belfast experience is that academics do not have the data protection that Mr Keenan says they have. He has personally demonstrated how it is possible for an interested party to abuse FoI laws to extract current research data that was manifestly exempt.
PMR: Again the issues are – data supporting publication – and timescale.
So to sum up, this would not have happened if the principles of data had been clear – whether it can be owned, when it should be released, and how much. Many domains have solved this. Many have not.
But remember that it is not trivial. Each domain is likely to have different views of data and different constraints.
 why do XYZ models continue to yield significant prediction errors?
why do XYZ models continue to yield significant prediction errors? rational thought, controlled experiments, and personal observation.
rational thought, controlled experiments, and personal observation.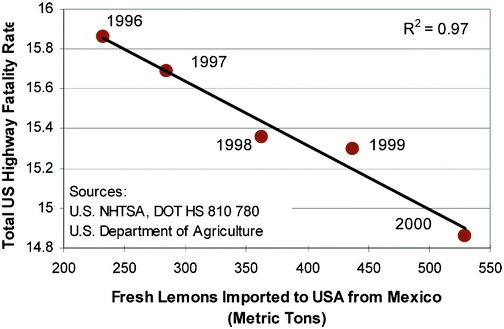

 Martin Ackroyd says:
Martin Ackroyd says: Richard J says:
Richard J says: David Holland says:
David Holland says:
{kind=link}
{kind=link}