Yesterday I blogged about our new project in Opening scholarship: @ccess. Several people retweeted it, and one asked “What’s @ccess for?” – a good prompt for some more information. @ccess is to discover OPEN scholarly information, to label it, and promote it. After that we believe that anything is possible. So I’ll use an example.
We’re lucky to get interesting birds in our garden and I idly wondered whether birds get malaria. They get influenza, of course, and they are a major host and therefore hazard to human health (the human viewpoint). But malaria? Do birds get bitten by mosquitos? I had no idea. So I went to Wikipedia and in 10 seconds discovered http://en.wikipedia.org/wiki/Avian_malaria . Yes birds get malaria. From a bird point of view it’s very serious:
Hawaii has more extinct birds than anywhere else in the world; just since the 1980s, 10 unique birds have disappeared. Virtually every individual of endemic species below 4000 feet in elevation has been eliminated by the disease [malaria].
And I read on:
since 1995, the percent of malaria-infected Great Tits has risen from 3 percent to 15 percent. In 1999, some 4 percent of Blackcaps — a species once unaffected by avian malaria —were infected. For Tawny Owls in the UK, the incidence had risen from two or three percent to 60%.[1]
And I was gobsmacked. Blackcaps used to be summer visitors only – but now they winter in UK (in our garden). And Owls. I have a special relation with owls in Cambridgeshire as my great-aunt, Alice Hibbert-Ware (who lived in Girton – 5 km from Cambridge), was seminal in persuading the country that little owls should be protected. Here’s Girton Bird News (http://www.girton-cambs.org.uk/nature/birdwatch0607.html ):
Once introduced, it spread rapidly and as it spread it fell foul of ever greater numbers of gamekeepers. They accused the Little Owl of every crime in their calendar, […] It was against this near hysterical background that Alice Hibbert-Ware, after an extensive publicity campaign in the press and on BBC radio, was appointed in 1935 by the BTO as principal investigator into the Little Owl’s diet. Over the next two years, assisted by 75 helpers in 34 counties, she assembled a mass of data, primarily derived from pains-taking dissection of 2460 Little Owl pellets (the indigestible fur and bones ‘sicked up’ by birds of prey), from just one of which she extracted the remains of 343 earwigs, and from another 2000 crane-fly (‘daddy-long-legs’) eggs. This forensic detail both demolished the myths of larders and beetle-luring charnel houses, and swept the ground from under the feet of those who stigmatised the Little Owl as a wholesale destroyer of game-bird chicks. Over the years the bird’s black reputation has withered away, due in no small measure to the initial efforts of Alice Hibbert-Ware, and it is now a welcome addition to the fauna of these islands. So, remember Alice when next you rest in the shade under ‘her’ trees!
I remember her through a photograph given to my father by Eric Hosking, the great bird photographer. It’s a gorgeous photograph, with the owl at the entrance to the burrow. Here’s a detail showing clearly that the owl is eating a cockroach, not a partridge chick.

So maybe Little owls also get malaria? And that’s where the problem starts. Wikipedia gives references
^ GaramszegI, László Z (2011). “Climate change increases the risk of malaria in birds”. Global Change Biology
17 (5): 1751–1759. doi:10.1111/j.1365-2486.2010.02346.x.
It’s from Wiley. So I have to pay. I don’t know how much but probably 30-40 USD. And I have to read it by midnight because I only have ONE day. So of course I don’t read it.
So I don’t know that owls get malaria. And I don’t know whether it’s restricted to Tawny Owls. I imagine not. So the Girton little owls probably have malaria.
And @ccess? When I read Wikipedia I’d like to know whether the references are worth following. It’s a waste of my time to click on links behind Wiley’s paywall. I have a legitimate need to follow up this information – it’s nothing to do with my day-job in the Univeristy of Cambridge, it’s because I am a concerned member of the human race.
Birdwatchers are part of the scholarly poor. @ccess aims to collect OPEN information in subdomains – doesn’t have to be science, but that’s my speciality. It has to be OPEN. The info can then be used for anything. Here’s some ideas:
- Collections of images
- Guides for health workers and patients
- Mapping information onto Open maps
- Tutorials
And hundreds more ideas
Here’s a typical example of a paper on avian malaria http://www.ncbi.nlm.nih.gov/pubmed/18442920
Struct Biol. 2008 Jun;162(3):460-7. Epub 2008 Mar 21.
The avian malaria parasite Plasmodium gallinaceum causes marked structural changes on the surface of its host erythrocyte.
Nagao E, Arie T, Dorward DW, Fairhurst RM, Dvorak JA.
Laboratory of Malaria and Vector Research, National Institute of Allergy and Infectious Diseases, National Institutes of Health, Bethesda, MD 20892, USA.
It’s got some lovely images in of how malaria infects cells, using atomic force, scanning and transmission electron microscopy (an area I used to be involved with). I’d like to put them on this blog. But I can’t. The paper is published by Elsevier and costs 31 USD to read. If I take images from that paper Elsevier might sue me. (Not fanciful, Wiley threatened a graduate student for daring to put a scientific image on her blog /pmr/2007/05/24/sued-for-10-data-points/ ). So science is impoverished.
But hey! At the bottom of the paper it says:
This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
This is almost gobbledegook to normal humans, but for those of us accustomed to doing battle (sorry, but that’s how I feel) with publishers I interpret this to mean:
This is what the authors sent to the journal. The copyright in this does NOT belong to the publisher and they have no rights over it. It’s technically the author’s pre-publication pre-review manuscript. So-called “Green” Open Access (not a self-evident term to non-specialists).
But that means the authors still hold the copyright? And I would have to ask them for permission ?
Normally yes. But the authors here are from the US NIH. And works of the US government are in the public domain. So the images are in the public domain! And here they are – how malaria gets into a cell:
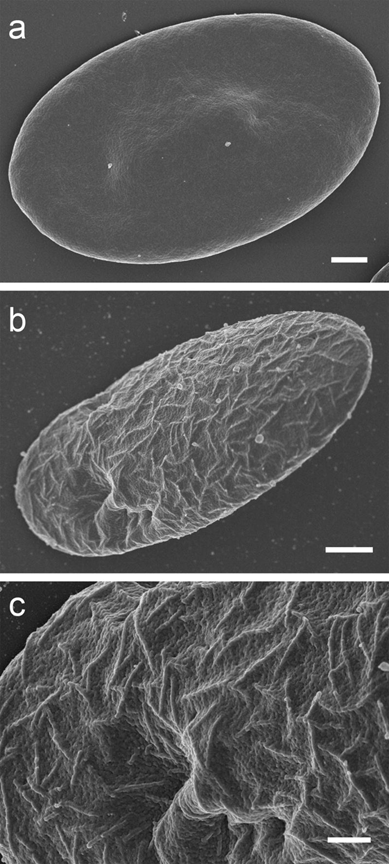
Fig. 1
Typical SEM images contrasting the surface topography of noninfected (a) and P. gallinaceum-infected erythrocytes (b, c). Noninfected erythrocytes have a smooth surface. In contrast, the furrow-like surface structures are seen on infected erythrocytes. Bars in (a) and (b) represent 1 μm, in (c) 200 nm.
If I’m wrong my quarrel is with the NIH, not Elsevier. If the NIH have handed the total copyright of these images to Elsevier then I’ll scrub this blog post.
If I’m not wrong, then these images can be aggregated into @ccess. And avaliable for anyone who wants them, for example:
- Writing a lecture
- Writing a textbook
- Educating people infected with malaria to show the science going into the problem
- Re-used as compoents in artistic works,
And so on.
Now it’s possible that I have run foul of Pubmed rules. That I can’t even re-use public domain works in Pubmed. If so, Pubmed will tell me. And they’ll tell me that THEY don’t make the rules – the publishers do.
Let’s see.
But in any case there is masses of stuff we can all put into @ccess, that will enhance the information available to the human race. And we all want that, don’t we?
NOTE: I took the photograph of the photograph of the little owl. I might have broken copyright as I http://en.wikipedia.org/wiki/Eric_Hosking died 20 years ago. But somehow I think he and his heirs will approve of what I have done.
NOTE: I can’t reproduce Alice H-W’s report on the Little Owl as, she died in 1944 and Wiley wants 30-40 USD for me to read it for ONE day. (Except I have it in my bedroom)








