In the previous post we showed how ContentMine could give immediate knowledge about a scientific topic – we analysed “Isospora”, which is a nasty tummy bug. Let’s just read Wikipedia to get some idea of the language we’ll need
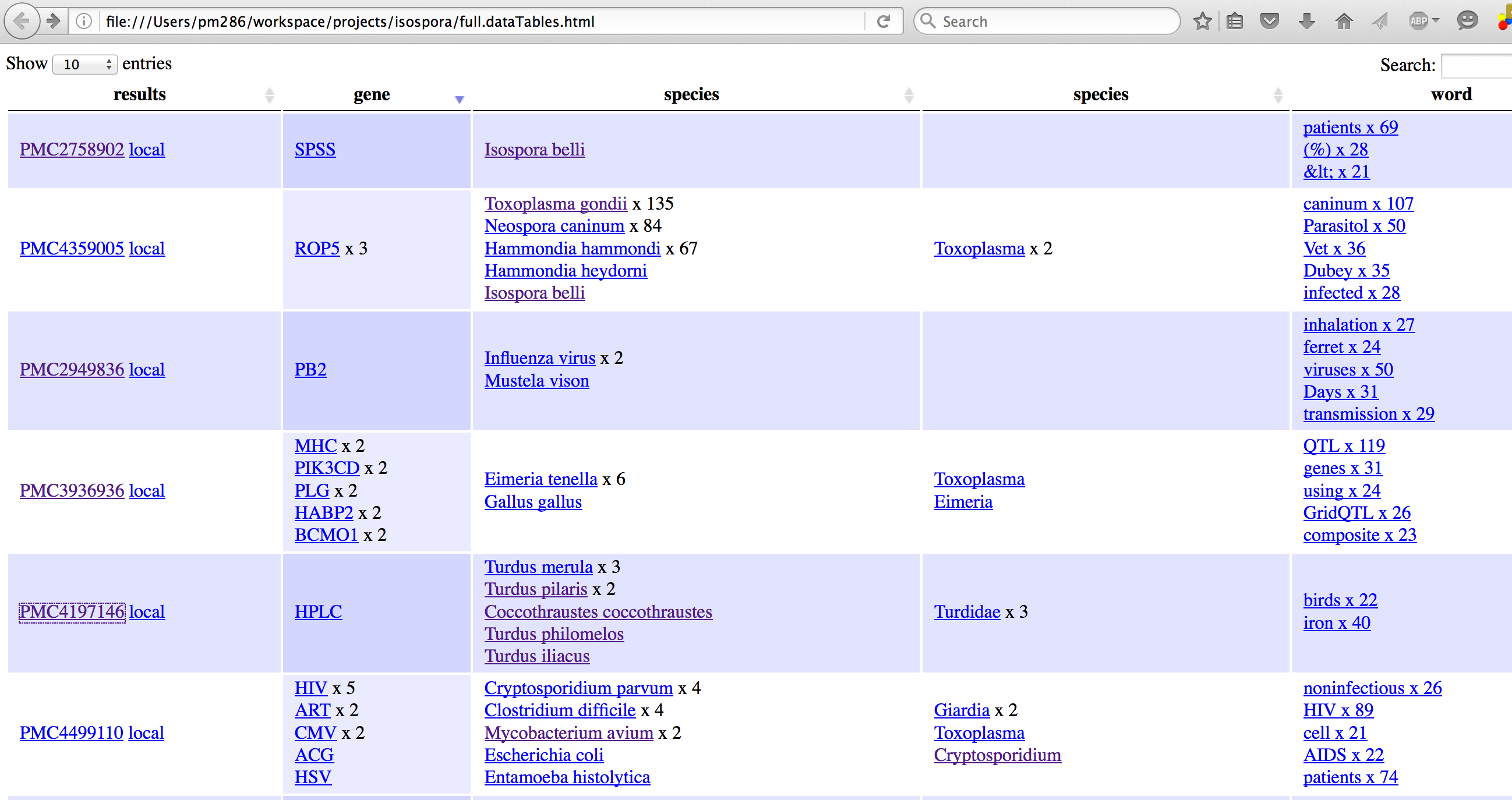
Life Cycle
PHIL 3398 lores
- An oocyst with one sporoblast is released in stool of infected person
- After the oocyst has been released, the sporoblast matures further and divides into two
- After the sporoblasts divide they create a cyst wall and become sporocysts
- The sporocysts each divide twice, resulting in four sporozoites
- Transmission occurs when these mature oocysts are ingested
- The sporocysts excyst in the small intestine where sporozoites are released
- The sporozoites then invade epithelial cells and schizogony is initiated
- When the schizonts rupture, mereozoites are released and continue to invade more epithelial cells
- Trophozoites develop into schizonts, containing many mereozoites
- After about one week, development of male and female gametocytes begin in the mereozoites
- Fertilization results in the development of oocysts, which are released in the stool [1][6]
The sporulation time of this parasite’s egg is usually 1–4 days, and the entire life cycle takes about 9–10 days.[7]
Wow! That’s complicated! But that’s because Life is complicated! These parasites have complex life cycles. You have to learn the terms – but it’s no harder than learning the terms in a new game, or a law case, or soccer strategy. You just need to want to do it! And Wikipedia will help. Wikipedia is always there. These parasites are all Apicomplexans and here’s their language https://en.wikipedia.org/wiki/Apicomplexan_life_cycle#oocyst
So if you are interested in more than just Isospora, use ContentMine to search for “Apicomplexan”.
Most of the papers have well defined messages. The first was about opportunistic infections in HIV patients. Read the word cloudlet for each paper here and see if you can guess the subject of papers 2,3,4,5,6. If you know the species behind the latin names that helps. If you don’t use your friend Wikipedia.
Here’s my thinking:
- Already done
- “Caninum, Parasitology, Vets – probably about Dogs. Toxoplasma I’ve heard of – it’s a parasite and https://en.wikipedia.org/wiki/Toxoplasma_gondii confirms it. Never heard of Neospora or Hammondia but I wouldn’t eat them. Check – https://en.wikipedia.org/wiki/Neospora , https://en.wikipedia.org/wiki/Hammondia_hammondi yes they are both Apicomplexa, the latter of cats. Did we get it right?
Canine faecal contamination and parasitic risk in the city of Naples (southern Italy).
- Seems to be about ferrets , and mink (Mustela) getting influenza. Ferrets develop fatal influenza after inhaling small particle aerosols of highly pathogenic avian influenza virus A/Vietnam/1203/2004 (H5N1).
It is. But why are people worried about ferrets getting sick?? Because influenza uses non-human hosts such as birds and ferrets so we might get it from them. And when I was in the pharma industry they used ferrets as a model of human disease.
Where’s the Isospora?
The animals lacked signs of epizootic catarrhal enteritis, and were negative by microscopy for enteric protozoans such as Eimeria and Isospora species using fecasol, a sodium nitrate fecal flotation solution (EVSCO Pharmaceuticals, Buena, NJ).
Translation: we made sure the test animals didn’t have other infections that could distort our research (and we told you how we did it).
- I know Gallus is a hen. And we’re going to add an icon and a mouseover on the table so you don’t need to look it up. Eimeria is an apicomplexan, and because it occurs 6 times in the paper it’s pretty important. I’m guessing it’s about parasites of hens. But what’s the rest? There are lots of genes and my guess is that they being used for c omparative genetics or possibly modes of action.
I don’t know what “QTL”. I probably should, but why bother when we have Wikipedia?
A quantitative trait locus (QTL) is a section of DNA (the locus) that correlates with variation in a phenotype (the quantitative trait).[1] The QTL typically is linked to, or contains, the genes that control that phenotype.
Rough Translation: The phenotype is what we feel, touch, smell, observe in an organism. and the QTL is that part of the genes that affects it.
So the paper is probably about genomic studies on parasites and chickens. Let’s look: QTL detection for coccidiosis (Eimeria tenella) resistance in a Fayoumi × Leghorn F₂ cross, using a medium-density SNP panel.
Rough translation: analysing the genome of chickens for regions that confer resistance the the most serious parasite. Eimeria is an apicompelxan, so I expect the paper mentions a range of them, including Isospora. (Yes: “Coccidia are sub-classified into several genera, including Eimeria, Isospora, Cryptosporidium, Toxoplasma and Sarcocystis. ) So we’re becoming experts on Apicomplexan names!
- Turdus, Coccothraustes … Thrushes and Hawfinch. Also cloudlet show “birds” and “iron”. “Deadly Outbreak of Iron Storage Disease (ISD) in Italian Birds of the Family Turdidae” . This is the paper where they examines the birdshit for parasites…
So that seems a lot of work – and we are only 5 papers through. But some of those are relevant to Natalie and some aren’t – her false positives. So can we get ContentMine to select just the ones she needs?
We hope so. If the paper has a lot about apicomplexans it’s probably relevant. If it’s about other diseases such as HIV or flu it’s probably not. So we could remove those automatically.
And that would save a lot of time. And hopefully help us learn bioscience in an efficient manner.