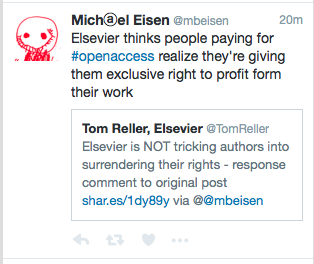
TL;DR. I continue to try to get public data out of Elsevier. I think I should be able to – every other publisher has no problem. After some not-very-useful replies Elsevier simply give up answering me.
Over the last 7-8 years I have had major issues with Elsevier on many aspects – licensing, paywalls , availability etc. It’s normally impossible to find anyone who gives me a straight answer. I believe that a modern company should have a clear channel of communication – where requests are handled formally and there is accountability when things go wrong.
Indeed some do. Cambridge and Oxford University Presses. They are parts of the Universities and so have to abide by Freedom Of Information request rules – give clear public answers to questions within a given period of time (20 working days). – and I have used this. By contrast Elsevier find many ways of not answering questions.
So I try again – and I leave it to you to decide whether this is a company that the UK should give 40 M GBP of taxpayers’ money to. When I go to meetings about scholarly publishing and informatics there are increasingly representatives from Elsevier who mingle with the other delegates. They are “friendly” and “want to help us”. So here’s the first story – there may be more. Always remember that we are paying them.
Background: Everyone (except Elsevier) thinks that non-sensitive scientific data accompanying an article should be in the public domain. This is critical because the data:
- is there to support the claims in the article.
- can be re-used by others for many purposes (data-driven science, deriving parameters, aggregation, simulation – a huge list). I have spent much of my scientific career re-using public data.
I’m going to take crystallographic data – my field, but also central to much modern science. Its publication has been supported by International Unions, CODATA, and many other respected scientific bodies.
And almost all publishers make it public. American Chemical Society, Royal Society of Chemistry, Acta Crystallographica and many more.
But not Elsevier. They either hide it behind a paywall, or send it to the Cambridge Crystallographic Data centre, [1] send it to the Cambridge Crystallographic Data centre who provide it under a subscription licence (a trivial amount – probably < 1% is available for free, but NOT for re-use) OR [2] hide it behind a paywall,. I wrote to the “Director of Universal Access” some years ago and got waffle.
I and many others think this is outrageous. It’s public data, not Elsevier’s . The science in the paper is seriously diminished without the data. I help run the Crystallography Open Database (COD) which has hundreds of thousands of structures. Will Elsevier give these back to the public?
The only route that I have are the “helpful” reps I meet. So a month ago I met one. He agreed to take my concern into Elsevier. At least I would get a clear answer…
I am including all the letters. I have removed the name of the Elsevier rep.
[1,2,3] TL;DR he agreed to take something on. It wasn’t his department. He’s sent it off.
[4,5] He discovers that authors can send their files to [1] CCDC or [2] Elsevier (behind the paywall). This defines the scope of the question. (It doesn’t tell me anything I didn’t already know). Most of the data are in the second category.
[6] PMR reiterates that by hiding data Elsevier is going against all other responsible parties in the field.
[7] Elsevier replies that they assume I only want data of type 2 and that they can make them available “openly” behind a Mendeley login.
[8] PMR replies that we want all the data (this is consistent with every other publisher) and that data behind a Mendeley login [2] are not open. PMR lists 6 questions that he would like answered.
I have not had the courtesy of a reply even after 19 days, so I can only assume Elsevier regard me as not worth continuing to answer.
==================================
[1] PMR 2016-04-19
I thank you for our conversation yesterday, where you agreed that all factual supplemental crystallographic data published with papers in Elsevier journals should be made available without restrictions (effectively CC0). You agreed that you would work with your technical colleagues to see how this could be done as soon as possible (“flipping a switch”). You agreed that this would bring Elsevier into line with most other major publishers (ACS, RSC, IUCr, Nature) who have for many years released all their crystallographic data (“CIF”s) into public view on their websites, without restrictions. This data would include both current published data (probably back to about 1990) and all future data.
The Crystallography Open Database (COD) (PMR is a board member) has a 10-year record of accepting, validating CIFs from all domains (organic, organometallic, inorganic, metals and alloys) and then offering to the world for re-use under effectively CC0 licence. It also provides a variety of modern search and analysis software.
I ask that you commit to this publicly now and am confident that COD will be willing to host the data if Elsevier does not wish to mount them on its web pages.
[2] Elsevier 2016-04-19 =======
To be very clear – what we agreed was that I would look into this and get back to you with a clear response one way or the other. I made no commitment as this is not in my area of responsibility. I’d appreciate in the interests of establishing trust between us that we are both careful in reporting our conversations accurately.
Per our conversation I have already reached out to my colleagues to understand the current situation w.r.t. Crystallographic supplemental files in our journals. I will let you know as soon as hear back.
[3] PMR: 2016-04-19 =========
Thank you,
I would not intend to publish anything representing your views and position that you weren’t happy with.
For reference I shall forward you Elsevier’s less-than-useful reply 3 years ago. If you can do better than this , fine, else it will be a waste of my time.
It would be useful for you to set a tight timescale. If you aren’t able to give a clear yes/no in a month from now it will be yet another “we’ll look into it for you” that disappears, and I shall regard it as “no”.
After a month I shall announce Elsevier’s decision as reported to me.
If you want technical help and explanation of what we want and how to make it available. then I am sure Saulius will be delighted to help.
[4] Elsevier 2016-04-19 ==========
I’ll follow up as promised and let you know the outcome
[5] Elsevier 2016-05-05 ==========
I wanted to let you know that I am making some progress in discussions with internal colleagues w.r.t. how we currently treat CIF files, but I haven’t got fully to the bottom of the story.A couple of facts I have discovered:
- We give authors the choice as to whether they deposit their CIF files with an external database and provide us with a link to the file, or have us host their files as Supplementary Material. You can see examples of the two cases as follows
- Articles linking out to CCDC using data banner links (e.g. http://www.sciencedirect.com/science/article/pii/S0040402009001021)
- Articles with CIF files delivered as supplementary material (e.g. http://www.sciencedirect.com/science/article/pii/S2352340915000906)
I will keep you informed as I learn more. However, for confirmation I assume that your main interest is in securing open access to files in category 2 above?
PMR: [6] 2016-05-05 ============
To clarify our relationship. I am acting as a board member of the Crystallography Open Database, a Public Interest Research Organization (PIRO), and copying them. You are a formal representative of Elsevier. / RELX. I regard our correspondence as in the public interest and intend to publish all of it.
I list below a number of direct, simple questions to which I request answers. These are ones that I would expect organizations subject to Freedom Of Information requests (including, for example OUP and CUP, and myself) to have to answer. Although Elsevier is not subject to FOI I am expect the same comprehensive and clarity of response. There is also a request for crystallographic data.
I have set out our expectations. In summary: All major publishers except Elsevier make their crystallographic data fully and publicly available, effectively CC0. Elsevier’s policy is in direct conflict with national and international science organizations such as CODATA, ICSU and the International Union of Crystallography. Elsevier’s position in withholding scientific data is in direct opposition to the norms and expectations of the scientific world.
[7] Elsevier 2016-05-05 ==========
I wanted to let you know that I am making some progress in discussions with internal colleagues w.r.t. how we currently treat CIF files, but I haven’t got fully to the bottom of the story.
- Articles linking out to CCDC using data banner links (e.g. http://www.sciencedirect.com/science/article/pii/S0040402009001021)
- Articles with CIF files delivered as supplementary material (e.g. http://www.sciencedirect.com/science/article/pii/S2352340915000906)
I will keep you informed as I learn more. However, for confirmation I assume that your main interest is in securing open access to files in category 2 above?
[8] PMR 2016-05-05 ============
Thank you. I have allocated you the same length of time (one month/20 working days) as for a UK FOI request to provide information. If you are also, as I expect, working towards a change in Elsevier policy and practice, then it will be necessary at the end of the month to detail what you have set in motion and with what expected timescale. Until 21st May I accept that I will not make our discussions public.
>ELS> For articles with CIF files that we host as supplementary material [type 2], we are still evaluating both from the technical point of view and the legal point of view the feasibility of making these available openly via our new Mendeley data platform (http://data.mendeley.com).
>PMR> The word “openly” is imprecise. I note that Mendeley requires a login which is inconsistent with Openness. I assume therefore that Mendeley will impose its own terms and conditions, which by definition will be inconsistent with CC0.
Note that under the new 2014 UK exception to Copyright I can legally mine the data associated with any Elsevier publication that I have the right to read. Since the data itself is uncopyrightable, and since a journal is not a database covered by European sui generis database rights, I can therefore download all CIFs as part of my personal non-commercial research and I can publish the data from that research. There is no benefit in using Mendeley. From Elsevier’s point of view it would possibly be preferable to bundle this historic data now and ship it to COD and we would be happy to make this technically possible. Otherwise I shall extract it under the UK law.
>ELS> I will keep you informed as I learn more. However, for confirmation I assume that your main interest is in securing open access to files in category 2 above?
>PMR> **NO**. Our interest is in all supporting ALL crystallographic data that is associated with ALL Elsevier publications, in line with all other major publishers.
I would therefore like answers to the following questions and will publish answers when the month is up. I have framed them so that many can be answered with Yes/No/DeclineToAnswer/. I use the phrase “NonOpen database) to refer to databases such as those run by CCDC, ICSD and other organizations which do not make the total data available under CC0. (Note that if these questions were submitted to OUP I would expect them all to be fully answered under FOI).
- Does Elsevier hold copies of ALL raw CIFs associated with Elsevier publications, or if not can it obtain these CIFs?
- Please provide a complete list of all NonOpen databases that Elsevier requires or allows authors to submit crystallographic data to. Please indicate whether Elsevier has the right to obtain ALL the crystallographic data in BULK associated with their publications.3. Does Elsevier have formal contractual relations with these NonOpen databases. Please indicate what these contracts allow and forbid.
- Please indicate how Elsevier decides on its policy on crystallographic data. Does it consult with ICSU, CODATA or IUCr? When was the policy last reviewed? What is the mechanism for PIROs to formally request changes in policy?
- Please provide a list of all files of Type 1 and Type 2 and a service where updates of these lists can be obtained.
These are requests for information.
Our request for crystallographic data, which is consistent will all major scientific bodies, funding bodies and all major publishers other than yourselves, for the files themselves is:
5.Please provide all files of type 1 and 2 , or an open mechanism (e.g. an API) where all these files can be obtained. Please confirm that redistribution of the files is permitted without further permission.
- Please indicate that Elsevier is committing to changing the policy to make supplemental data files publicly, freely and openly available. Please indicate the process that has been initiated and how it will report back to the world.
I will publish the correspondence, unedited, on 21st May.
=====================
19 days have elapsed without the courtesy of a reply