
[P Murray-Rust, CC 0]
We had our hack day in Edinburgh yesterday on content mining.
First, massive thanks to:
- Mark MacGillivray for organising the event in Informatics Forum
- Informatic Forum for being organised
- Claire and Ianthe from Edinburgh library for sparkle and massive contributions to content mining
- PT (Sefton) for organising material for the publishing and forbearance when it got squezzed in the program
- Richard Smith-Unna who took time off holiday to develop his quickscrape code.
- CottageLabs in person and remotely
- CameronNeylon and PLoS for Grub/Tucker etc.
- and everyone who attended
Several participants tweeted that they enjoyed it
Claire Knowles @cgknowles Thanks to @ptsefton for inviting us and @petermurrayrust for a fun day hacking #dinosaur data with @kimshepherd@ianthe88 & @cottagelabs
So now it’s official – content mining is fun!. You’ll remember we were going to
- SCRAPE material from PLOS (and other Open) articles. And some of these are FUN! They’re about DINOSAURS!!
- EXTRACT the information. Which papers talk about DINOSAURS? Do they have pictures?
- REPUBLISH as a book. Make your OWN E-BOOK with Pictures of DINOSAURS with their FULL LATIN NAMES!!
About 15 people passed through and Richard Smith-Unna and Ross Mounce were online. Like all hackdays it had its own dynamics and I was really excited by the end. We had lots of discussion, several small groups crystallised and we also covered molecular dynamics. We probably didn’t do full justice to PT’s republishing technology, that’s how it goes. But we cam up with graphica art for DINOSAUR games!
We made huge progress on the overall architecture (see image) and particularly on SCRAPING. Ross had provided us with 15 sets of URLs from different publishers, all relating to Open DINOSAURS.
Hard work, and we hope to automate it through CRAWLING, but that’s another day. So could we scrape files from these. Remember they are all Open so we don’t even have to invoke the mighty power of Hargreaves yet . However the technology is the same whether it’s Open or paywalled-and-readable-because-Cambridge-pays-lots-of-money.
We need a different scraper for each publisher (although sometimes a generic one works). Richard Smith-Unna has created the quickscrape platform https://github.com/ContentMine/quickscrape. In this you have to create a *.json for each publisher (or even journal).
The first thing is to install quick scrape. Node.js, like java, is a WORA write-once-run-anywhere (parodied as WODE write-once-debug-everywhere). RSU has put a huge amount of effort into this so that most people installed it OK, but a few had problems. This isn’t RSU’s fault, it’s a feature of dependencies in any modern language – versions and platforms and libraries. Thanks to all yesterday’s hackers for being patient and for RSU breaking his holidy to support them. (Note – we haven’t quite hacked Windows yet, but we will). For non-hacker worksops – i.e. where we don’t expect so many technical computer experts we have a generic approach to distribs.
Then you have to decide WHAT can be scraped. This varies from whole articles (e.g. HTML) to images (PNG) to snippets of text (e.g. licences) What really excited and delighted me was how quickly the group understood what to do and then went about it without any problems. The first task was to list all the scrapable material and we used a GoogleSpreadsheet for this. It’s not secret (quite the reverse) but I’m just checking permissions and other technicalities before we release the URL with world access.
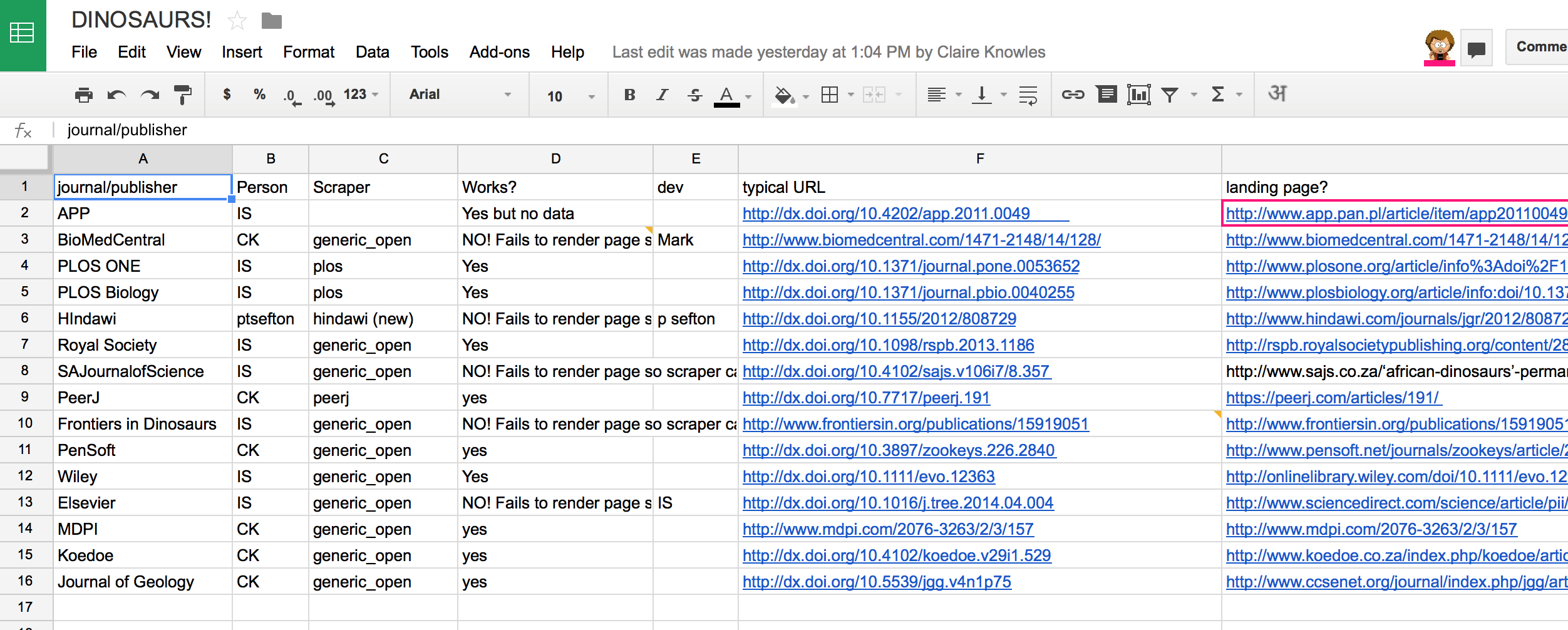
You’ll see (just) that we have 15 publishers and about 20 attributes. Who did it? which scraper (note with pleasure that RSU’s generic scraper was pretty good!). Did it work? If not this means customsing the scraper. 9.5/15 is wonderful at this stage.
The great thing is that we have built the development architecture. If I have the Journal of Irreproducible Dinosaurs then I can write a scraper. And if I can’t it will get mailed out to the Content Mine communiaty and they/we’ll solve it. So fairly shortly we’ll have a spreadsheet showing how we can scrape all the journals we want. In many instances (e.g. BioMedCentral) all the journals (ca 250) use the same tecnology so one-scraper-fits-all.
If YOU have a favourite journal and can hack a bit of Xpath/HTML then we’ll be telling you how you can tackle it and add to the spreadsheet. For the moment just leave a comment on this blog.
Pingback: Content Mining hackday in Edinburgh; we solve Scraping – ContentMine