[The Scholarly Kitchen branded me as an “Ignorant Chemist” for criticising the technical standard of scholarly publishing. So read this with caution.
BTW I feel slightly unhappy criticising an Open Access publisher but their technology is just as bad as the legacy publishers].

As readers will know we are gearing up to index the whole of the scientific scholarly literature. The idea is simple. Download all the links to papers, and then read the papers [NOTE: we’ll only do what we are allowed to do, and we promise not to burn out your servers].
So we’ve started with PLoSONE. AMI is reading the page http://www.plosone.org/#recent which gives the latest PLoS papers. She’s going to parse it into a XOM (http://about.validator.nu/htmlparser/ ) and then extract all the papers using Xpath. She knows how to do this . So off we go:
It crashes on the parse. This does not upset AMI (who has the emotional capacity of a FORTRAN compiler) but it drives me wild. I should be able to read a modern document with modern tools. I know what I am doing. What has crashed it is the tag “<italic>”. Note that it’s not terminated by an “</italic>” tag. Moreover I can’t find it in the HTML5 vocabulary (which has a perfectly good, 22-year old <i> tag: http://www.w3.org/html/wg/drafts/html/CR/text-level-semantics.html#the-i-element ) So I have to create a kludge. Since I have no idea what other horrors are waiting in PLoS (or any other publisher’s HTML – this is not a PLoS-specific complaint) it can throw my work of by days.
It’s not fair to take USD 2900 (the highest PLoS charge) or even USD 1350 (PLoSONE) from authors and produce non-conformant output. [I criticize elsewhere the destruction of vector diagrams into JPEGs.] Nor should this non-standard HTML ever have happened. HTML is produced by the W3C, and a huge amount of effort has gone into producing HTML tools, including validation and compliance, Because the W3C cares about technical quality. So it’s possible and easy to validate. And it’s free.
Is this XML? No. Is this HTML5? No. Are the contents of the tag rendered in italic font? No. Does this matter?
Yes. Because I am looking for italic content since its may contain species. In fact Gorilla gorilla IS a species. You might be able to guess what genus.
The file starts with
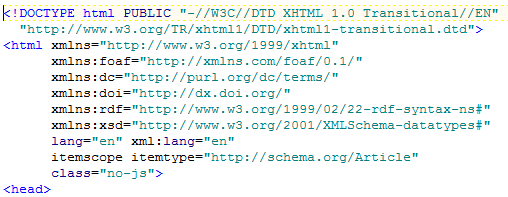
The DOCTYPE is a statement that defines an XML document. I am not ignorant about this because I spent 2 years helping the W3C develop XML and was co-inspirer of the SAX protocol (http://www.saxproject.org/sax1-history.html ). The statement says that the document following must be well-formed XML.
Which it isn’t. “itemscope” is NOT XHTML.
Here’s another illiteracy (< and > are not allowed in attribute values) :
title=”Gorilla Mothers Also Matter! New Insights on Social Transmission in Gorillas (<italic>Gorilla gorilla gorilla</italic>) in Captivity”
This isn’t XML. It’s wasted 3 hours of my time. I am going to have to write a TidyPLOS2WellFormedXML tool.
If it’s HTML5, then the standard way the W3C indicates it (http://www.w3.org/wiki/Doctypes_and_markup_styles#The_HTML5_doctype ) is:
<!DOCTYPE html>
Hardly difficult. Easier than putting all the wrong stuff into a non-well-formed document.
Now I can guess the technical reason why PLOS got it wrong. I’ll leave you to guess.
I can also guess the social reason. It stems from the observation that scholarly publishing doesn’t care about technical quality. The look and feel of a journal is all that matters. (That’s not much use for unsighted humans and machines). I suspect there are a relatively small number of typesetters and that most of them (perhaps Kaveh excepted) don’t care about technical quality.
The technical quality of material in the arXiv preprints is pretty good. So it should be – maths and physics are high quality subjects. But when it comes out of the publishers the technical quality is often significantly worse.
But then it’s not their money that universities are spending – 15 Billion USD – it’s taxpayers and students. They don’t care about the quality of what they are paying for. And until somebody cares this will probably continue.
Hello, my name is John Chodacki and I am a PLOS employee. Thanks for pointing out the incorrect tag. It looks like our XSLT missed the XML tag during transformation. We will work to fix this as soon as possible.
Also, I know you are working with my colleagues to get our articles loaded into your Daily Digest prototype. If it would help, we can send over information about how to access the XML directly. That may or may not be a better source for this project.
Many thanks John and thanks for the offer. I will reply by mail