Extracting tables from PDFs is not fun. But @TabulaPDF have made it possible. So we are going to learn how to extract tables at Jenny’s liberation-fest tomorrow. Here’s how:
Got to http:// http://tabula.nerdpower.org/
(That’s right: NERD POWER. Nerds are good. Nerds are clever). We find:
Tabula
Tabula is a tool for liberating data tables trapped inside PDF files.
Why Tabula?
If you’ve ever tried to do anything with data provided to you in PDFs, you know how painful this is — you can’t easily copy-and-paste rows of data out of PDF files. Tabula allows you to extract that data in CSV format, through a simple interface. And now you can download Tabula and run it on your own computer, like you would with OpenRefine.
Download and install Tabula
Note: You’ll need a copy of Java installed. You can download Java here.
1. Download the version of Tabula for your operating system:
-
Windows:
tabula-win.zip -
Mac OS X:
tabula-mac.zip- OS X 10.8+ users: if you have issues opening the app, see note at bottom of download page
-
Linux/Other:
tabula-jar.zip (view README.txt inside for instructions)
2. Extract the zip file using the file extractor of your choice (such as 7-zip).
3. Go into the folder you just extracted. Run the “Tabula” program inside.
4. In your web browser, go to http://localhost:8080/ . (This should automatically happen, actually.) There’s Tabula!
5. Upload a file of your choice. Select a section of a table, and go.
That’s it.
It works! Here’s a table (they are Gibbons!) [#animalgarden needs more monkeys…]
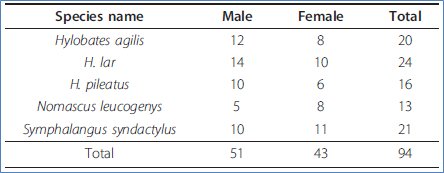
We use Tabula. Select the table and we get:
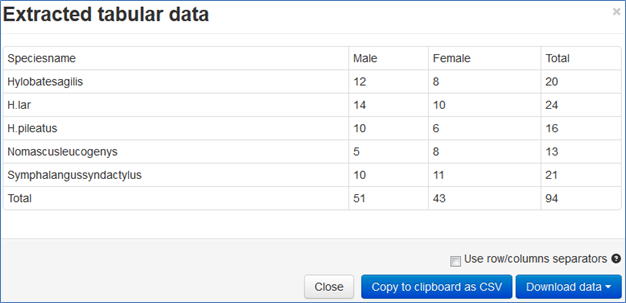
WOW! It’s actually in a CSV table
OK the spaces are occasionally elided, and the italics are gone, but we are working on that…
… TOGETHER!
Tabula is better than #ami2 on tables (AMI relies on the English word “Table” and her tables are currently being refactored). Tabula is developing auto-detect. #ami2 is probably better on italics and spaces.
So we join forces. Everyone gains.