We are doing well at reconstructing semantic material from PDFs (#AMI2) but the challenges we are thrown are considerable. Here’s today’s amusement:
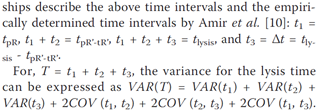
#AMI2 can reconstruct most of this perfectly, but she doesn’t know what to do with a hyphenated-subscript. Nor do I, but I’m just an ignorant chemist. The publishing industry tells us that they need our money to produce beautiful easily readable typeset documents. So here’s an example of human readability from the same paper:

#AMI2 can read this, but can you? Wouldn’t it be easier to typeset it as equations? But that would take up an awful lot of space, and as we know journals have to reduce the space (I never understand why).
I have a plane journey so AMI and I can do some real hacking. We hope to release an alpha version RSN.
About why journals reduce space… Traditionally, journals printed, and the cost of printing and distributing an extra page was pretty significant (depending on the printing process pages were sometimes printed in multiples of 4). In order to minimise their overheads and increase their profits, then publishers would encourage tight typesetting. In the current world of online publishing, there is no good reason for cramming text into every available space, but there is still a residual perception from print days that tightly-typeset content is ‘better quality’ – legibility and clarity should trump this though.
In my experience, publisher’s production teams are unlikely to over-rule layout decisions on the way chemical and mathematical formulae have been presented by authors (because we are not qualified), and will generally go with what the author provided.
For your example, I guess the author provided the formulae inline with the text in a one-column word file, where it was more legible than when typeset into a two-column PDF file.
So authors can help the process by considering the final version layout (eg putting long/complex formulae onto new lines)… and publishers should highlight potential legibility problems, and check-in with the author on how these can be overcome if it is not clear.
Thanks,
But this should not have been published in this way at all. Why should the author have to work to make the typesetter’s job easier?