
Oreina gloriosa from Wikipedia (you’ll see why)
I’ve read 25+ academic papers about extraction of information from PDFs and only 1 of those makes any mention of availability of code. These papers are published to announce a new (usually incremental or even repeated) advance and the main driving force is academic glory and reward. I don’t blame the authors in most cases – that’s how the academic systems works (and that’s what I blame). But it means that when I, for example, wanted to create #ami2 I had to start from scratch.
No, that’s completely unfair to PDFBox and Apache on which #ami2 is based. But in terms of analysing scientific PDFs I had to start from PDFBox. No existing code to help with tables, graphs, trees, text, etc. And although I have heard many presentation by academics there is very little re-usable code – so I had to write my own.
Not MY own. OUR own. Because everything I do is for US. That’s what works in the Blue Obelisk. (I was delighted to hear yesterday that Jmol now has a completely JavaScript version. That means I don’t have to write a JavaScript viewer for 3D chemistry.) And it is what will work in #scholrev. A community approach to building the tools for open scholarship.
Today I got a tweet that a group (@Tabula) was working on extraction of tables from PDFs – the area I am spending a lot of my time in. A typical academic reaction might be “Blast. We’ve been scooped”. Because that means we couldn’t publish anything on extraction of tables. (That’s not true, of course; duplicate work often gets published – Just not in the glamour mags. And duplication – within reason – is good because it cross-fertilizes and acts as a check).
So MY/OUR reaction was Great! I don’t have to do tables. I can use @Tabula instead. Now let’s see what it does. I haven’t yet corresponded with @tabula folks but it’s related to Mozilla and anyway it’s under an Open licence and invites collaboration. So I know I can use it – only question is what sort of technology – static/dynamic link, web service, or even translating code. (Of course this would be done with agreement and acknowledgement.
Let’s have a look: http://source.mozillaopennews.org/en-US/articles/introducing-tabula/
A table with ruling lines

A fully lined table.
Tables without row or column graphic separators are also common. For these type of tables, we cluster together the words that vertically overlap each other. The row boundaries are the bounding boxes of each detected cluster of words.
A table without graphic separators

Detected row boundaries in a table without graphic separators.
An analogous procedure is then carried out for detecting column boundaries. Tabula clusters together words that overlap horizontally. The bounding boxes of those clusters are the column boundaries.
Wow. This looks exactly complementary to #ami2-svg2xml. Here’s where we have got to with #AMI2 – chopping up the page. A table from BMC Evolutionary Biology. (BMC is a commercial Open Access CC-BY publisher who WANT you to re-use material, unlike most mainstream “closed publishers” who make it extremely difficult).
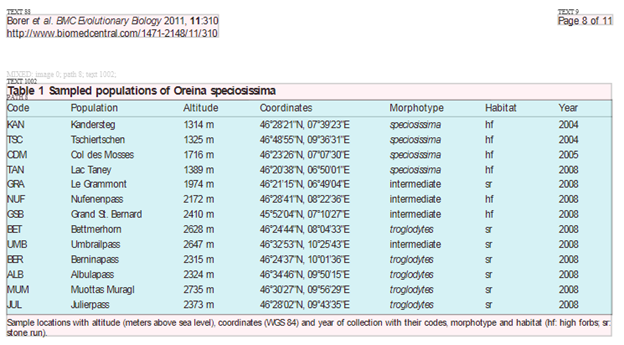
#AMI has chopped the page into bits (this is not all of it) and has identified the Table because it says T-a-b-l-e. (We have to teach AMI every word). The “Table” consists of a box with (a) caption and (b) table body (c) a footer. The table body has column headers (e.g. Code, Population). AMI2 does not yet understand what these actually mean – but we shall teach her.
I haven’t yet tried out @Tabula but I am very hopeful it will manage the body of the table.
When it does we then have to find out what the columns mean. I expect that words like “Coordinates” and “Year” will be very common and we can develop heuristics or machine learning. The format of the columns also contains vital information. Note that the altitudes are all > 1000 m so we have an alpine context.
What’s it about? “Sampled population of …” suggests population studies. And we can look in the text:

“Oreina speciosissima” occurs in italics. This is suggestive of a binomial organism name. Here’s NL Wikipdeia http://nl.wikipedia.org/wiki/Oreina_speciosissima . A web search gives us http://www.biol.uni.wroc.pl/cassidae/European%20Chrysomelidae/oreina%20speciosissima.htm where we have pictures (they are copyright but very beautiful). I’ll give you an http://en.wikipedia.org/wiki/Oreina_speciosa instead

I hope you can see how all this links together. Beetles, places, mountains, dates, etc. A new type of science.
And why I am so ANGRY about mainstream publishers preventing us doing this.