In a previous post I outlined the architecture for building a (weakly) intelligent scientific amanuensis, AMI2. (/pmr/2012/10/20/opencontentmining-the-ami2-project-for-understanding-the-scientific-literature-and-why-i-love-pdf/ ) We have made a lot of progress since then, mainly in formalizing, refactoring, documenting, clearing our thoughts. (Refactoring is a computing chore, rather like cleaning the cooker or digging in manure or setting pest traps. There’s nothing new to offer people, but you are in a much better position to cook, grow, build, etc. Things will work). So we are now able to say more clearly what AMI2 is (currently) comprised of.
[You don’t have to be a compsci to understand this post.]
I’ll show our picture again, if only because of the animal (you know what it is, I hope):
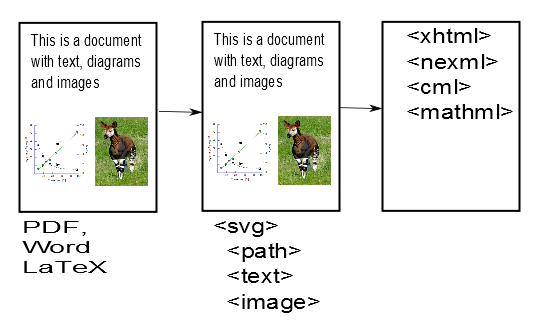
And label them
- PDF2SVG (creating clear syntax)
- SVGPlus (creating clear structure)
- STMXML (creating science)
(These names may change. Constant change (“Refactor mercilessly”) is a necessary feature of good software (the reverse may also be true, I hope!). These are becoming clearly defined modules.
At the end of the last post I asked some questions. I hoped people would give answers so that I could learn whether my ideas made sense. (Feedback is very valuable, Silence rarely helps). Here they are again
And some more open-ended questions (there are many possible ways of answering). In
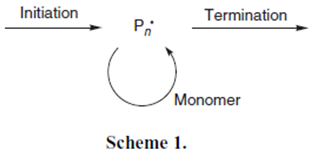
How would you describe
-

-
-
- The top right object in
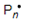
There are no right answers. It depends who or what you are. I’ll postulate three types of intelligent being
- A polymer chemist
- A non-scientific hacker
- PDF2SVG
The chemist would answer something like:
- The initiation process of the polymerization
- A forward-proceeding chemical reaction
- A reaction scheme
- A free radical (the “dot”
The hacker might answer:
- The word “initiation” at a given coordinate and in a given font/weight/style
- A right-pointing arrow
- A string of two words (“Scheme” and “1.”)
- A superscript (“degree”) symbol
The PDF2SVG part of AMI2 sees this in a more primitive light. She sees:
- 10 characters in a normal san-serif font with coordinates, sizes and fonts
- A horizontal line and *independently* a closed curve of two lines and a cubic Bezier curve
- 8 characters in a bold serif font.
- Two Cubic Bezier curves.
In PDF there are NO WORDS, NO CIRCLES, NO ARRROWS. There are only the primitives:
- Path – a curved/straight line which may or may not be filled
- Text – usually single characters, with coordinate
- Images (like the animal)
So we have to translate the PDF to SVG, add structure, and then interpret as science.
This is hard and ambitious, but if humans can do it, so can machines. One of the many tricks is separating the operations. In this case we would have to:
- Translate all the PDF primitives to SVG (I’ll explain the value of this below)
- Build higher-level generic objects (words, paragraphs, circles, arrows, rectangles, etc.) from the SVG primitives
- Interpret these as science.
Hasn’t all this been done before?
Not at all. Our unique approach is that this is an OPEN project. If you are interested in, say, interpreting flow diagrams from the literature and you enjoy hacky puzzles then this is a tremendous platform for you to build on. You never need to worry about the PDF bit – or the rectangle bit – we have done it for you. Almost all PDF converters neglect the graphical side – that’s why we are doing it. And AMI2 is the only one that’s OPEN. So a number of modest contributions can make a huge difference.
You don’t have to be a scientist to get involved.,
Anyway, why PDF2SVG?
PDF is a very complex beast. It was developed in commercial secrecy and some of the bits are still not really published. It’s a mixture of a lot of things:
- An excutable language (Postscript)
- A dictionary manager (computer objects, not words)
- A font manager
- A stream of objects
- Metadata (XMP)
- Encryption, and probably DRM
And a lot more. BTW I know RELATIVELY LITTLE about PDF and I am happy to be corrected. But I think I and colleagues know enough. It is NOT easy to find out how to build PDF2SVG and we’ve been down several ratholes. I’ve asked on Stackoverflow, on the PDFBox list and elsewhere and basically the answer is “read the spec and hack it yourself”.
PDF is a page-oriented language and printer-oriented. That makes things easy and hard. It means you can work on one page at a time, but is also means that there is no sense of context anywhere. Characters and paths can come in any order = the only thing that matters is their coordinates. We’re using a subset of PDF features that map onto a static page, and S VG is ideal for that:
- It’s much simpler than PDF
- It’s as powerful (for what we want) so there is no loss in converting PDF to SVG
- It was designed as an OPEN standard from the start and it’s a very good design
- It’s based on XML which means it’s easy to model with it.
- It interoperates seamlessly with XHTML and CSS and other Markup Languages so it’s ideal for modern browsers.
- YOU can understand it. I’ll show you how.
PDF is oriented towards visual appearance and has a great deal of emphasis on Fonts. This is a complex area and we shall show you how we tackle this. But first we must pay tribute to the volunteers who have created PDFBOX. It’s an Open Source Apache project (http://pdfbox.apache.org ) and it’s got everything we need (though it’s hard to find sometimes). So:
HUGE THANKS TO BEN LITCHFIELD AND OTHERS FOR PDFBOX
I first started this project about 5-6 years ago and had to use PDFBox at a level where I was interpreting PostScript. That’ no fun and erro-prone, but it worked enough to show the way. We’ve gone back and found PDFBox has moved on. One strategy wold be to interrupt the COSStream and interpret the objects as they come through. (I don’t know what COS means either!) But we had another suggestion from the PDFBox list – draw a Java Graphics object and capture the result. And that’s’ what I did. I installed Batik (a venerable Open Java SVG project) , created an Graphics2D object , saved it to XML. And it worked, And that’s where we were a week ago. It was slow, clunky and had serious problem with encodings.
So we have been refactoring without Batik. We create a dummy graphics with about 60-80 callbacks and trap those which PDFBox calls. It’s quite a small number. We then convert those to text or paths, extract the attributes from the GraphicsObject and that’s basically it. It runs 20 times faster at least – will parse 5+ pages a second on my laptop and I am sure that can be improved. That’s 1-2 seconds for the average PDF article.
The main problem comes with characters and fonts. If you don’t understand the terms byte stream, encoding, codepoint, character, glyph, read Joel Spolksy’s article “The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)” (http://www.joelonsoftware.com/articles/Unicode.html ). If you think you know about these issues, reread the article (I am just going to). A considerable and avoidable amount of the garbage on the web is due to developers who did not understand. Cut-and-paste is almost a certain recipe for corruption. And since science relies on a modest number of high codepoints it is critical to get them right. A missing minus sign can cause planes to crash. A 1 instead of an L. An m instead of a mu (milligram vs micrograms) in a dose could kill someone.
In simple terms, PDF can manage an infinite number of fonts. This is fine for display, but unless we know what the characters *are* it’s useless for AMI2. We can treat fonts in 2 main ways:
- Send a graphical object representing what the character looks like on screen or printer. These are usally infinite scalable fonts and don’t degrade when magnified. But it is very hard for AMI2 to work out what a given sets of curves means as a character. (How would you describe a “Q” over the telephone and get a precise copy at the other end?)
- Send the number of the character (technically the code point in Unicode) and a pointer to the font used to draw it. That’s by far the easiest for AMI2. She generally doesn’t care whether an “A” is serif or not (there are some disciplines where fonts matter but not many). If she gets (char)65 that is good enough for her (with one reservation – she need to know how wide it is to work out when words end).
Anyway almost all of the characters have Unicode points. In our current test document, of 130 pages we’ve only found about 10 characters that didn’t have Unicode points. These are represented by pointers into glyph maps. (If this sounds fearsome the good news is that we have largely hacked the infrastructure for it and you don’t need to worry). As an example in one place the document uses “MathematicalPi-One” font for things like “+”. By default AMI2 gets sent a glyph that she can’t understand. By some deep hacking we can identify the index numbers in MathematicalPi-One – e.g. H11001. We have to convert that to Unicode.
** DOES ANYONE HAVE A TABLE OF MathematicalPi-One TO UNICODE CONVERSIONS? **
If so, many thanks. If not this is a good exercise for simple crowdsourcing – many people will benefit from this.
I’ve gone on a lot, but partly to stress how confident we are that we have essentially solved a standalone module. This module isn’t just for science – it’s for anyone who wants to make sense of PDF. So anyone in banking, government, architecture, whatever is welcome to join in.
For those of you who are impatient, here’s what a page number looks like in SVG:
<text stroke=”#000000″ font-family=”TimesNewRomanPS” svgx:width=”500.0″ x=”40.979″ y=”17.388″ font-size=”8.468″>3</text>
<text stroke=”#000000″ font-family=”TimesNewRomanPS” svgx:width=”500.0″ x=”45.213″ y=”17.388″ font-size=”8.468″>8</text>
<text stroke=”#000000″ font-family=”TimesNewRomanPS” svgx:width=”500.0″ x=”49.447″ y=”17.388″ font-size=”8.468″>0</text>/
That’s not so fearsome. “stroke” means colour of the text and 00/00/00 is r/g/b so 0 red, 0 green 0 blue which is black! Times is a serif font. Width is the character width (in some as yet unknown units but we’ll hack that) . x and y are screen coordinates (in SVG y goes DOWN the screen). Font-size is self-explanatory. And the characters are 3,8,0. The only reason we can interpret this as “380” is the x coordinate, the font-size and the width. If you shuffled the lines it would still be 380.
In the next post I’ll explain how early-adopters can test this out. It’s alpha (which means we are happy for friends to try it out. It *will* occasionally fail (because this is a complex problem) and we want to know where. But you need to know about installing and running java programs in the first instance. And we need to build more communal resources for collaboration.
Pingback: Setting-up AMI2 on Windows - Ross Mounce