I have been undertaking a slightly systematic analysis of what SpringerImages is. 2 days ago I was contacted by Springer(BK) in a phone conversation [1]. Note: I shall simply record the initials of the person that spoke or wrote to me as the conversation is symmetrically impersonal – they regard me as “Mr Peter Murray-Rust, Blogger” and I regard them as a legal commercial organisation, essentially no different from an insurance company, a gas provider or a train company. They are part of our capitalist society – I have no problem with that. I owe them roughly as much goodwill as I owe my bank. I trust them as much as I trust an airline company.
But for the most part they are not part of the scholarly community. Their CEO has implied as much – Springer’s Business purpose is to make money from selling to universities and others. (http://www.infotoday.com/IT/jan11/Interview-with-Derk-Haank.shtml ) They provide goods and services to it. They also hold IPR and sell or licence it to the scholarly community.
Springer(BK) asked me to explain in my blog what had gone wrong at SpringerImages. I said I couldn’t do this – I wasn’t responsible for the site and didn’t understand it and I asked Springer(BK) to explain it themselves. To my knowledge they haven’t done so. So here goes…
I have a major concern with SpringerImages, quite apart from the current “glitch”. Let me get the glitch out of the way, first. Due to what appears to be a computer problem of some sort (Springer have not clarified) some of my CC-BY work published in BMC was presented as being copyright BiomedCentral and relicensed under the more restrictive CC-NC licence. Matt Cockerill of BMC has assured us that this will be rectified. I trust Matt completely. Matt and many of his colleagues in BMC are valued members of the scholarly community. If the glitch were the only problem I would have ceased to blog this. NOTHING THAT FOLLOWS RELATES TO BMC OR MY WORK.
My concern is the concept and the implementation of SpringerImages as a whole. My position is similar to to what Klaus Graf said in 2009 (/pmr/2012/06/06/springergate-springerimages-for-today/#comment-108454 ) I reiterate that I do not know whether the “glitch” affects my current perception of SpringerImages, but that does not prevent me analysing it as it operates today – Springer can correct any assertions that are created by the glitch.
Since I do not wish to be continually asked to RETRACT “outrageous” statements I shall confine myself to FACTS, HYPOTHESES and QUESTIONS. The questions can be thought of as abstract examples of questions for students studying law or ethics, for example. I shall not offer answers to the questions, but if readers wish to I am happy to highlight their posts.
So, for example, Lawrence D’Oliviero asserts that the technical term for SpringerImages is “copyfraud” (/pmr/2012/06/06/springergate-springerimages-should-be-closed-down-until-they-mend-it/#comment-108471 ). I cannot possibly agree or disagree as this would be “outrageous”, but I can ask a Question, such as
QUESTION. Explain the term “Copyfraud” (you may quote from references in Wikipedia ((http://en.wikipedia.org/wiki/Copyfraud ) with attribution) [10 marks] . Does copyfraud extend to scholarly publishing? [20 marks]. Note: be careful not to make assertions about individual publishers unless they have been tested in court.
So in the absence of Springer(BK)’s contribution I will give a brief, informal, almost certainly incomplete and occasionally incorrect overview of SpringerImages
SpringerImages contains 3.4 million objects (mainly images,tables, line art, video, etc.). Here’s a screenshot (NB I am publishing these screenshots without asking permission as I think it’s in the public interest).
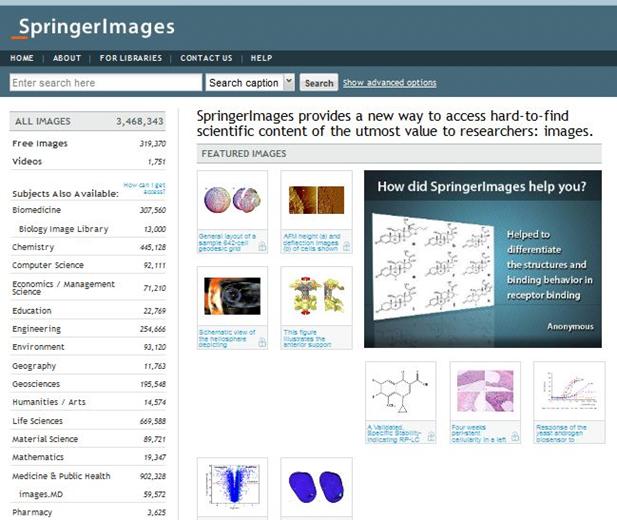
I’m going to use exactly what I see – I haven’t selected. What’s the basis:

Springer do not say where these images come from. In some informal discussion Springer(BK) asserted that the content only came from Springer Books and Springer journals. I will continue on this basis, but I would appreciate confirmation (there appeared to be occasional items from other commercial publishers, but I wouldn’t know).
“Springer only distributes content it legally owns or for which it has been granted distribution rights”. Since Springer says so it must be a FACT, and hence Springer must have redistribution rights to the material that I have shown in previous posts.
“Images … can be used for almost all non-commercial purposes”. I shall test this.
Which images are Free? It’s unclear. If I click “free images” I get ca 300K results. So I assume that about 10% of the site is “free” (whether in beer or speech I don’t know). I’ll assume 10% that as Springer(CEO) said that they didn’t see OA going above 5%. I click on the first free image, it’s copyrighted by BMC and distributed as CC-NC (presumably this will be corrected to “the authors and CC-BY when the glitch is gone). No problem. Let’s look at the rest
So here’s an image from the current page.
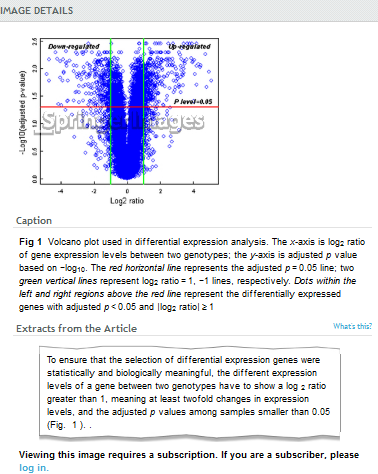
So it’s presumably from an article? Which article? I have no idea – So presumably I can’t see the article details unless I subscribe (USD 600). So to decide whether I want it I have to invest quite a lot.
OK lets’ assume I lecture on volcano plots and this is a wonderful example. Can I get permission to use it in my lecture?
I am not a subscriber, but maybe I can get it for “non-commercial purposes”. Such as “teaching?”. I ask for a quote (expecting to be told it’s free)
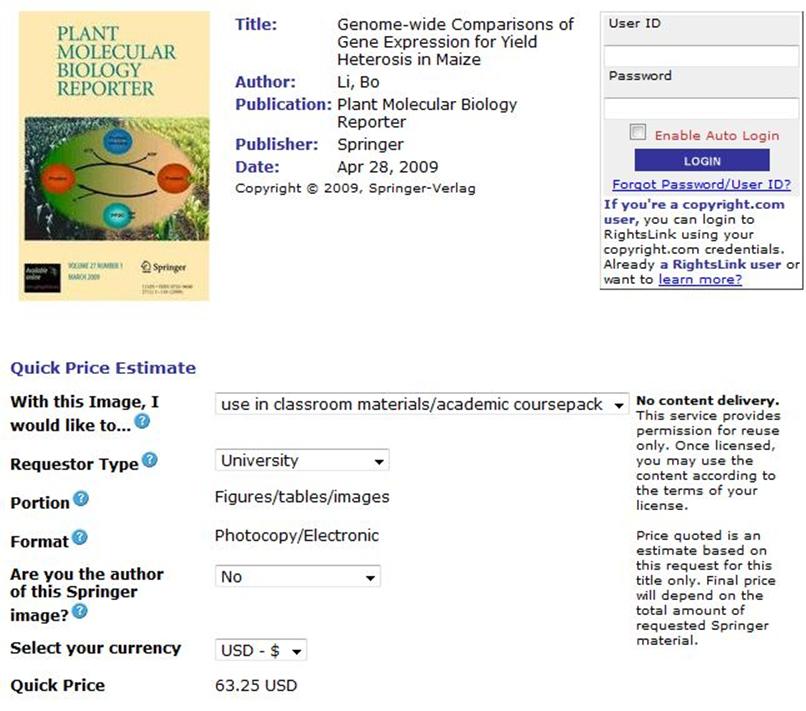
So sorry – teaching is a commercial activity. BTW this is the first time that SpringerImages appears to have given an attribution to the images. So a handy hint – if you want to find out which article something was taken from pretend to buy it for teaching and it may tell you.
Some authors naively assume that if they have published something then it can be easily re-used for teaching. No! everything you publish is claimed by Springer and resold. If I wanted all the images in this single article, it could cost hundreds of dollars (even though I am sure there would be a generous discount).
So now I want to see the data. Perhaps they are in tables. Let’s go to one. The caption of the table is “Validation of 19 differentially expressed genes by qRT-PCR”. What’s the contents of the table? I’d have thought it was the actual data. But the “IMAGE DETAILS” are a GIF which reproduces the words in the caption. So presumably I can’t see the actual table contents unless I subscribe (USD 600). So to decide whether I want to see this table I have to invest quite a lot.
So my summary:
- It’s quite difficult for a typical “Mr Peter Murray-Rust, Blogger” to understand the site.
- I wouldn’t dare to criticize it for technical quality. I would have expected images to link directly to the article, but … I’d also have expected tables to display their contents (or at least part of them).
- Almost all the site (> 90% seems to be commercial /non-free whatever term. To make much use of it, it looks like you have to pay USD600 to subscribe
And:
ALMOST EVERYTHING YOU PUBLISH IN A TOLL-ACCESS SPRINGER JOURNAL IS LIKELY TO END UP IN SPRINGER-IMAGES, BE COPYRIGHTED BY SPRINGER AND BE RESOLD FOR SIGNIFICANT AMOUNTS OF MONEY.
And, of course, Springer has carefully checked the rights to every item and respects the rights of every item that it doesn’t “own”. It only copyrights those items it has the right to do so. It says so, so I have to believe it.
Unless you tell me different.
I shall be contacting some of the apparent rights holders and asking to see whether they have given Springer permission to copyright their material, rebadge it as Springer images and resell it. I am sure they will confirm that they have agreed this with Springer. And of course I’ll let this blog know.
Unfortunately I seem to have found an awful lot of people and organizations I am going to have to write to. I’d appreciate some help…
[1] (Note: I inadvertently confused Springer.com with springerpublishing.com – from now on I shall refer only to springer.com – a phrase which includes the many subsidiary companies).
Mr. Peter Murray-Rust, Blogger
http://archiv.twoday.net/stories/97051288/
Doesn’t all this imply that PLoS is the only scientific publisher we scientists can really trust (and should support)? This is not a rhetorical question. I am genuinely wondering
[I assume your second Q was a keypress error?]
I agree – the issue of trust is critical. It’s ultimately what publishers are selling (in principle anyone can manage the rest – typesetting, physical publication).
There are several areas of trust. Trust that the journal exist and is run reputably. I think that’s true for most major publishers (of course there’s Elsevier’s fake journals, Chaos/Solitons/Fractals, etc but I think these are fringe effects). Like others I am slightly worried about Open vanity journals.
Trust that the current publishing industry is working in the interests of scholars? Declining rapidly.
Trust that the industry is keeping costs and profits to a minimum. Not a chance.
Trust that the industry works together to reduce costs, create better metadata and interoperability. No way.
Trust in the publishers’ associations to provide a balanced view of what publishing should be? No.
Trust in the absence of dirty political tricks? Like PRISM? No chance. It will get dirtier.
Trust in the industry not to take advantage of universities and their librarians. No.
Trust in the purity of the review process? Certainly not for the glamour journals.
Trust in avoiding lock-in to walled gardens? It will get worse.
Trust in general competence? Highly variable. Many do a good job and may screw up.
There are lots of publishers I trust in certain aspects. Of the ones that genuinely have the community interest at heart I’d put certain society publishers (e.g. IUCr, EGU, ASBMB – there are many more that I don’t know). But not all – and the ACS is a clear example of a publisher that indulges in practices that harm the community. All organizations get hardened arteries with age – the most venerable societies can be very conservative. BMC is reasonably young – was created to change publishing and has done a good job. PLoS is truly revolutionary and scores well on most things. It will have to work hard to maintain its youth. eLIFE – we have yet to see. Wellcome is truly revolutionary.
If you have the choice then I would always look at PLoS, BMC and eLIFE. This isn’t so much a questions of trust as a belief in changing the system.
Agreed, but by publishing in BMC aren’t you financially supporting Springer?
Yes – and that’s tricky.
I differentiate between refusing to provide Springer with voluntary services (refereeing, editing, authoring) and doing this for BMC. I am not at the stage where I would actively campaign to destroy an publisher financially, though who knows about the future.
I keep this under review – this week Springer has gone down in my standing.
Peter, another way to find the source of an image, with a good success rate, is to google its caption.
Thanks,
Highlights the role of Google and other search engines, which presumably index the closed literature. And academics are not allowed to index the literature they subscribe to!
Pingback: Unilever Centre for Molecular Informatics, Cambridge - #ami2 liberating science; more SpringerGate: I have to ask their permission to re-use CC-BY 2.0 « petermr's blog