#semphyssci
Marcus Hanwell (Kitware) reported from the #semphyssci working group which was looking at how to grow the development and use of CML in the community. One of the great excitements of the Workshop is the agreement among participants that CML is valuable, worth developing and that they will put the effort in to make it happen.
There are several ways to develop a successful information infrastructure:
- Commercial entrepreneurship, typified by Gates and Jobs – and also Google and Facebook. Build the products that people want and sell them. Failure is common, but the market doesn’t care WHO succeeds.
- Design by committee. In many cases this works. CIF, W3C are committee-based, managed, successful. Failure is often common, normally because committees are very slow. I’ve sat on ISO committees – nuff said. It’s very difficult to get innovation.
- Benevolent Dictator For Life (BDFL). Linux, Python are examples of this. It depends crucially on the energy, vision, political skills, etc. of the BDFL.
-
Leaderless meritocracy. Almost always requires an oligarchy of small number of hardworking, disciplined, drivers. Overlaps with (3).
A common model is for a BDFL to create an initial prototype and then for (1) or (2) to take some role – either complete or partial.
Henry and I have been BDFL for CML for nearly 20 years. We’ve never wanted to be self-important and so much of the work has been low-key. Unlike ICT where new developments are welcomed both in terms of new ideas and new markets, chemistry regards new ideas with suspicion. There’s a large chemical information industry (content and software) which is almost completely out of touch with the 21st Century. There’s a few sparks, but most are based on the concepts of possessing content and building walled gardens, and of developing monolithic applications. Both are failing. But so far almost no interest from the chemical information market in semantics. The result is that we have had to build the ecosystem ourselves.
Now it’s changing. This meeting #semphyssci has shown that there is not only a desire for the CML ecosystem, but also a willingness to develop it. That’s why I invited the National Laboratories to this meeting and I’d like to congratulate them on their commitment. The mechanisms are yet to be worked out but I have no doubt it will happen.
An aside: Four years ago I went to CERN (/pmr/2008/01/29/big-science-and-long-tail-science/) to talk to Salvatore Mele about open access publishing. SCOAP3 (http://scoap3.org) would cost some tens of millions of dollars but change the model of publishing to a scientist-centered one, rather than a publisher-centered one. Salvatore took me to the Large Hadron Collider, pointed to a hole 100 metres deep and said “last week we lowered 500 million Euros worth of instrument down the hole. We know how to make large projects work” (with the implication that open access was only a middle-sized project).
I have already welcomed Marcus and Kitware’s commitment to Open Source, Open Access and collaborative models of information infrastructures. These will inevitably triumph and the current ecosystem will adapt or die. Even their lawyers will not be able to enforce sustainability – the market will simply move on. And CML will be part of the new market. Because that’s a central part of the new market – free flow or raw data and ideas, managed by semantics.
And CML is currently the only system which supports chemical semantics across the major subdisciplines – especially in this context spectra, computation and solid-state.
Marcus coordinated the working group on the vision and ecosystem of CML and here’s his presentation http://vimeo.com/35400550. I have snipped from this – I think it’s rather fun compared with just the flat presentation of slides!
0:00 overview and value of CML

1:15 creating CML ecosystem



4:45 Resources for developers using CML

6:50 End-user applications (maybe whitepaper)
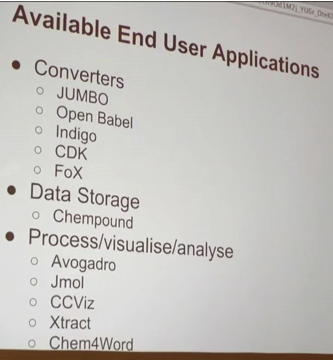
8:20 wish list for new tools

9:20 Features of community

10:20 future meetings
11:00 exercise in validation
Great post Peter, it was great to be part of this meeting and I am excited about the future. This meeting really helped clarify where we want to get, and you managed to get the right people together to help us all get there. I really like the format of the post too.
Pingback: Marcus D. Hanwell's Blog