#oscar4
As we’ve said OSCAR4 is a set of library components that can be reconfigured in many ways (rather than a single monolithic application). On Wednesday (in Cambridge or remotely) we’ll be looking at how to bolt the bits together. We’ll make a Java IDE (Integrated Development Environment, such as Eclipse, Netbeans or IntelliJ )available to participants. (Actually this is probably the hardest part of the whole thing – getting your environment working.)
Now you have to get OSCAR4 from https://bitbucket.org/wwmm/oscar4/. It’s managed by a system called Mercurial which looks after what to download and how to configure it on your system. Create a directory on your system and download OSCAR4 (Bitbucket even tells you how:
hg clone https://petermr@bitbucket.org/wwmm/oscar4 )
When you’ve done that you’ll find a series of directories representing the main sub-projects in OSCAR (which hopefully have meaningful names):
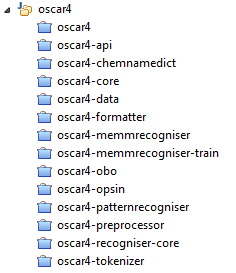
(Exactly how this displays will depend on the options in your API).
OSCAR4 provides the simplest options through the oscar4 package. We use the “convention over configuration” approach http://en.wikipedia.org/wiki/Convention_over_configuration . What’s that? Basically this says that you create default actions, default naming conventions , etc. so that you can run the system as easily as possible and get the most useful results. If you want something more sophisticated you change the configuration. Here’s the structure:
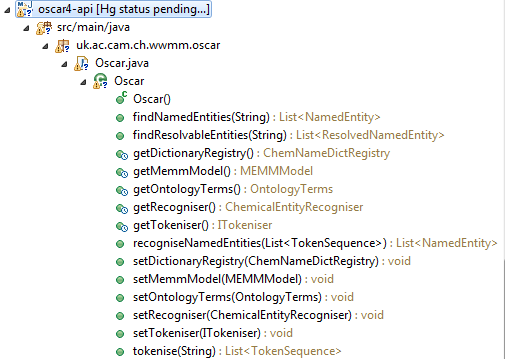
The main class is Oscar (actually uk.ac.ch.wwmm.oscar.Oscar) and it has a series of methods. This is not as bad as it looks. The get methods (getters) and the setters can be ignored for now (because we will use the default). So this leaves us with only 4 methods we might use. Here’s the most important:
/**
* Wrapper method for identification of named entities. It calls the methods
* normalise(String), #tokenise(String), and #recogniseNamedEntities(List).
*
* @param input the input text.
* @return the recognised chemical entities.
*/
public List<NamedEntity> findNamedEntities(String input);
Note that this already calls tokenise() and recogniseNamedEntities(List). So we don’t need to worry about these at first reading. The final method is:
/**
* Wrapper method for the identification of chemical named entities
* and their resolution to connection tables. It calls the methods
* normalise(String), tokenise(String), recogniseNamedEntities(List), and
* ChemNameDictRegistry.resolveNamedEntity(NamedEntity)
*
* @param input String with input.
* @return the recognised chemical entities as a List of ResolvedNamedEntitys,
* containing only those named entities of type NamedEntityType.COMPOUND
* that could be resolved to connection tables using the current dictionary registry.
*/
public List<ResolvedNamedEntity> findResolvableEntities(String input);
So, if we understand the meanings of the nouns this is almost English prose. Identifying Chemical Named Entities is the primary purpose of OSCAR4. Normalising the string is necessary, but we’ll trust OSCAR. Tokenization is splitting the sentence into words (not necessarily just at spaces). And The ChemNameDictRegistry is a registry of ChemNameDicts. These are dictionaries mapping chemical names to structures (e.g. “methanol” -> CH3OH). So, in this case instead of returning namedEntities, we resolve them into Structures before returning.
Simple?!
So the first exercise is:
/**
* Use the Oscar API class to identify named entities in
* the text string below. Print each to the console.
*/
public static void main(String[] args) {
String text = “Ethyl acetate and acetone both contain the carbonyl group.”;
//TODO Implement your method here!
}
To get you started, I mention that you have to create an OSCAR, and then select the appropriate method:
OSCAR oscar = new OSCAR());
oscar.doSomething(argument);
and that’s all there is to it…