I am writing a parser for the #quixotechem project – in this case NWChem output. The output is generated AFAIK by FORTRAN. I am having difficulty parsing it. Why?
Here is some text I can parse (deliberately a snapshot from a text processor):
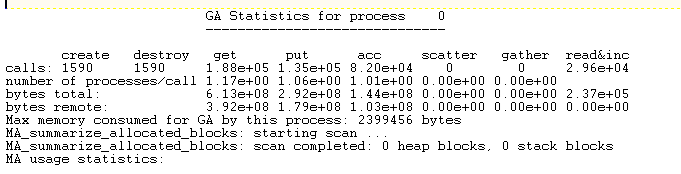
And here is the evil output:
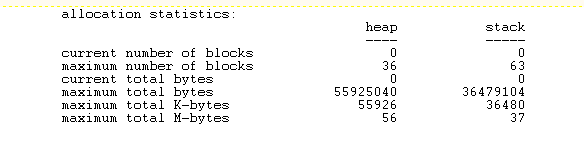
What unexpected horror (or semi-unexpected, as I’ve had it before) has caused me to waste a lot of time?
EDIT:
Here’s a very strong hint. This is what I get when I load it into my text editor. Whatever has happened? And what could I do to make it at least human readable?
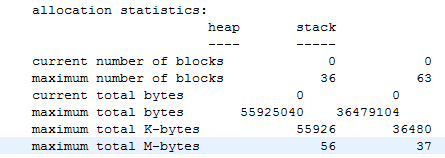
And what piece of code did I have to write last night to solve the problem in future?
Pingback: Tweets that mention Unilever Centre for Molecular Informatics, Cambridge - There are other evils than PDF: what’s the problem here? « petermr's blog -- Topsy.com
These “how did I go wrong” puzzles are always a bit tricky. Perhaps your was doing it in C#?
The field width is not clear in the “evil” output…?
Thanks for comments. The language is irrelevant – this horror could have been committed in any language
Aghh! tabs! Will the evil never cease.
Amusingly, and further illustrating the point, your post looks completely different in Google Reader (RSS) and on the web (HTML).
I agree with Dan Hagon (below): Regular expressions are better for parsing this sort of stuff, even if it looks fixed width.
Disappointed to discover that my favourite language, Python, doesn’t have a really easy “untabify” module / function / IOWrapper.
Tabs are evil / fixed column output is evil / Fortran is evil. We knew that.
@David: Re Python, not sure what you need for untabify, but I regularly use .split() on strings, or you could .replace(“\t”, ” “).
Well, something that would make the unix utility “expand” a one-liner in Python. And that’s not «’ ‘.join(foo.split())»
Two questions: what character encoding is the file written in and are those whitespace characters (a) spaces, (b) tabs, or (c) just simply unprintable? If I were parsing this I’d use a regex such as “^(\w+\s)+(\d+)\s(\d+)$” and select groups 2 and 3. I’d dump the resulting data into a structured file format such as XML and make it human-readable by providing an XLST style sheet that displays the data as HTML.