#beyondthepdf
THIS REPRESENTS AN INTERACTIVE PRESENTATION TO https://sites.google.com/site/beyondthepdf/ ON 2011-01-20. The large letters are for projection
IF YOU WANT TO ASK QUESTIONS OF US IN THE BtPDF SESSION USE THE ETHERPAD:
http://okfnpad.org/quixote20110120
Just go to this page and give your name. Don’t go in unless you want to ask a question – I will be showing the site
===========================================================
This post tries to practise http://en.wikipedia.org/wiki/Eating_your_own_dog_food (Wikipedia)

rather than using Powerpoint (Power corrupts; Powerpoint corrupts absolutely. this kills kittens)

(used with thanks http://ilovecharts.tumblr.com/post/450388944/brownpau-everytime-you-make-a-powerpoint and probably violating copyright – not fair use but funny).
In case you are still reading I shall use this blog to present my message. Not “slides” but communication by “writing” – a form of linear communication. I’ll try to make this a “conversation” in places
“All Science is hypothesis-driven”.
No. Lots of it is data-driven. Part measurement and observation; Part computed. The result is data which can (and often is) published for its own sake. The fourth paradigm. Problem is:
- Many scientists are arrogant about data publication
- Many publishers can’t be bothered. Many that are bothered sell our data back to us (ACS, Elsevier are examples in chemistry).
OK – but data is hard, so it’s too expensive to do. All that collecting, standardising etc.
No it’s not. Vannevar Bush proposed the Memex (1948) to remember everything we do.
But that’s impossible
No – it’s possible it we wanted to do it. We make it a way of life and it becomes tractable
Hmmmm
We’re already doing it. I’ll show 3 projects. Based on communities. Not how can I do this, but who wants to work with us.
But that means you work with your competitors!!!
I don’t have competitors. Just apathetics. Anyway here’s the projects. They are all ZERO cash.
???
They aren’t funded – they work with volunteer resources and marginal cpu+bandwidth+storage. Like Galaxyzoo. Open Streetmap. All results are O-P-E-N. Licensed with PDDL or CC0.
- crystallography (Crystaleye). Goes out every night and crawls the scientific literature for crystallography. 200,000 separate structures. Pulls back data files (CIFs) indexes, validates and provides domain search. Sustainablity with IUCr.
- chemical reactions (Greenchain reaction and results ). We trawled the patent literature for c hemical reactions. 100,000 . Hypothesis: reactions are getting greener (extract the solvents)
- and compchem (Como (example) and Quixote).
But Crystaleye only has half the literature…
…Yes, because Wiley, Elsevier and Springer don’t publish Open supplementary info.
Well, just ask them…
…I have – several times. They never reply. Readers don’t matter.
Stop ranting…
… sorry.
So were the reactions getting greener …
… not that I could tell. But we’ll do another run.
But patents are grotty. Designed to conceal information. Why don’t you use the published literature? There’s 10,000,000 reactions reported…
… answer it yourself
Oh, I see. Only 1,000 are Libre Access…
… you’re getting the message
And Quixote. Why the name?…
… because PMR has mad expectations. And because it started in Spain…
So what makes it different?
… well NO-ONE publishes comp chem data. And it’s the easiest and best data of any discipline. The laws of physics work. So we will scrape scientist’s disks and convert them to semantic
You’ll have to give them the program…
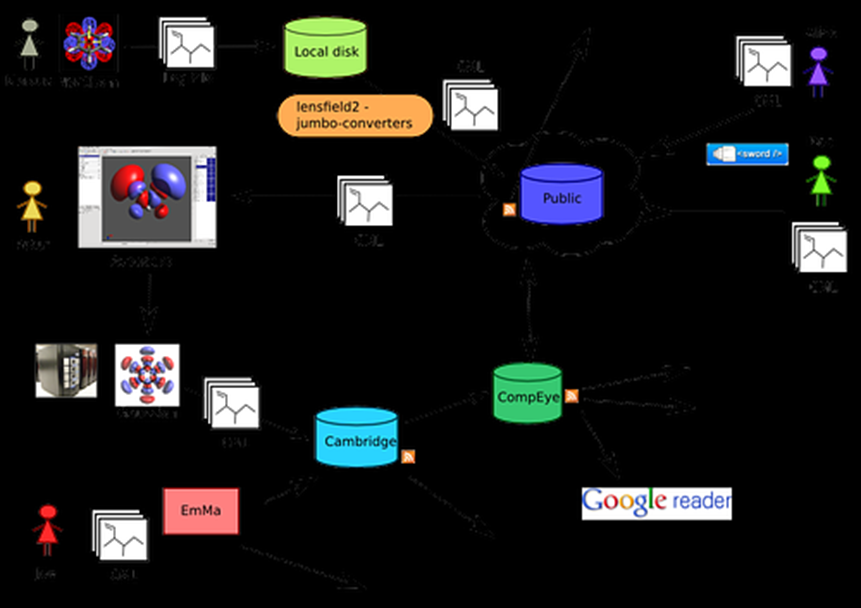
… Yes we’ll let them use Avogadro. It’ll front up all the tough stuff. It’ll act as a computational Memex.
…Heres Quixote. Also
I don’t like the black background…
… it isn’t black. It just looks black. Browsers have a little way to go – see http://quixote.wikispot.org/Front_Page?action=Files&do=view&target=workflow.png
Pingback: Peter Murray-Rust on open data-Part 1 | Naturally Selected