#quixote #jiscxyz
Many of the ideas that we’ve had on the World Wide Molecular Matrix are now starting to become possible. In my innocence in 2002 I thought that imaginings were one step from reality. The bits in between were so easy to conceive that they wouldn’t take much time.
They’ve taken 10 years
However I can look back and find that many of the ideas are pretty much unchanged.. Here’s a picture crafted at least 5 years ago which describes different types of site (server) in the WWMM. The details aren’t important.
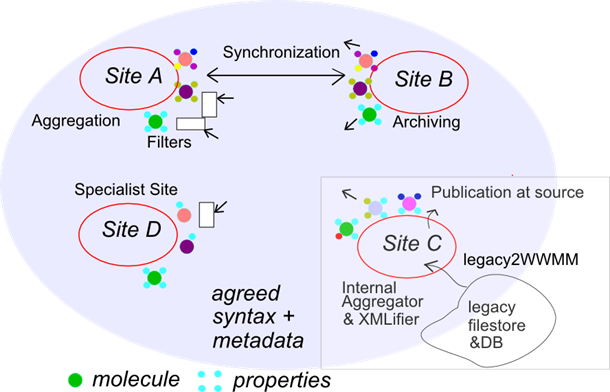
It’s the technology that has risen up to meet them. And the general acceptability within the community. Back then it was WSDL and UDDI (imagine that!), oh and SOAP. And Portals. It’s taken courage to strip all that away and go back to the simple ideas. REST, schema-less designs, flexible vocabularies.
But most of all that the whole system is Open. I hadn’t realised back then how much of a drag AAA was. Authentication, Authorization, Accounting. They kill projects. Much of the eScience program was struggling with these monsters.
Of course if you want to transfer money between banks you need this. That’s why we pay bankers enormous salaries and bonuses. But for Open science we don’t need anything. A few social controls. Keep the spammers and wreckers out. Make sure people don’t DOS the system.
So Sam Adams has planned all this and I’m convinced his design is what modern eScience should be. (We also owe a lot of this to Jim Downing). All the bits are there. We need the following sorts of server (they not quite what is in the picture, but share the general idea):
- One that allows scientists publish their data to the Open web. Pablo Echenique has already done this in the Quixote project. But not everyone is allowed to run a server.
- A server to which anyone can upload. Anyone who is not a spammer. Sam will tell us how that can be done easily
- A server that scrapes the exposed web. This is can Pablo-type, or journals or anything. Even Institutional repositories if they expose an iterator over the data (which most do not). Its results are exposed and read-only. It offers search and indexing
- A customisable repository with embargo. Chem#, pronounced Chempound. It’s the results of several JISC projects – SPECTRa, CLARION, JISCXYZ and it’s coming together now. A few bits to come but RSN. It will allow people to store their data responsibility while they need it and archive it later
The WWMM is not restricted to molecules. The architecture will handle anything that’s semantic. It hates PDF. It hates Powerpoint (unless in XML). It likes anything in text and in XML. It’s not wild about images yet. The day will come shortly when images are semantic.
And you if you want to find out more, just join the Quixote list ( quixote-qcdb@googlegroups.com ). You don’t have to be a chemist. You just have to enjoy seeing Open scientific data.
quixote-qcdb@googlegroups.com ). You don’t have to be a chemist. You just have to enjoy seeing Open scientific data.