Typed into Arcturus
I’m in Bath for a JISC meeting – the I2S2 meeting. All JISC meetings have acronyms – I2S2 stands for Infrastructure for Integration in Structural Sciences and involves a number of experimentalists in finding the structure of materials (More on the I2S2 project at its website: http://www.ukoln.ac.uk/projects/I2S2/) . For example Martin Dove (from Earth Sciences in Cambridge) is looking at how atoms in silicates move, and how this changes the structure of minerals. Since much of the Earth’s crust is made of silicates this is of importance in understanding tectonic movements, exploration for minerals, etc.
Here’s an example of the multidisciplinary nature of science – to find out what happens hundreds of kilometres (10^5 meters) deep in the earth we have to understand how atoms behave at the picometer scale (10^-12 meters). So there is a factor of nearly 20 powers of ten – and it’s remarkable how often the very small and the very large interact.
Martin collaborates with Rutherford laboratory near Harwell run by STFC. Martin uses neutrons to determine how the atoms move and needs a special “facility” (ISIS) to do this. Here (http://www.isis.stfc.ac.uk/instruments/instruments2105.html ) are some of the many projects at ISIS which include wsays of improving mobiles phones, mediacl diagnostics and much more. Science underpins our modern life and however we are to escape from our present plight we must see science at the centre. It’s something that the rest of the world admires in the UK.
ISIS produces DATA. And that’s what the I2S2 project is about. The data is expensive to produce (neutrons are not cheap) and the data are complex. STFC also has a large resource in developing new approaches to information and Brian Mathews from STFC is therefore also on the project.
This is “large science”. But I2S2 also covers “long tail” science – where lots of science is done by individuals. Simon Coles runs the National Crystallographic Service in Southampton where hundreds of researchers submit their samples and his group “solves the structure” and returns the data. Here the data are likely to be in hundreds of separate packages.
What’s characteristic of these projects is that the data often drive the science. So managing the data is critical. And we’ve just been talking about problems of scale. If we get 10 times more data then the problem becomes intrinsically more difficult – it’s not just “buying another disc”. New bugs arise and integration issues become essential.
So I2S2 is looking to see whether there can be a unified approach to managing data. This requires an information model, because only when we understand the model can we create the software and glueware to automate the process. This is not easy even when “most of the experiments are similar”. It needs expert understanding of the domain and a vocabulary (more technically an ontology) for the data and the processes. Moreover it’s not a static process – we often keep refining the processes in transforming and managing data.
And the result of experiment A is often the input for project B. So the process is often shown as cyclic – the research cycle. A key concept id “data reuse” – in this area ideas often build on existing data (which is why I and others keep banging on about publishing data). Here’s a (relatively simple!) diagram for the research cycle in I2S2:
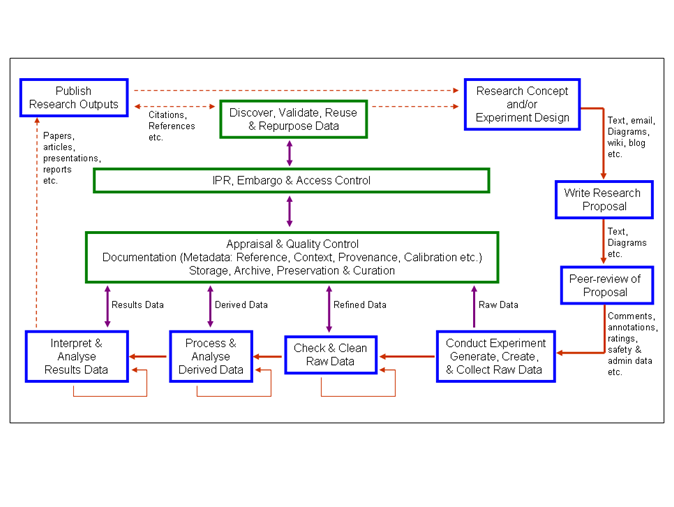
Note the cycle round the outside. Start at the NE corner. Not everyone maps their research in precisely these terms but most do something fairly similar. The data-intensive part is mostly at the bottom. Data are not simple – usually the “raw” data need processing before being interpreted. For example an experiment may collect data as photons (flashes of radiation) and these need integrating locally. Or they need transformation between different mathematically domains (“Fourier transform”). Or they are raw numbers from computer simulations. It’s critical that any transformation is openly inspectable so that the rest of the world does not suspect the authors of “manipulating their data to fit the theories”. That’s one reason why it’s so important to agree on the data transformation process and that anyone (not just scientists) can agree it has been done responsibly.
This is a microcosm of science – data is everywhere – and all of those projects will be thinking and acting as to how their data can be reliably and automatically processed. Because automation gives both reproducibility and also saves costs.
So when scientists say they need resources for processing data, trust us – they do.
-
Recent Posts
-
Recent Comments
- pm286 on ContentMine at IFLA2017: The future of Libraries and Scholarly Communications
- Hiperterminal on ContentMine at IFLA2017: The future of Libraries and Scholarly Communications
- Next steps for Text & Data Mining | Unlocking Research on Text and Data Mining: Overview
- Publishers prioritize “self-plagiarism” detection over allowing new discoveries | Alex Holcombe's blog on Text and Data Mining: Overview
- Kytriya on Let’s get rid of CC-NC and CC-ND NOW! It really matters
-
Archives
- June 2018
- April 2018
- September 2017
- August 2017
- July 2017
- November 2016
- July 2016
- May 2016
- April 2016
- December 2015
- November 2015
- September 2015
- May 2015
- April 2015
- January 2015
- December 2014
- November 2014
- September 2014
- August 2014
- July 2014
- June 2014
- May 2014
- April 2014
- March 2014
- February 2014
- January 2014
- December 2013
- November 2013
- October 2013
- September 2013
- August 2013
- July 2013
- May 2013
- April 2013
- March 2013
- February 2013
- January 2013
- December 2012
- November 2012
- October 2012
- September 2012
- August 2012
- July 2012
- June 2012
- May 2012
- April 2012
- March 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- September 2011
- August 2011
- July 2011
- May 2011
- April 2011
- March 2011
- February 2011
- January 2011
- December 2010
- November 2010
- October 2010
- September 2010
- August 2010
- July 2010
- June 2010
- May 2010
- April 2010
- August 2009
- July 2009
- June 2009
- May 2009
- April 2009
- March 2009
- August 2008
- July 2008
- June 2008
- May 2008
- April 2008
- March 2008
- February 2008
- January 2008
- December 2007
- November 2007
- October 2007
- September 2007
- August 2007
- July 2007
- June 2007
- May 2007
- April 2007
- December 2006
- November 2006
- October 2006
- September 2006
-
Categories
- "virtual communities"
- ahm2007
- berlin5
- blueobelisk
- chemistry
- crystaleye
- cyberscience
- data
- etd2007
- fun
- general
- idcc3
- jisc-theorem
- mkm2007
- nmr
- open issues
- open notebook science
- oscar
- programming for scientists
- publishing
- puzzles
- repositories
- scifoo
- semanticWeb
- theses
- Uncategorized
- www2007
- XML
- xtech2007
-
Meta
More on the I2S2 project at its website: http://www.ukoln.ac.uk/projects/I2S2/