We’ve mentioned CrystalEye frequently on this blog but not announced it formally. We were about to post it about three weeks ago but had a serious server crash. Also we are very concerned about quality and want to make sure there as as few bugs as possible (there will always be bugs, of course). But now here is a formal announcement. The work and the site has all been done by Nick Day (ned24 AT our email address). I am only blogging this because Nick is too busy using the data for research and hoping to get enough results by the end of the academic year.
We believe that this is one of the first resources in any discipline created and continued by robotic extraction of data from primary publications and re-published for Openly re-use. Every day a spider visits the sites of publishers who expose crystallographic data, downloads it, validates it, etc. Here’s a schematic diagram:
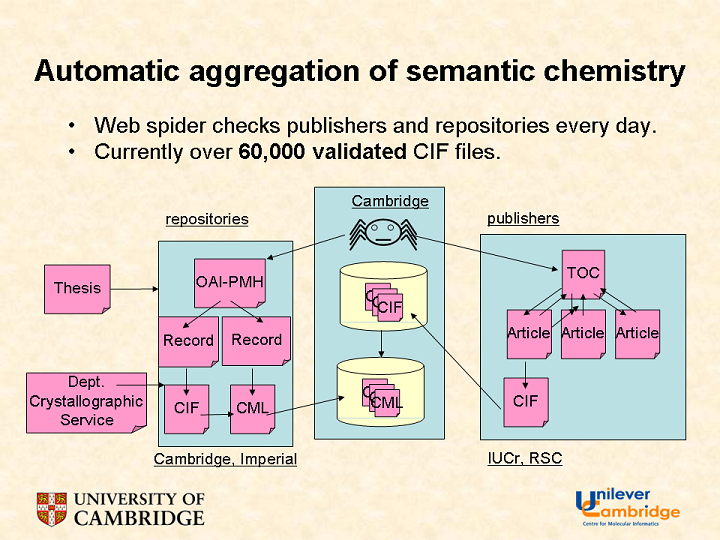
This post stresses the right-hand site – the systematic scraping of data from publisher sites and the left hand side shows we can also do it for theses (The SPECTRa-T project). That’s still in its infancy but at least it’s within academia’s control (as long as they don’t give away the right to control theses).
CrystalEye adds a LOT of validation. The central part above expands to a detailed workflow:
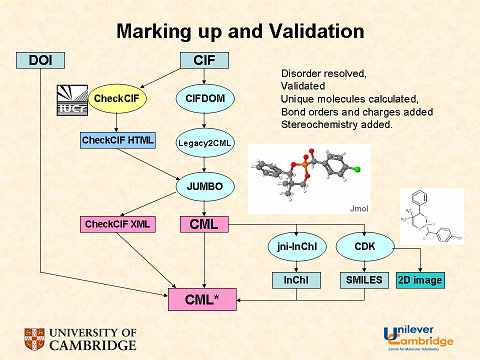
We are generating individual 3D molecules, 2D diagrams, InChIs and HTML – and none of this is available in its raw form on the publisher site. Remember that we are simply taking the raw data from the author – untouched by publisher. So we are adding a great deal of value without infringing any rights
There’s a lot more to say about CrystalEye. So read the FAQ. But we’ll be back and explain how it changes the face of secondary publishing. We simply don’t need humans retyping the literature.
Now if you are a publisher (or editor employed by a publishing house – I have to watch my terminology) this post will probably cause one of the following reactions:
- This is really exciting. How can we help the development of cyberscience? We could benefit from a whole new market.
- This is an appalling threat. The scientists are stealing our data. How can we stop them?
If you are not in the first category you are in the second. “This is boring”, “data isn’t important, only full-text matters”, “we can’t afford to be involved”, “let’s wait for 10 years and see what happens”. So I am gently inviting the publishers to tell me whether they will help me or prevent me use their data for cyber-science.