As I have shown it is hard and lossy to recover information from theses (or anything else!) written in PDF. In unfavourable cases it fails completely. I have a vision which I’ll reveal in future posts, but here I’d like to know how you wrote, write (or intend to write) your theses. This is addressed to synthetic chemists, but other comments would be useful. I have a real application and potential sponsorship in mind.
Firstly I guess that most of you write using Word. Some chemists use LaTeX (and Joe, who is just writing up) told us that the most important thing he would do differently when he started his PhD would be to use LaTeX). I would generally agree with this, although I am keen to see – in the future – what can be done with Open Office and Open Document tools which will use XML as the basis. The unpredictable thing is how quickly OO arrives and what authoring support it has.
A main reason for using Word is that it supports third-party tools whose results can be embedded in a Word document. The most important of these are molecular editors (such as ChemDraw (TM) and IsIsDraw (TM)). These are commercial products and have closed source. They also generally use binary formats which are difficult to untangle. (When these formats are embedded in Word they are impossible to decode – the Word binary format is not documented and efforts to decipher it are incomplete). In some cases I could extract many (but not all) of the ChemDraw files in a document. There are also MS tools such as Excel.
I’d be interested to know if OO and/or the release of MS’s XML format has changed things and what timescales we can reasonable expect for machine-processable compound documents. But for the rest of the discussion I’ll assume that the current practice is Word + commercial tools. (In later posts I shall try to evangelise a brighter future…)
The typical synthetic chemistry thesis contains inter alia :
- discursive free text describing what was done and why
- enumerated list of compounds (often 200+) with full synthetic details and analytical data.
The free text looks like:

============ OR ===========
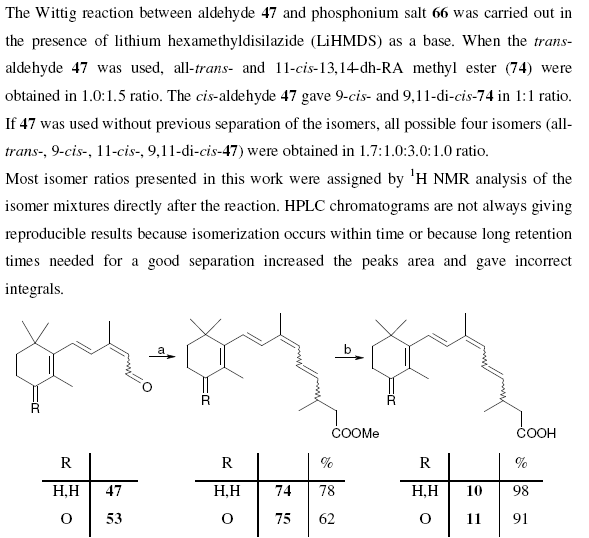
===== the compound information looks like ========
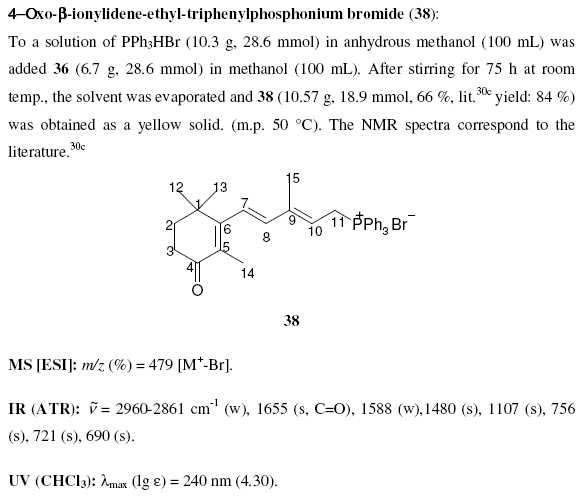
Note that compounds are identified by a bold identifier ( e.g. 38) which normally increases in serial order throughout the text. This is fragile, in that the insertion of a new number requires manual editing throughout the text (this is confirmed by various chemical gurus). Compounds are drawn in the middle of free text sections, and again in the compound information. There are no tools to enforce consistency between the numbering and the diagrams. Moreover information such as reagents, yields, physical and analytical data are repeated in several places. These have to be manually transcribed and (unless you tell me differently) this is a tedious, frustrating and error-prone process.
Moreover at this stage of writing the thesis the student has to assemble all the data for the 200 compounds. Are they all there? Could any of the spectra be muddled? Is that figure in the lab book a 2 or a 7? Heaven help if a spectrum is missing and the compound has now decomposed into a brown oil or got lost in the great laboratory flood. Of course none of this ever happens…
So are you all happy with how you authored or will author your thesis? I haven’t even touched on how peaks are transcribed from spectra and how the rigmarole of spectra peaks has to be authored and formatted. If so, I’ll shut up. Else I will make some serious and positive suggestions in a later blog.
Peter – a thesis is one of the few places where you can record a lot of your failed attempts to make or do something (at least I did in mine). Well maybe failed is not the best word because something was learned from each experiment. But it doesn’t fit neatly into A + B reacted to give C. Is that something that you eventually want to index (all the ways how NOT to make a compound)? As you know my students will write their thesis from the experiments they publish on our UsefulChem wiki. Feel free to use our data as a test case. We can certainly modify the way we record our experiments to make it more convenient for you to extract info. We recently figured out how to get our H NMR spectra in JCAMP format and now publish them using JSpecView – that kind of thing should help with automation.
(1) Thanks J-C. Your ideas are absolutely mainstream as far as I am concerned! I am particularly conscious of “unsuccessful” which I am specifically marking up in chemistry theses. I also can, in principle, deduce a non-event:
blahblah A
B (25mg) blah blah NaOH (10mg) blah blah blah gave A (15%)
represents a successful synthesis of A. I am working on understanding the blah, but the topology says A and NaOH reacted to B
blahblah A
B (25mg) blah blah NaOH (10mg) blah blah unsuccessful blah
represents an unsuccessful synthesis of A. Even without the unsuccessful it is still possible to deduce a non-event.
One place this is going is a formalisation of CML to support synthetic procedures.
Thanks for the comments
ChemDraw and the ISIS Draw do at least allow you to export to the published-if-not-open MDL molfile (CT) format and in MDL Draw, molfile is the default file output type.