In this post I content that the chemical information cycle is broken – to the detriment of the chemical and general commons. I’ll explain what that means.
Robert Terry, Wellcome Trust, is widely know for his advocacy of Open Access. As many of you know from next month if you are funded by Wellcome you MUST make your publications Openly accessible. If your publisher doesn’t allow this, that’s your problem. Robert created a diagrammatic view of why Closed Access deprives the scientific commons –
See slide 6
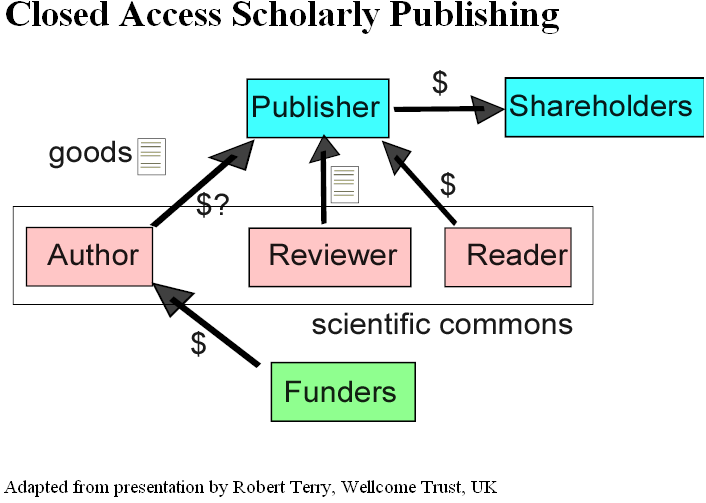
Essentially his argument is that funders support scientists to do research. The results of this work are then given (i.e. copyright assigned) to publishers who get peer-review donated by the scientific community and then restrict the dissemination to readers who are able and prepared to pay. The wealth flow (which include both money, informatics goods, and services) is a net drain FROM the funders TO the shareholders of the publishers.
I have paraphrased this slide (I have missed out the role of libraries as I want to develop the model for software and databases; and I have added readers and reviewers – they are of course all the same people) as:
Robert then showed the benefits of Open Access. I can’t immediately point to his slide but my version hopefully does it justice:
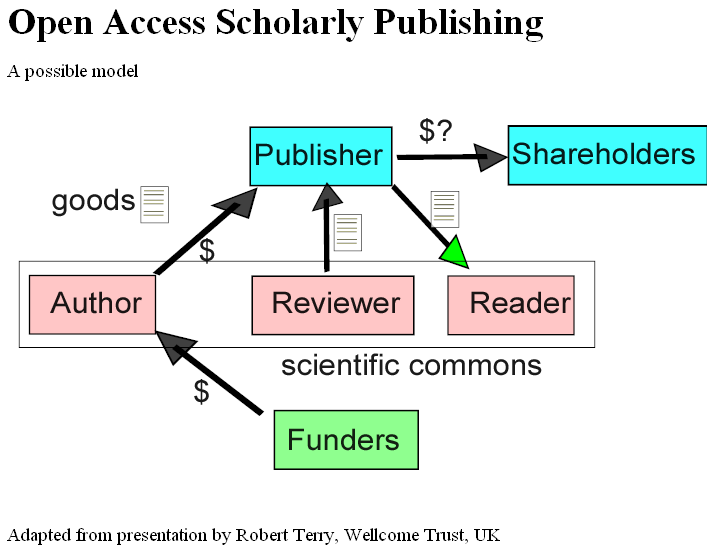
The diagram has changed with the green arrow showing the flow of goods back to the commons. The cycle is complete: funders support science; sceience is published into the commons; the commons can be seen by the funders who can demonstrate the value of their contribution; and the new goods inspire the next generation of science.
Can we apply the same sort of logic to software and data in science? Again we need a cycle or the producers end up subsidizing other parts of the chain. In bioscience this can work. Although there is a considerable problem in any science in supporting data and technology there is direct funding for databases and software. I have drawn 2 cycles – one for software, the other for data. The funders support science with a partial provision for the development of tools to support it. They require that the tools and the data are made available to the community. In this way the cycles are closed and there is a flow of goods back to the commons. Because of the central role of data in modern science, funders may also directly support databases. This is not easy, and it’s expensive but it still seems to happen. In any case the data are Open.
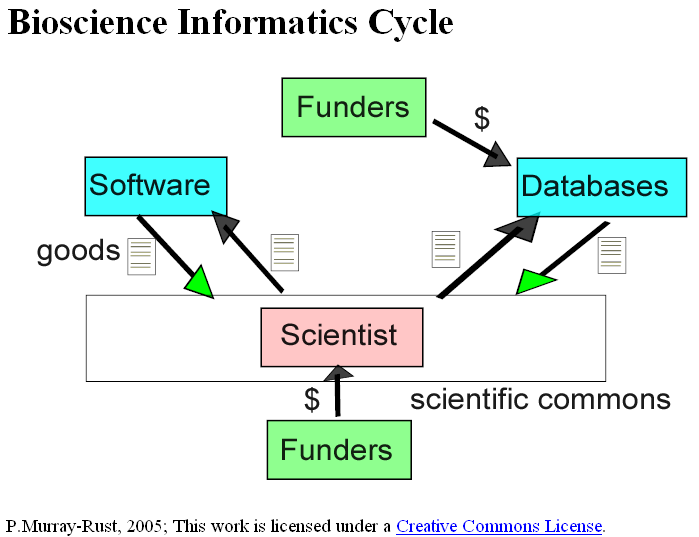
My key contention is that these communal resources give rise to innovation in both the science and the technology. For example there is exciting research into the semantic web in life sciences because there are data on which to experiment and develop methods.
In contrast the flow in chemistry is broken. I have omitted the funders from the diagram but there is very few projects where major software or data has been mandated as Open by the funders. I’d be delighted to have examples. In practice almost all software is commercial and unresponsive to the needs of the science commons. The major market for both software and data is the pharmaceutical industry which pays billions to major information suppliers. This biases the flow so that only crumbs return to the commons. It’s actually worse than zero because if a commercial offering exists there is no motivation to build one in the Commons. So innovation is stifled.
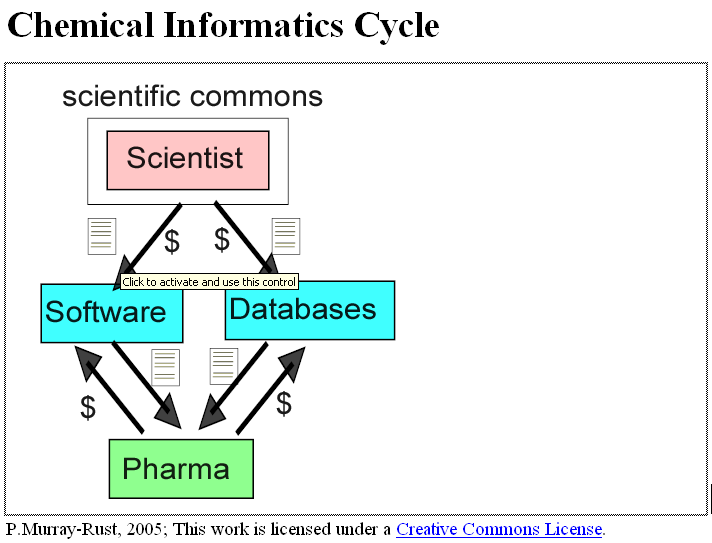
Rich Apodaca in his Blue Obelisk post had a nice quote from the editor of J. Chem. Inf. Comp. Sci. in 1984 urging that chemoinformatics be a reproducible scientific discipline. Unfortunately this is impossible with the software and data models we now have. I’ll post later on the sad state of chemoinformatics practice and why it can’t be properly peer-reviewed.
P.
Very interesting formulation of the challenges and issues. I would be interested to know how you see this fitting in with current eScience and Science Commons efforts. I wrote a bit today about this, as it happens – the concepts of open science and information commons.
(1) Thanks very much Richard – the great thing about a blog is that you get
feedback in a way that never happens in most paper journals.
Did you mean your last phrase to be a hyperlink? If so perhaps you could provide
it in another comment. (I am still finding my way round this blog).
I think Open Data is much less well understood than Open Access. In some communities
this isn’t an issue – data get published automatically and authors accept this
and evern welcome it. In some others possession of data, by authirs, is seen as power
and is not released willingly. In others – such as chemistry – data is aggregated
by commercial interests and resold to the community that created it.
I think it’s very valuable to revisit this and I’m motivated to revisit the SPARC list.
But I need to get the ACS meeting done first!
Another couple tries at links
1 plain text
http://scilib.typepad.com/science_library_pad/2006/09/the_concepts_of.html
2 a href
the concepts of open science and information commons
Pingback: Unilever Centre for Molecular Informatics, Cambridge - petermr’s blog » Blog Archive » Presentation to Open Scholarship 2006
Pingback: Unilever Centre for Molecular Informatics, Cambridge - petermr’s blog » Blog Archive » Commons in the pharma industry?