Readers of this blog will have seen many posts where I (and by proxy Mike Taylor and others) highlight the unacceptable practices of Elsevier when publishing Gold Open Access. The facts appear to be undisputed – Elsevier is mis-labelling and thereby misselling articles which author have paid for.
My only avenue of contact has been Elsevier’s “Director of Universal Access”. I have alerted the Director to my concerns and the response has been minimal – assurances that Elsevier have been putting things right and flippant comments such as “Good things take time”. I have yet to be convinced that the Director has any power beyond trying to play down issues and there is no indication that Elsevier take the problem seriously at a high level.
I have therefore written to my MP (and thence to David Willetts – this is the way it is done). Julian and I know each other well – he researches on DNA quadriplexes. I sincerely hope he and David can redress the balance from the corporate to the public good.
Dear Julian,
APPARENT MISSELLING OF GOLD OPEN-ACCESS BY ELSEVIER
I am writing to alert you to the unacceptable quality of Elsevier’s paid Open Access products. I ask you to take this forward and to bring this to the attention of David Willetts and UK research funders. I know you and he are very familiar with Open Access and omit the background.
In essence Elsevier have been selling Gold Open Access and Hybrid Gold Open Access and failing to deliver what the authors/funders paid for. This has happened over a period of two years, and although Elsevier have been alerted many times by individuals they continue to do it.
The evidence is anecdotal but I believe the practice is widespread. Mike Taylor (honorary researcher at Bristol) first announced the
problem two years ago (http://svpow.com). Seven months ago the practice was endemic in Elsevier journals and I have documented many independent problems on my blog (http://www.ch.cam.ac.uk/pmr). I summarise here, but can collate the examples if required.
The problem takes several forms:
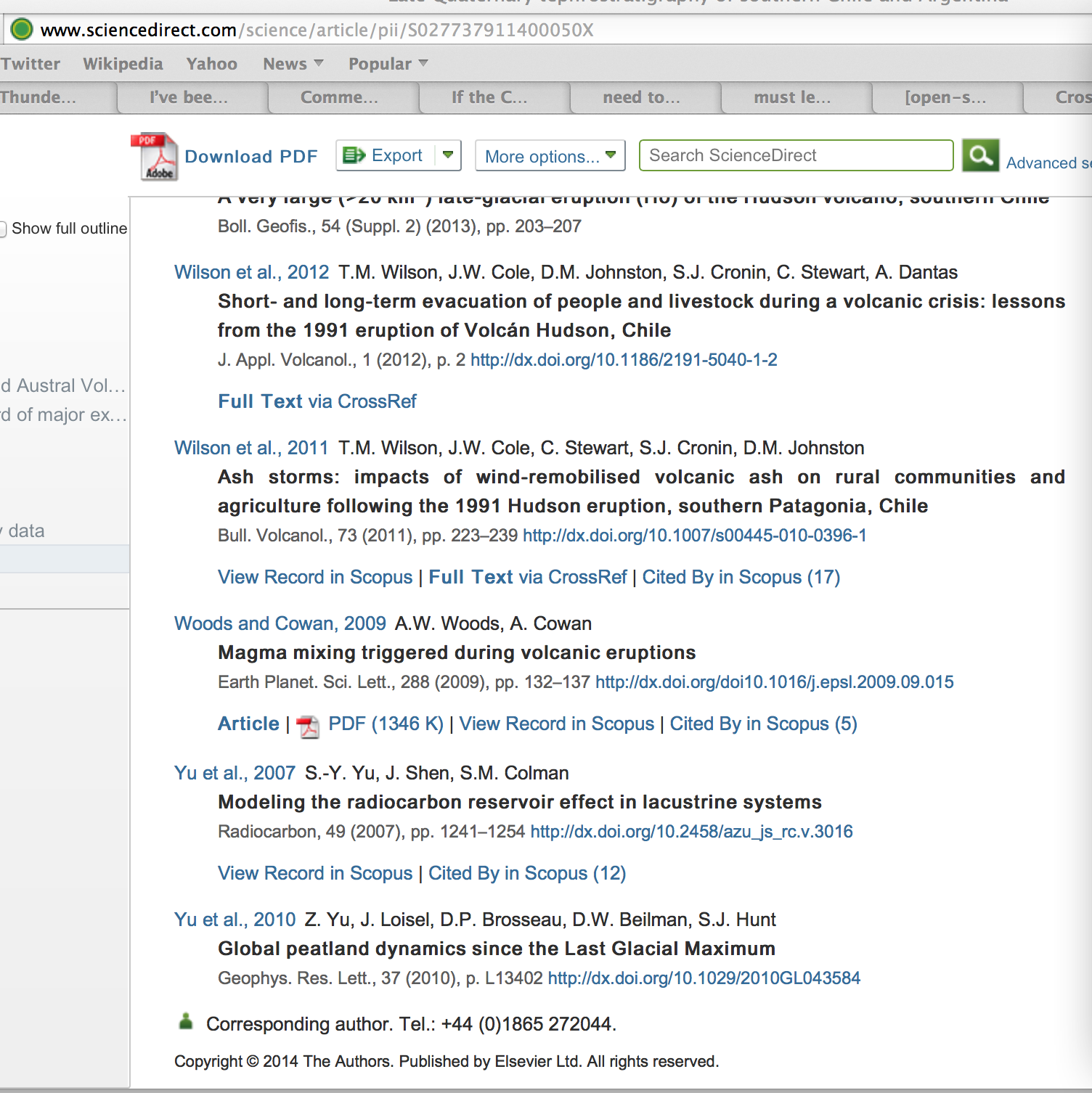
- Elsevier take money for an OpenAccess article and put it behind a paywall, thereby requiring the citizens of the world to pay to read Open Access.
- Elsevier claim IP rights over the article. Most funders require CC-BY or similar licences with no handover of rights. I find ubiquitous statements such as “(C) Elsevier” or “All rights reserved” which are presumably in breach of the contract that Elsevier and the authors signed. I believe that Elsevier may be breaking both contract law and copyright law.
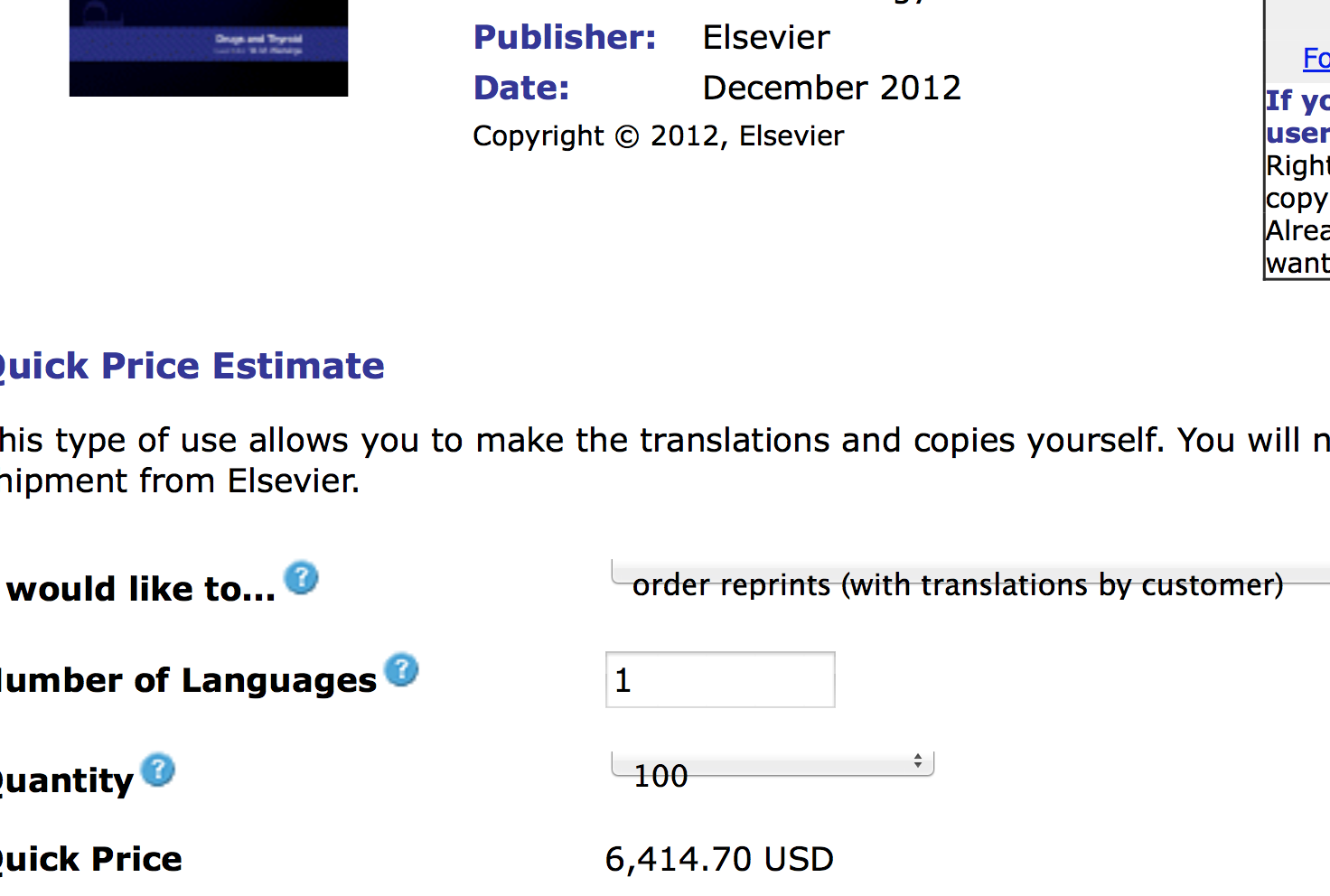
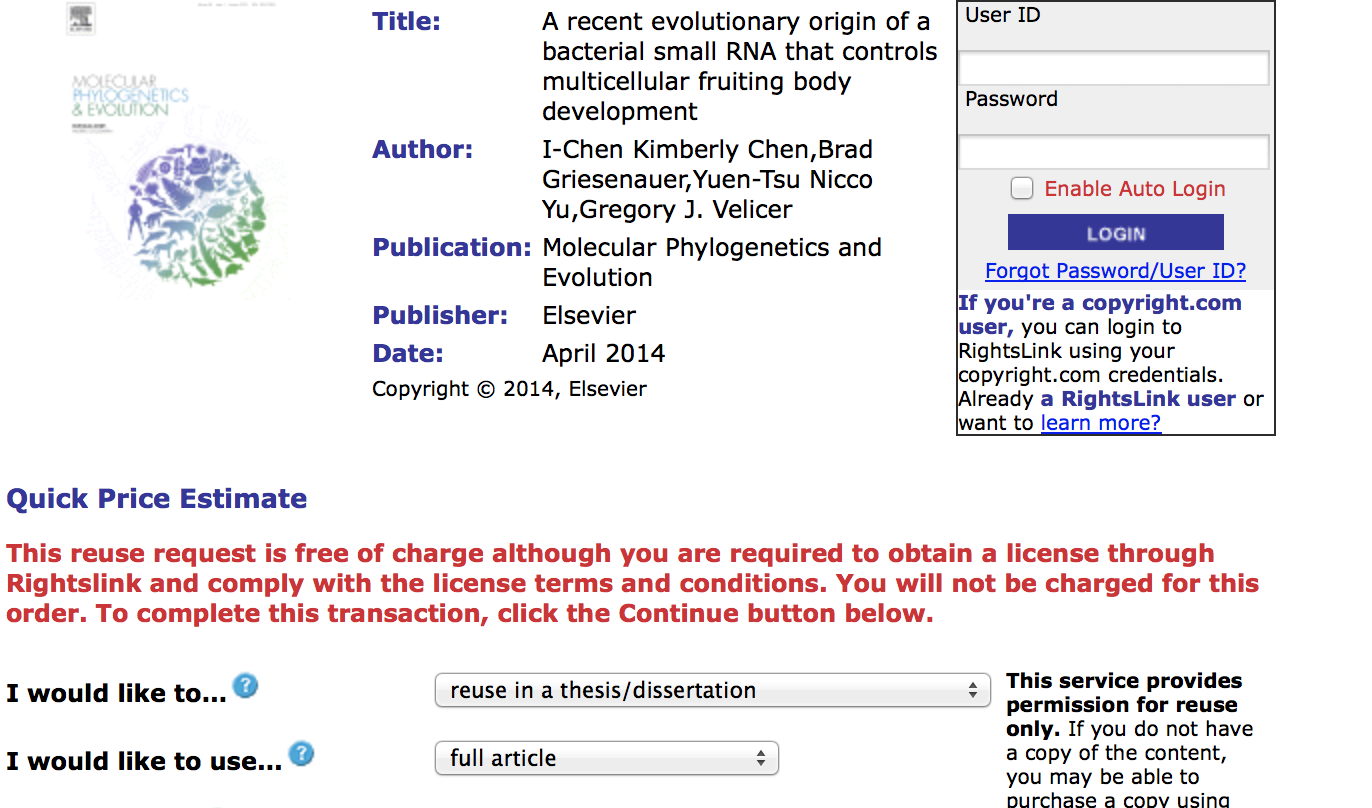
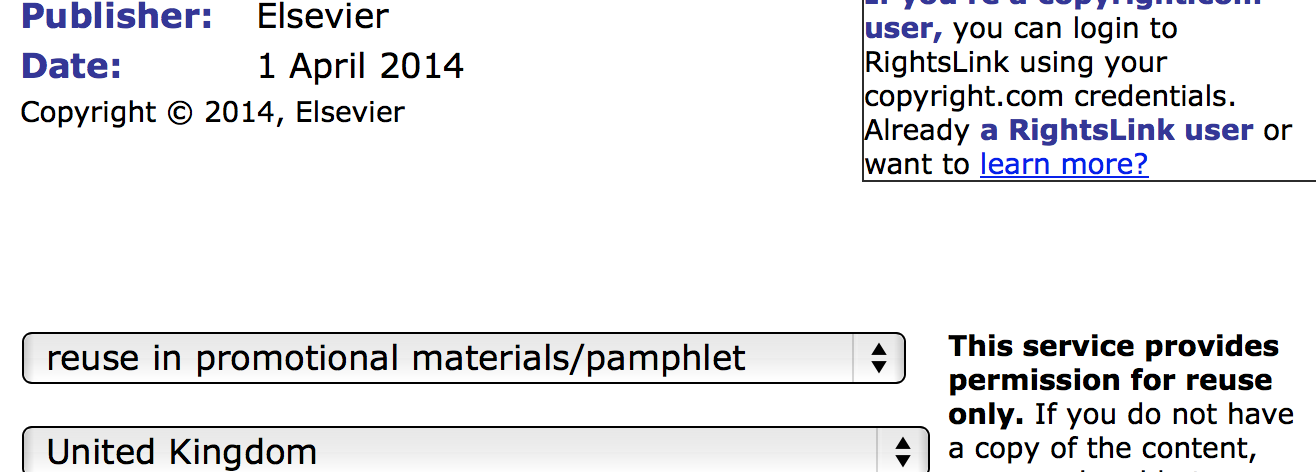
- Elsevier state that permissions can (often should) be obtained through the Copyright Clearance Centre (Righstlink). In some cases the website is so constructed that it effectively convinces readers that Elsevier owns the downstream rights of the article and that all re-use permissions must go through Rightslink. I would compare this closely to other recent misselling of products. It is easy for a reader to pay many thousands of pounds for “permissions” which they do not need to buy.
As our information is anecdotal and only Elsevier knows the details I cannot judge the scale of the problem. I noted 7 months ago that when Elsevier announced new Gold OA journals all of them had severe failings. When I asked Elsevier for a list of Hybrid Open Access papers in their journals they were unable to give it to me.
I am not imputing motive in this letter (it could be incompetence, indifference, or deliberate mislabelling). However I strongly believe that Elsevier has obtained and is continuing to obtain revenue that they are not entitled to and which they should return to both authors and readers/re-users. I leave it to you as to whether further punitive action is possible and appropriate.
There is a wider cost than the monetary one. By providing mislabeled and mis-sold products Elsevier’s practice has devalued Gold Open Access. As the largest publisher their practice may suggest to other publishers that they need not take care and attention. The opportunity cost is large – readers will not have read articles to which they are entitled and, deterred by the Rightslink cost, will have failed to re-use materials. Authors may have been held to account by funders for “failing” to publish Open Access when it was Elsevier’s fault. It causes delay and waste in scholar’s research.
Elsevier (through their “Director of Universal Access”) have effectively acknowledged fault in messages left on my and Mike Taylor’s
blogs. They state that they are rectifying problems and that this will take “some months”. They ask us to be patient with the flippant comment “Good things take time”. I regard this as completely unacceptable – a corporation should give a formal believable high-level response to a major problem.
I believe the primary cause is because the scholarly publishing industry is unregulated at any level. Your government is putting many
millions into Open Access with no controls on the quality of the product.
As you are a professional bioscientist and author I will leave it to you as to how you take this forward. My suggestions would be that David Willetts should:
- write to the board of Elsevier and demand a full public account of what has happened
- require them to provide a full audit of every paid Open Access paper.
- require them to identify individuals and organisations who have been mis-sold by Elsevier and to appropriately refund their payments.
- consider how to build a regulatory process for paid Open Access.
I hope you will forward this to UK government funding bodies such as RCUK. I shall separately copy Robert Kiley (Wellcome Trust).
Best wishes
Peter
[PS I shall shortly be sending you a separate mail on Content Mining – please keep the issues separate.]