Early last week the UK House of Lords passed the final stages of a Statutory Instrument with exceptions to copyright. For me that most important was that those with legitimate access to electronic content can now use mining technology to extract data without permission from the owners. The actual legislation took less than a minute, but the process has been desperately fought by the traditional publishers who have attempted to require subscribers to get permission from them.
IN THE UK THEY HAVE FAILED IN THIS BATTLE
That means that I, who have legitimate access to the content of Cambridge University Library and their electronic subscriptions, can now use machines to read any or all of this without breaking copyright law. Moreover the publishers cannot override this with additional restrictive clauses in their contracts.
The new law restricts the use to “non-commercial” but this will no affect what I intend to do. To avoid any confusion I am publicly setting out my intentions; because I shall be using subscription content I am advising Cambridge University Library. I am not asking anyone’s permission because I don’t have to.
Yesterday I wrote to Yvonne Nobis, Head of Science Information in CUL.
I am informing you of my content mining research using subscription content in CUL. Please forward this to anyone else in CUL who may need to know. Also if there is any time this week I would be very happy to meet (or failing that Skype) – even for a short time.
As you know the UK government has passed a Statutory Instrument based on the Hargreaves review of copyright exempting certain activities from copyright, especially “data analytics” which covers content mining for facts. This comes into force on 2014-06-01.
I intend to use this to start non-commercial research and to publish the results in an OpenNotebookScience (
https://en.wikipedia.org/wiki/Open_notebook_science) philosophy (i.e. publicly and immediately on the web as the work is done, not retrospectively). This involves both personal research in several scientific fields and also collaborations in 3-4 funded projects:
- PLUTo (BBSRC, Univ Bath) – Ross Mounce
- Metabolism mining (Andy Howlett, Unilever funded PhD and also with Christoph Steinbeck EBI, Hinxton, UK)
- Chemical mining (TSB grant) Mark Williamson.
We are also collaborators in the final application stage for an NSF grant collaboration for chemical biodiversity in Lamiacae (mints, etc.). This is very exciting and mining may throw light on chemicals as signals of climate change.
I intend to mine responsibly and within UK law. I expect to mine about 1000-2000 papers per day – many will be subscription-based through CUL. I have access to these as I have an Emeritus position but as I am not paid by CU then this cannot be construed as commercial activity. Typically my software will ingest a paper, mine it for facts, and discard the paper – the process takes a few seconds.
As a responsible scientist I am required by scientific ethics and reproducibility/verifiability to make my results Open and this includes the following Facts:
- bibliographic metadata of the article (but not the abstract)
- citations (bibliographic references) within the article
- factual lists of tables , figures and supplemental data.
- sources of funding (to evaluate the motivations of researchers
- licences
- scientific facts (below)
I shall not reproduce the whole content but shall reproduce necessary textual metadata without which the facts cannot be verified. These include:
- figure and table captions (i.e. metadata)
- experimental methodology (e.g. procedures carried out)
I shall not reproduce tables and figures. However my software is capable, for many papers, of interpreting tables and diagrams and extracting Factual information (e.g. in CSV files). [My output will be more flexible and re-sable than traditional pixel-based graphs.]
I expect to extract and interpret the following types of Facts:
- biological species
- place names and geo-locations (e.g. lat/long)
- protein and nucleic acid sequences
- chemical names and structure diagrams
- phylogenetic (e.g. evolutionary) trees
- scatterplots, bar graphs, pie charts, etc.
and several others as the technology progresses.
The load on publishers’ servers is negligible (this has been analysed by Cameron Neylon of PLoS).
I stress the the output is qualitatively no different from centuries of extraction from the literature – it is the automation of the procedure. Facts are not copyrightable and nor will my output be.
I shall publish the results on my personal open web pages, repositories such as Github and offer them to EuropePMC for incorporation if they wish . Everything I publish will be licensed under CC 0 (effectively public domain). I would also like to explore exposing the results through the CUL. I have already pioneered dspace@cam for large volumes of facts, but found that the search and indexing wasn’t appropriate at the time. If you have suggestions as to how the UL might help it could be a valuable example for other scholars.
I am not expecting any push-back or take-downs from publishers as this activity is now wholly legal. The Statutory Instrument overrides any restrictive clauses from suppliers, including robots.txt. I therefore do not need or intend to ask anyone for permission. This will be a very public process – I have nothing to hide. However I wish to behave responsibly, the most likely problem being load on publishers’ servers. Richard S-U (Plant Sciences, Cambridge, copied) and I are developing crawling and scraping protocols which are publisher-friendly (e.g. delays and retries) – we have also discussed this with PLoS (Cameron).
In the unlikely event of any problems from publishers I expect that CUL, as licensee/renter of content, would be the first point of contact. I will be happy to be available if CUL needs me. If publishers contact me directly I shall immediately refer them to CUL as CUL is the licensee.
I have written this in the first person (“I”) since the legislation emphasises personal use and because organised consortia may be seen as “commercial”. The law is for the UK. Fortunately the mining is wholly compatible:
- I am a UK citizen from Birth
- I live in the UK
- I have a pension from the UK government (non-commercial activity)
- My affiliation is with a UK university
- The projects I outline are funded by UK organisations.
- My collaborators are all UK.
I play a public domain version of “Rule Britannia!” incessantly and have a Union Jack teddy bear. I shall however, vote for Britain to continue as a member of the EU and also urge my representatives (MEPs) to continue to press for similar legislation in Europe. I personally thank Julian Huppert and David Willetts for their energy and consistency in pushing for this reform, which highlights the potential value of parliaments in a democracy.
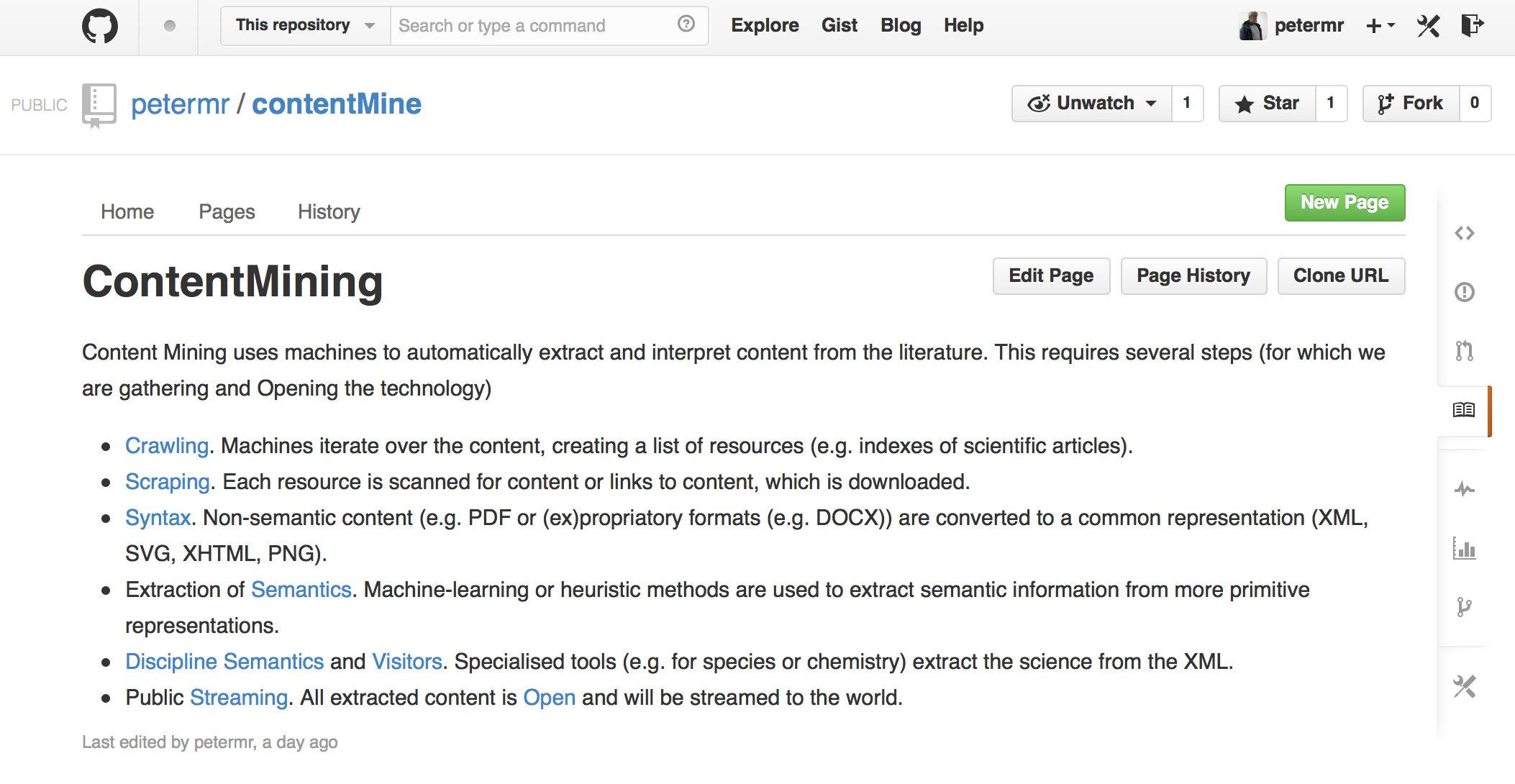
I also thank my collaborators in the ContentMine (http://contentmine.org) where I shall be demonstrating and discussing our technology, which is the best that I know of outside companies like G**gle. As an academic I welcome offers of collaboration, but stress that we cannot run a mining service for you (though we can show you how to run our toolkit). If the projects are interesting enough to excite me as a scientist I may be very happy to work with you as a co-investigator, though I cannot be paid for mining services.
Sadly, very few publishers come out of this with anything positive. Naturally the Open Access publishers (PLOS, BMC, eLife, MDPI, PeerJ, Ubiquity and others) have no problems as they can be and want to be mined. We have already had long discussions with them. The Royal Society (sic, not the RSC) has positively said that their content can be mined. All the rest, and especially the larger ones, have actively lobbied and FUDded to stop content mining. When you know that organisations are spending millions of dollars to stop you doing science it can be depressing, but we’ve had the faith to continue. I’m particularly proud of Jenny Molloy, Ross Mounce and others for their public energy in maintaining
“The Right To Read is the Right To Mine”
Now that the political battle (which has taken up 5 years of my life) is largely over, I’m devoting my energies to getting the ContentMine as a universal resource and building new next generation of intelligent scientific software.
And you can be an equal part of it, if you wish.