I am on the board of a wonderful community voluntary organization – the Crystallography Open Database (COD) http://www.crystallography.net/ . For 10 years it has been collecting crystal structures from the literature and making them Open – more than 300,000. It’s the only Open database for small structures (the others CSD and ICSD are closed and based on subscriptions even though the data is taken from public papers. This morning we heard of a great paper using the COD for data-driven research. Here’s the landing page http://www.mdpi.com/2073-4352/5/4/617 :

The paper is trawling through hundreds of thousands of structures to find those with a high proportion of hydrogen atoms – a clever idea for finding possible Hydrogen Stores for Energy. The closed databases couldn’t be used without subscriptions.
I think this is a clever idea and tweeted it. I’m a crystallographer and structural chemist so it’s not surprising that a few other people retweeted it.
However I noticed that the article had a daily count of accesses and that there was a small glitch of 3 accesses today. I tweeted this and – surprise – the accesses went up. after 12 hours there have been over 100 accesses
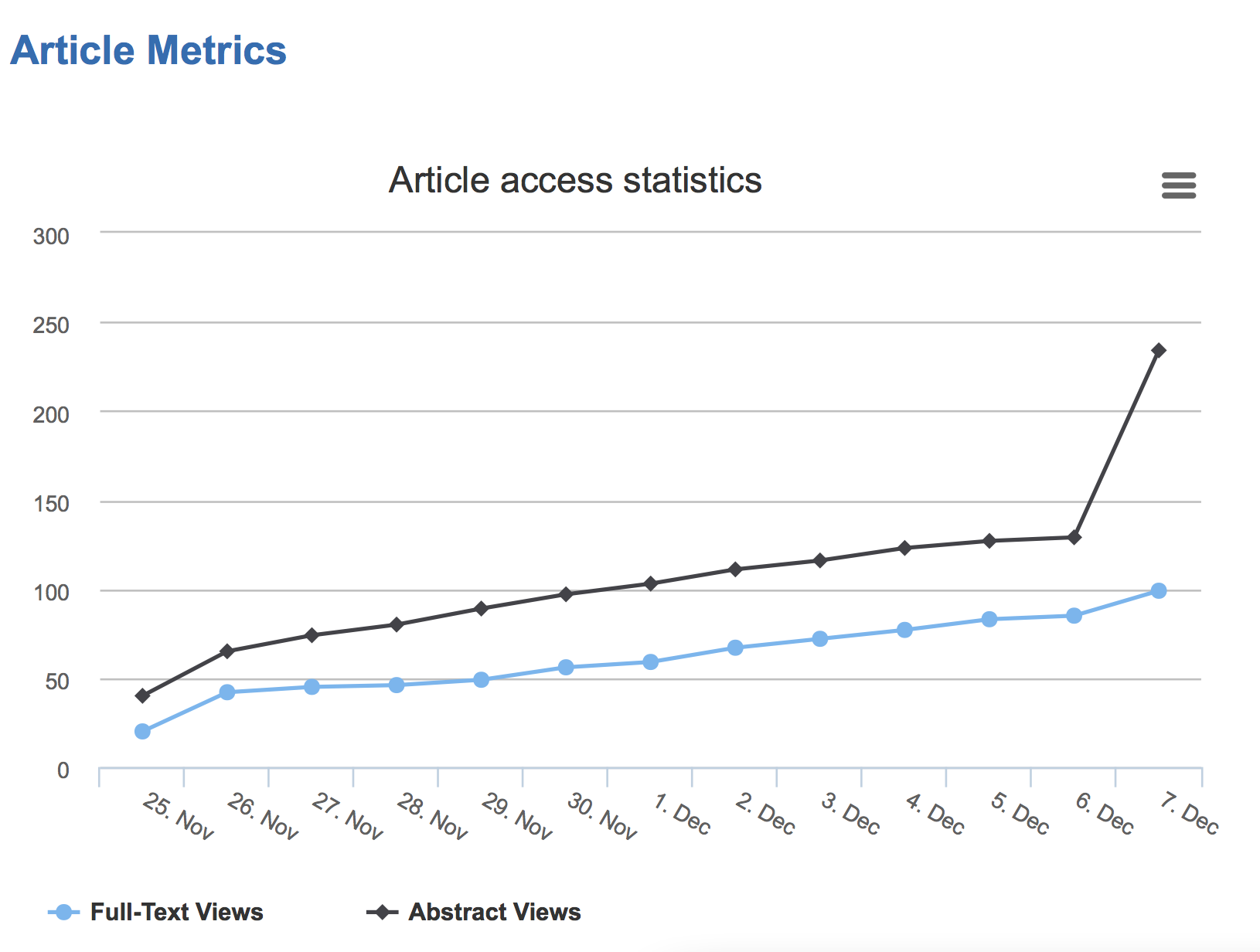
You’ll see there have been over 100 accesses today because I and 3-4 others have tweeted it. This is nothing to do with the contents of the paper because not many have actually read it today. People have clicked to view the graph, and every time they visit the graph goes up. It’s nothing to do with the quality of the science (which I think is good) or the fact that the paper is Open Access – it’s just a Heisentwitter.
So what does 100 accesses today mean? Nothing.
What does my opinion of the paper count? Something, I hope (I would have recommended publication).
The point is that to decide whether science is good or useful
you have to read the paper
-
Recent Posts
-
Recent Comments
- pm286 on ContentMine at IFLA2017: The future of Libraries and Scholarly Communications
- Hiperterminal on ContentMine at IFLA2017: The future of Libraries and Scholarly Communications
- Next steps for Text & Data Mining | Unlocking Research on Text and Data Mining: Overview
- Publishers prioritize “self-plagiarism” detection over allowing new discoveries | Alex Holcombe's blog on Text and Data Mining: Overview
- Kytriya on Let’s get rid of CC-NC and CC-ND NOW! It really matters
-
Archives
- June 2018
- April 2018
- September 2017
- August 2017
- July 2017
- November 2016
- July 2016
- May 2016
- April 2016
- December 2015
- November 2015
- September 2015
- May 2015
- April 2015
- January 2015
- December 2014
- November 2014
- September 2014
- August 2014
- July 2014
- June 2014
- May 2014
- April 2014
- March 2014
- February 2014
- January 2014
- December 2013
- November 2013
- October 2013
- September 2013
- August 2013
- July 2013
- May 2013
- April 2013
- March 2013
- February 2013
- January 2013
- December 2012
- November 2012
- October 2012
- September 2012
- August 2012
- July 2012
- June 2012
- May 2012
- April 2012
- March 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- September 2011
- August 2011
- July 2011
- May 2011
- April 2011
- March 2011
- February 2011
- January 2011
- December 2010
- November 2010
- October 2010
- September 2010
- August 2010
- July 2010
- June 2010
- May 2010
- April 2010
- August 2009
- July 2009
- June 2009
- May 2009
- April 2009
- March 2009
- August 2008
- July 2008
- June 2008
- May 2008
- April 2008
- March 2008
- February 2008
- January 2008
- December 2007
- November 2007
- October 2007
- September 2007
- August 2007
- July 2007
- June 2007
- May 2007
- April 2007
- December 2006
- November 2006
- October 2006
- September 2006
-
Categories
- "virtual communities"
- ahm2007
- berlin5
- blueobelisk
- chemistry
- crystaleye
- cyberscience
- data
- etd2007
- fun
- general
- idcc3
- jisc-theorem
- mkm2007
- nmr
- open issues
- open notebook science
- oscar
- programming for scientists
- publishing
- puzzles
- repositories
- scifoo
- semanticWeb
- theses
- Uncategorized
- www2007
- XML
- xtech2007
-
Meta
Peter, to me #altmetrics are still in the first place numbers that reflect the amount of attention (as proxy to impact) has, but importantly, the tools that calculate them provide the provenance of the count and it is this network that has value to me. It is not the number that tells me much about a paper, about just as much as the citation count, but the links to other papers (citations) and other communication channels points me to related discussions. This way, it provides a richer scientific communication and therefore dissemination channel. In a lot of cases the things that boost the #altmetrics are not really about the science, as you note too; this is not really different from citation counts either, where many citations are more of the likes of “hey, look, they did something that smells like X too” (which is a reason why we must adopt a solution like the Citation Typing Ontology, but that’s only a related discussion; http://www.jbiomedsem.com/content/1/S1/S6). But I compare tweeting about a paper like putting a paper on someone desks, or blogging like having a poster at a conference to make people aware of my research.
It indeed says nothing about quality, but also not less that more traditional ways to make people know about your own or research by others. Or?