I haven’t blogged for some time as I have been writing Liberation Software (software to make knowledge and people free). Now we (Ross Mounce, Matt Wills and I) have got our first significant scientific result – a supertree:

I am going to leave Ross the opportunity to blog this in detail – he was hacking this late last night – so a brief overview:
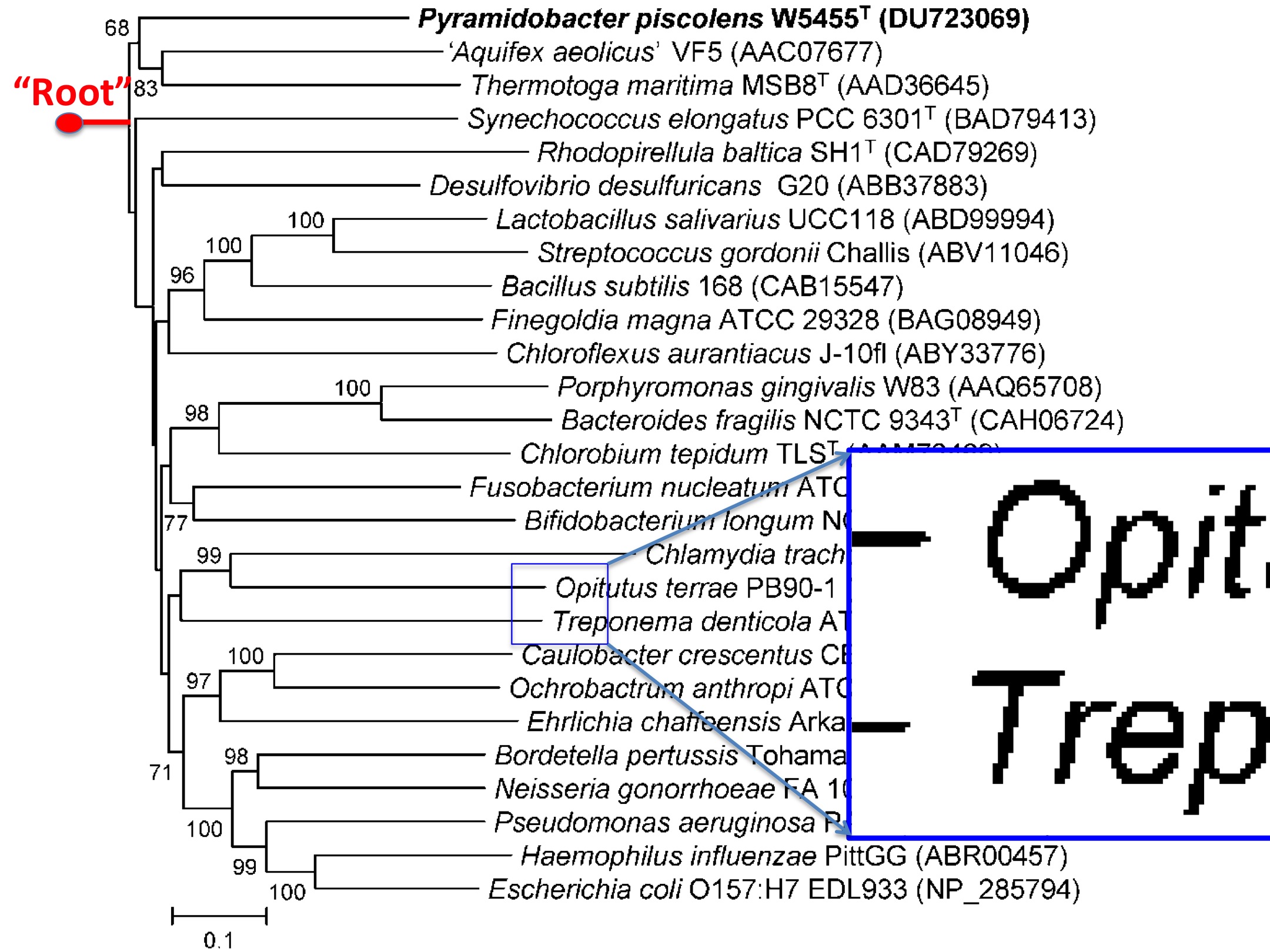
For every new microorganism it’s obligatory to compare it with other organisms in an evolutionary (phylogenetic) tree. Here’s a typical one (don’t be frightened – everyone can understand this if they are familiar with evolutionary ideas.)
https://github.com/ContentMine/ijsem/blob/master/batch1/ijs.0.000364-0-003.pbm/image/ijs.0.000364-0-003.pbm.png . The image was pusblished in http://ijs.sgmjournals.org/content/journal/ijsem/10.1099/ijs.0.000364-0?crawler=true&mimetype=application/pdf (Citation: International Journal of Systematic and Evolutionary Microbiology b(2009),59,972–980 DOI 10.1099/ijs.0.000364-0)
 are
are
[I have added “root” and magnified some of it].
31 microorganisms (mainly bacteria) listed in the middle. Each has a binomial (scientific) name (Pyramidobacter piscolens) , a strain identifier (W5455T), and an identifier in an RNA database (e.g. EU379932). The lines represent a “tree” with its root (not shown) at the left hand side and presumed divergence of the species. It’s certainly a useful classification; you can debate whether it’s a useful historical model of the actual evolution over many million years. Thus it says that Pyramidobacter piscolens is closely related to Jonquetella anthropi and much more distantly related to Escherichia coli, a bacterium in everybody’s gut.
Each paper provides one such tree – which could take significant amounts of computation (often hours depending on the strictness). What we have done – and this is a strength of Matt’s group, is to bring thousands of such trees together. They weren’t calculated with this in mind, and we are adding value by extracting them from the literature and making comparisons and aggregations.
Ross downloaded about 4,300 papers and the trees in them. I wrote the software to extract trees from the images. This is not trivial – the images are made of pixels – there are no explicit lines or characters or words and this research is full of heuristics. So we can’t always distinguish “O” (Oh) from “0” (one). So there will be an unavoidable percentage of garbles.
BUT we have ways of detecting and correcting these (“cleaning”) and the most valuable are:
{kind=link}
- comparing the scientific name with the RNA ID
- looking up the name in the NCBI’s Taxdump (a list of all biomedical species)
Ross has developed several methods of cleaning and we are reasonably confident that the error rate in species is no worse that 1 in 1000. (Note, by the way, that the in a sibling image the authors have made a misprint: “Optiutus” should be “Opitutus”. so the primary literature also contains errors).
Everything we do is Open Notebook. We post stuff as soon as it is ready. We store it on Github (see above link, which has all 4300 trees), discuss it on ContentMine’s Discourse (discuss.contentmine.org/t/error-analysis-in-ami-phylo/116/ – you can see that every detail is made open), software in (https://github.com/petermr/ami-plugin and many other repos, fully Open and often updated several times a day), and contentmine.org where Ross will be blogging it.
I hope to write much more frequently now.
Pingback: Announce: Microbial Supertree through ContentMining – ContentMine