Scholarly literature has been virtually untouched by the digital revolution in this century. The primary communication is by digital copies of paper (PDFs) and there is little sign that it has brought any change in social structures either in Universities/Research_Establishments or in the publishing industry. The bulk of this industry comprises two sectors, commercial publishing and learned societies. The innovations have been largely restricted to Open Access publishing (pioneered by BMC and then by PLoS) and the megajournal (PLoSOne).
I shall generalise, and exempt a few players from criticism: The Open Access publishers above with smaller ones such as eLife, PeerJ, MDPI, Ubiquity, etc. And a few learned societies (the International Union of Crystallography and the European Geosciences Union, and please let me have more). But in general the traditional publishers (all those not exempted) are a serious part of the problem and cannot now be part of the solution.
That’s a strong statement. But over the last ten years it has been clear that publishing should change, and it hasn’t. The mainstream publishers have put energy into stopping information being disseminated and creating restrictions on how it can be used. Elsevier (documented on this list) has prevented me extracting semantic information from “their” content.
The market is broken because the primary impetus to publish is increasingly driven by academic recognition rather than a desire to communicate. And this makes it impossible for publishers to act as partners in the process of creating semantics. I hear that one large publisher has now built a walled garden for content mining – you have to pay to access it and undoubtedly there are stringent conditions on its re-use. This isn’t semantic progress, it’s digital neo-colonialism.
I believe that semantics arises out of community practice of the discipline. On Saturday the OKFN is having an economics hackathon (Metametrik) in London where we are taking five papers and aiming to build a semantic model. It might be in RDF, it might be in XML; the overriding principle is that it must be Open, developed in a community process.
And in most disciplines this is actively resisted by the publishing community. When Wikipedia started to use Chemical Abstracts (ACS) identifiers the ACS threated Wikipedia with legal action. They backed down under community pressure. But this is no way for semantic development. It can only lead to centralised control of information. Sometimes top-down semantic development is valuable (probably essential in heavily regulated fields) but it is slow , often arbitrary and often badly engineered.
We need the freedom to use the current literature and current data as our guide to creating semantics. What authors write is, in part, what they want to communicate (although the restrictions of “10 pages” is often absurd and destroys clarity and innovation). The human language contains implicit semantics, which are often much more complex that. So Metametrik will formalize the semantics of (a subset of) economic models, many of which are based on OLS (ordinary least squares). Here’s part of a typical table reporting results. It’s data so I am not asking permission to reproduce it. [It’s an appalling reflection on the publication process that I should even have to, though many people are more frightened of copyright that of doing incomplete science.]
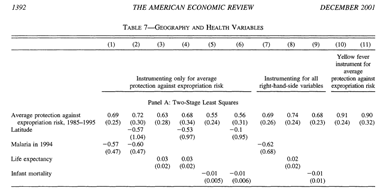
And the legend:

How do we represent this table semantically? We have to identify its structure, and the individual components. The components are, for the most part well annotated in a large metadata table. (And BTW metadata is essential for reporting facts so I hope no one argues that it’s copyrightable. If they do, then scientific data in C21 is effectively paralysed.)

That’s good metadata for 2001 when the paper was published. Today, however , we immediately feel the frustration of not linking *instantly* to Gallup and Sachs, or La Porta. And we seethe with rage if we find that they are paywalled and this is scholarly vandalism – preventing the proper interpretation of scholarship.
We then need a framework for representing the data items. Real (FP) numbers, with errors and units. There doesn’t seem to be a clear ontology/markup for this, so we may have to reuse from elsewhere. We have done this in Chemical Markup Language (its STMML subset) which is fully capable of holding everything in the table. But there may be other solutions –please tell us.
But the key point is that the “Table” is not a table. It’s a list of regression results where the list runs across the page. Effectively its regression1, … regression 11. So a List is probably more suitable than a table. I shall have a hack at making this fully semantic and recomputable.
And at the same time seeing if AMI2 can actually read the table from the PDF.
I think this is a major way of kickstarting semantic scholarship – reading the existing literature and building re-usables from it. Let’s call it “Reusable scholarship”.