In my talk at #ETD2009 I will make reference to SPECTRa-T, a JISC funded project that looked at the extraction of semantic information from chemistry theses. It was a first attempt and we were grateful to Steve Ley and his group for giving us access to about 12 theses. These were in Word, without which we could not have done very much useful.
I’m showing the poster that the group created to present their work. I know it’s a bit small, but it’s mainly to acknowledge them and to show the complex workflows that we built. It’s not necessary to read the small print, just to acknowledge that we could run theses through the system.
Here are some bits magnified (I am still learning the best way to use this blog):
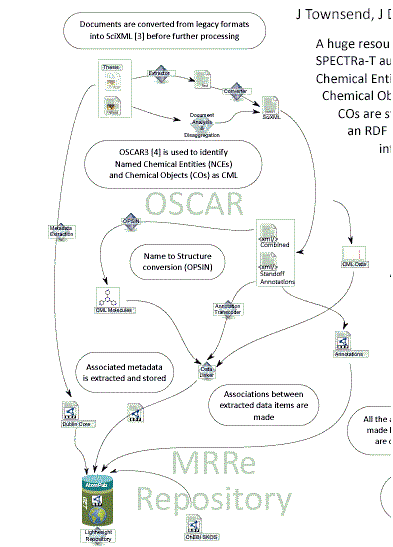 This shows how OSCAR (our journal-eating robot) is able to extract the chemistry from the text of the thesis and put it in the repository
This shows how OSCAR (our journal-eating robot) is able to extract the chemistry from the text of the thesis and put it in the repository
The next picture shows how we can extract semantic chemistry if the author has embedded chemical-specific objects (OLE, images) in the thesis. This is hard work for us but it can work:
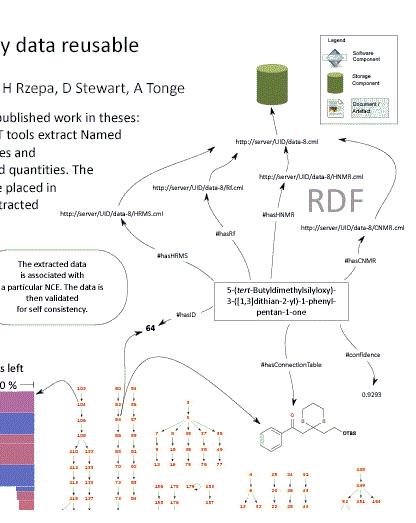
Here we show how both graphical chemistry (the molecular picture) and the chemical name can be turned into real semantic chemistry. The graph is a complete network of all the chemical reactions in the thesis – automatically created by machine. Even the author has never seen this graph.
But it’s hard and lossy.
Word2003 allowed us to capture much of the chemistry.
PDF was much worse.
Much worse
Wouldn’t it be better if the chemist included all that in the thesis when it was submitted. The information all exists – all they have to do is zip it up and deposit it.
We also sent you some theses 🙂
@mat I will amend this. Great to have met up with Peter Turner here