In Why PubMed is so important in the NIH mandate – which got sent off prematurely – I started to show why the NIH/PubMed relationship was so important. To pick up…
The difference between PubMed and almost all other repositories is that it has developed over many years as a top-class domain specific information engine. Here’s a typical top page (click to enlarge):
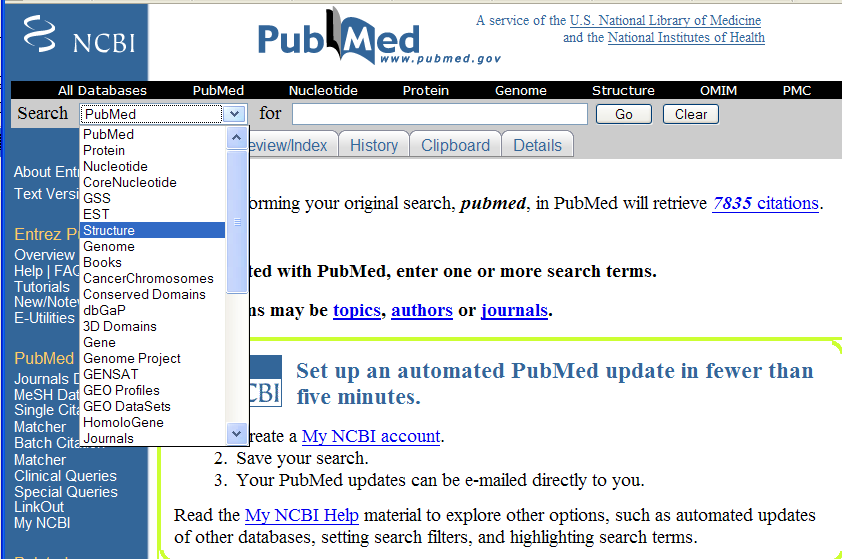
Notice the range of topics offered. Many of these are searching collections of named scientific entities. Such as genes, proteins, molecules, diseases, etc. One really clever idea – at least two decades old – was that you search in one domain, come back with the hits, search in another domain, and so on. An early idea of mashups, for example.
You can’t do this with Google. If you search for CAT you get all sorts of things. But in Pubmed you can differentiate between the animal, the 3-base codon, the tripeptide, the enzyme, the gene, the scanning techique and so on. Vastly improved accuracy. You can search for CAT scans on Cats. And there are the non-textual searches. You can do homology seraches for sequences. Similar molecules using connection tables. etc. etc.
Then there is the enormous economy of scale. Let’s say I search for p450 (a liver enzyme). I get 23000+ hits. I can’t possibly read them all. But OSCAR can. OSCAR can read the abstracts anyway, but now it will be able to read many more fulltexts as well. It can pass them to chemistry engines, which pass them onto … and then onto …
You can’t do that with Institutional repositories or with self-archiving. They don’t have the domain search engines, they don’t have the comprehensives. They don’t emit the science in standard XML.
For science it is likely that we have to have domain repositories. With domain-specific search engines, XML, RDF, ORE, the lot. It’s the natural way that scientists will work.
And PubMed – and its whole information infrastructure of MeSH, PubChem, Entrez, etc. is so well constructed and run that it serves as an excellent example of where we should be aiming. It’s part of the future of scientific information and data-driven science.
-
Recent Posts
-
Recent Comments
- pm286 on ContentMine at IFLA2017: The future of Libraries and Scholarly Communications
- Hiperterminal on ContentMine at IFLA2017: The future of Libraries and Scholarly Communications
- Next steps for Text & Data Mining | Unlocking Research on Text and Data Mining: Overview
- Publishers prioritize “self-plagiarism” detection over allowing new discoveries | Alex Holcombe's blog on Text and Data Mining: Overview
- Kytriya on Let’s get rid of CC-NC and CC-ND NOW! It really matters
-
Archives
- June 2018
- April 2018
- September 2017
- August 2017
- July 2017
- November 2016
- July 2016
- May 2016
- April 2016
- December 2015
- November 2015
- September 2015
- May 2015
- April 2015
- January 2015
- December 2014
- November 2014
- September 2014
- August 2014
- July 2014
- June 2014
- May 2014
- April 2014
- March 2014
- February 2014
- January 2014
- December 2013
- November 2013
- October 2013
- September 2013
- August 2013
- July 2013
- May 2013
- April 2013
- March 2013
- February 2013
- January 2013
- December 2012
- November 2012
- October 2012
- September 2012
- August 2012
- July 2012
- June 2012
- May 2012
- April 2012
- March 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- September 2011
- August 2011
- July 2011
- May 2011
- April 2011
- March 2011
- February 2011
- January 2011
- December 2010
- November 2010
- October 2010
- September 2010
- August 2010
- July 2010
- June 2010
- May 2010
- April 2010
- August 2009
- July 2009
- June 2009
- May 2009
- April 2009
- March 2009
- August 2008
- July 2008
- June 2008
- May 2008
- April 2008
- March 2008
- February 2008
- January 2008
- December 2007
- November 2007
- October 2007
- September 2007
- August 2007
- July 2007
- June 2007
- May 2007
- April 2007
- December 2006
- November 2006
- October 2006
- September 2006
-
Categories
- "virtual communities"
- ahm2007
- berlin5
- blueobelisk
- chemistry
- crystaleye
- cyberscience
- data
- etd2007
- fun
- general
- idcc3
- jisc-theorem
- mkm2007
- nmr
- open issues
- open notebook science
- oscar
- programming for scientists
- publishing
- puzzles
- repositories
- scifoo
- semanticWeb
- theses
- Uncategorized
- www2007
- XML
- xtech2007
-
Meta