Edward Tufte said in his recent book that one shouldn’t use Powerpoint to present information, but Word. Although I am not a fan of Word (see later posts) I agree with the message. So this is the first part of my talk to the American Chemical Society. Don’t worry – there’s not a lot of chemistry.
The title is someting like eChemistry (which would be nice if it actually existsed – we are trying to create it). The abstract is irrelevant as it was written 3 months ago and the world has changed so much the abstract is either out of date or so general it doesn’t matter.
First thanks. When you are likely to run into time problems, thank people at the start. Here are some (please let me know If I have missed anyone – it’s easy to do). Almost everyone on this list has hacked something
Cyberheroes (Mainly Blue Obelisk)
Bob Hanson (Jmol)
Christoph Steinbeck(Cologne)
Egon Willighagen(Cologne)
Tobias Helmut(Cologne)
Stefan Kuhn(Cologne)
Ola Sputh(Uppsala)
Eklund, Martin (Uppsala)
Miguel Howard (Jmol)
Joerg Wegner (Tuebingen/ALTOVA)
Rich Apodaca (Stanford)
Rajarshi Guha
Geoffrey Hutchison (Cornell)
Indiana:
Gary Wiggins
David Wild
Geoff Fox
Marlon Pierce
Symbiote: Henry Rzepa
Cambridge:
Ann Copestake and colleagues
Peter Corbett
Nick Day
Jim Downing
Justin Davies
Richard Moore
Joe Townsend
Alan Tonge
Andrew Walkingshaw
Andrew Walker
Toby White
Sponsors:
DTI, Accelrys, IBM
Unilever
Royal Soc Chemistry, Int Union of Crystallography, Nature Publishing Group
JISC
EPSRC
BBSRC
The current workflow in chemical informatics is broken. A typical scenario is:
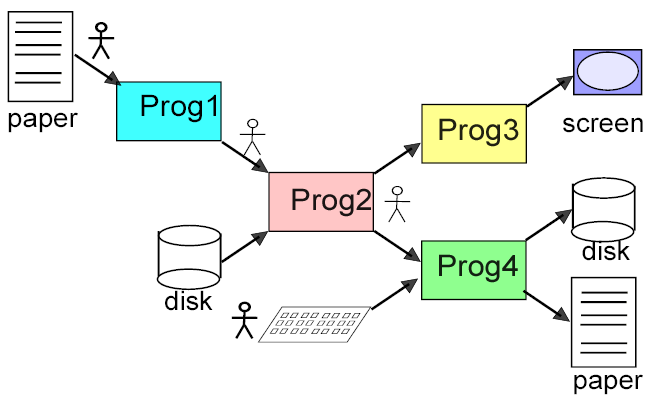
 nonxmlchain.png
nonxmlchain.png
Here we see legacy programs, human activities and legacy data. At each stage a human has to cut and paste stuff, edit it, etc. This causes loss of time, loss of quality and loss of temper. Wouldn’t it be easier if everything was in a consistent interoperable format like this?

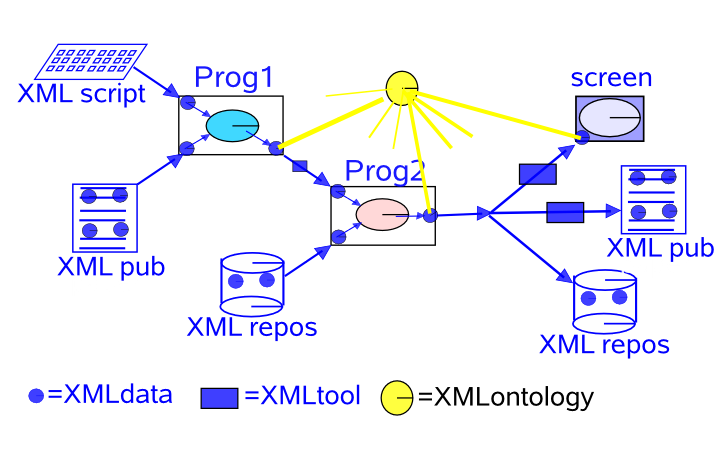
Here all the data is in XML with semantic markup. human input goes seamlessly into programs, databases, etc. The outputs pass between programs display, etc. with no semantic loss and no friction. XML ontologies add meaning to all information components. The basic components now exist in enough cases that we can build mashed up systems.
I’m going to demonstrate some mashups. Some demos use the Internet, some have been locally crafted. Obviously we can’t demonstrate the 6 month project where we ran 1 million jobs with all interfaces in XML. Here are some of the components:
programs: MOPAC, GAMESS-US, DL_POLY, GULP, SIESTA, CASTEP, METADISE, etc.
editors: Jchempaint, etc.
renderers: Jchempaint, Jmol, JSpecView
Rich Client: Bioclipse
Services: CMLRSS, InChI. OpenBabel
Repository: SPECTRa/DSPACE (CMLCryst, CMLSpect, CMLComp)
Toolkits: CDK, JUMBO, JOELib, CIF2CML, OSCAR3, OSCARDATA
Demonstrations:
Semantic Markup (MACiE)
Simple Mashup: Placeopedia
Chemical Mashup: GoogleInchi. InChI API + Google search API
Semantic data and linking (clickable graphs and tables in CML). Jmol display
Journal-eating robots: OSCAR-DATA (chemical data)
OSCAR3 (chemical text and names) – mashup with PubChem
Reposition of data (SPECTRa) in institutional repositories
CMLRSS: molecular feeds (on Acta Crystallographica)
Rich client: Bioclipse
I shall try to get through all of these in 21.5 minutes – if the connections are slower I may have to omit some. At the end it should be clear that there is enough technology from the Open Source community to take chemistry into the 21st Century.
The next post will cover descriptions and predictions…
——————————————-
Some of these have static URLs and can be viewed relatively easily and robustly
http://www.placeopedia.com
http://wwmm.ch.cam.ac.uk/cryst/summary/acta/e/2006/07-00/ (static repository of Acta Crystallographica CIFs)
http://www-mitchell.ch.cam.ac.uk/macie/ (MACiE) (100 Entries | M0001 | animate reaction – needs IE)
http://wwmm-svc.ch.cam.ac.uk/wwmm/html/googleinchiserver.html GoogleInChI
-
Recent Posts
-
Recent Comments
- pm286 on ContentMine at IFLA2017: The future of Libraries and Scholarly Communications
- Hiperterminal on ContentMine at IFLA2017: The future of Libraries and Scholarly Communications
- Next steps for Text & Data Mining | Unlocking Research on Text and Data Mining: Overview
- Publishers prioritize “self-plagiarism” detection over allowing new discoveries | Alex Holcombe's blog on Text and Data Mining: Overview
- Kytriya on Let’s get rid of CC-NC and CC-ND NOW! It really matters
-
Archives
- June 2018
- April 2018
- September 2017
- August 2017
- July 2017
- November 2016
- July 2016
- May 2016
- April 2016
- December 2015
- November 2015
- September 2015
- May 2015
- April 2015
- January 2015
- December 2014
- November 2014
- September 2014
- August 2014
- July 2014
- June 2014
- May 2014
- April 2014
- March 2014
- February 2014
- January 2014
- December 2013
- November 2013
- October 2013
- September 2013
- August 2013
- July 2013
- May 2013
- April 2013
- March 2013
- February 2013
- January 2013
- December 2012
- November 2012
- October 2012
- September 2012
- August 2012
- July 2012
- June 2012
- May 2012
- April 2012
- March 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- September 2011
- August 2011
- July 2011
- May 2011
- April 2011
- March 2011
- February 2011
- January 2011
- December 2010
- November 2010
- October 2010
- September 2010
- August 2010
- July 2010
- June 2010
- May 2010
- April 2010
- August 2009
- July 2009
- June 2009
- May 2009
- April 2009
- March 2009
- August 2008
- July 2008
- June 2008
- May 2008
- April 2008
- March 2008
- February 2008
- January 2008
- December 2007
- November 2007
- October 2007
- September 2007
- August 2007
- July 2007
- June 2007
- May 2007
- April 2007
- December 2006
- November 2006
- October 2006
- September 2006
-
Categories
- "virtual communities"
- ahm2007
- berlin5
- blueobelisk
- chemistry
- crystaleye
- cyberscience
- data
- etd2007
- fun
- general
- idcc3
- jisc-theorem
- mkm2007
- nmr
- open issues
- open notebook science
- oscar
- programming for scientists
- publishing
- puzzles
- repositories
- scifoo
- semanticWeb
- theses
- Uncategorized
- www2007
- XML
- xtech2007
-
Meta
Peter,
to be very correct, I am now PostDoc in Mechelen, Belgium. I am working for a company called Tibotec BVBA, which is part of Johnson&Johnson. Research area is virology, especially HIV and HCV, and related areas;-)
Joerg
Thanks Joerg – I was aware you had moved but wasn’t sure where. I think that’s true for one of two of the others – not everyone has official addresses. They are welcome to post comments.
FWIW the Blue Obelisk is an excellent opportunity for people in companies to help develop the communal effort. Some companies will find it easier for efforts of indivduals to be seen as contributing to Open source and data. (Others won’t!)
Peter,
sorry, I just realized this by reading your entry again, but ALTANA Pharma has sponsored my position at university for several years. I do not know if they like to be mentioned, or not? Anyway, I really appreciated their support over those years, and if wanted or not … but the have also sponsored to BO movement … honor to whom is honor due!
Joerg
This came like a real invention to me, I mean Tufle’s statement about PowerPoint. I sometimes notice that PowerPoint does not always attain its primary goal of enhancing the comprehension of information. But I think thta it is most due to the abumdant use of graphics and flash effects. If to use and create a good high quality presentation that highlights the main points of your talk, I guiess it is still more powerful that Word document in conveying your idea.