The reason I use “content mining” and not “Text and Data Mining” is that science consists of more than text – images, audio video, code and much more. Text is the best known and the most immediately tractable and many scientific disciplines have developed Natural Language Processing (NLP). In our group Lezan Hawizy, Peter Corbett, David Jessop, Daniel Lowe and others have developed ChemicalTagger, OSCAR, Patent Analysis, and OPSIN. (http://www-pmr.ch.cam.ac.uk/wiki/Main_Page ). So the contentmine.org is exactly that – an org that mines content.
But words are often a poor way of representing science and images are common. A general approach to processing all images is very hard and 2 years ago I though it was effectively impossible. However with hard work some subsets can be tractable. Here we show you some of the possibilities in phylogenetic trees (evolutionary trees). What is described below is simple to follow and simple to carry out, but it took me some months of exploration to find the best strategy. And I owe a great debt to Noureddin Sadawi who introduced me to thinning – I haven’t used his code but his experience was invaluable.
But you don’t need to worry. Here’s a typical tree. Its from PLoSONE, (http://www.plosone.org/article/info%3Adoi%2F10.1371%2Fjournal.pone.0036933 – “Adaptive Evolution of HIV at HLA Epitopes Is Associated with Ethnicity in Canada” .
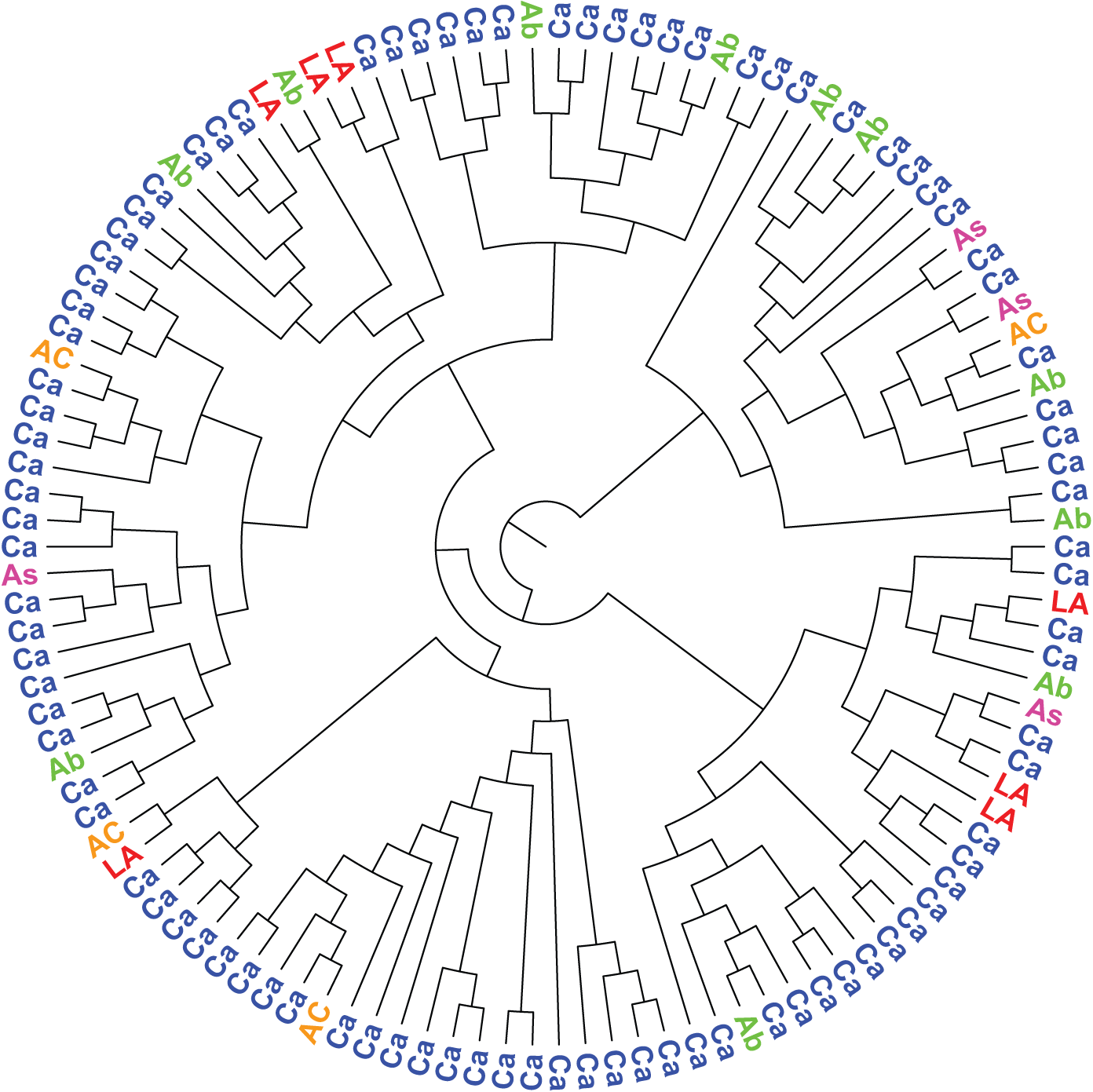
The tree has been wrapped into a circle with the Root at the centre and the leaves/tips on the edge of the circle. To transcribe this manually would take hours – we show it being done in a second.
There isn’t always a standard way of doing things but for many diagrams we have to:
- flatten (remove shades of gray)
- separate colours (often by flattening them)
- threshold (remove noise) and background)
- thin (remove all pixels except the 1-pixel-think backbone)
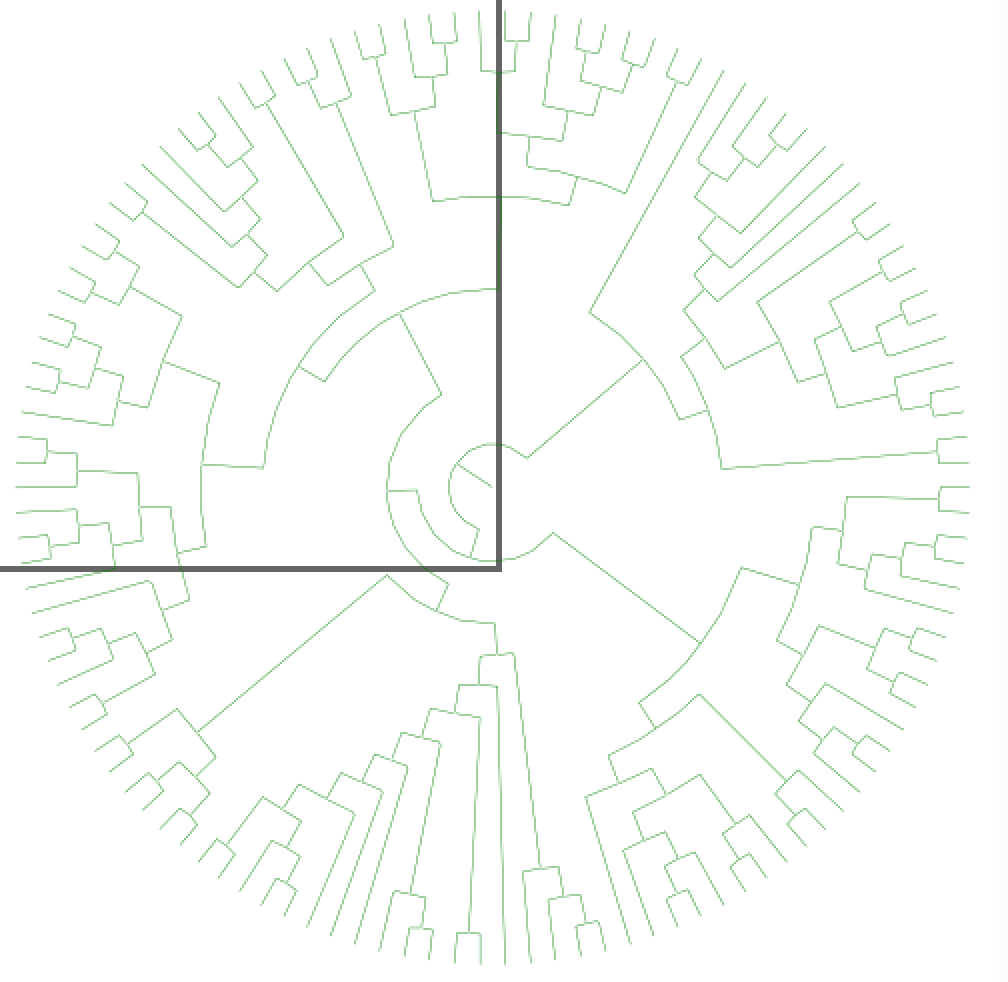
and here is the thinned diagram:

You’ll see that the lines are all still there but exactly 1 pixel thick. (We’ve lost a few colours, but that’s irrelevant for this example). Now we are going to look at the tree (and ignore the labels):

This has been selected automatically on pixel count, but we can also use bounding boxes and many shape characteristics.
We now analyse the structure and break it into connected components – a topological tree – by standard traversal methods. We end up with nodes and edges – this is a snapshot of a SVG.
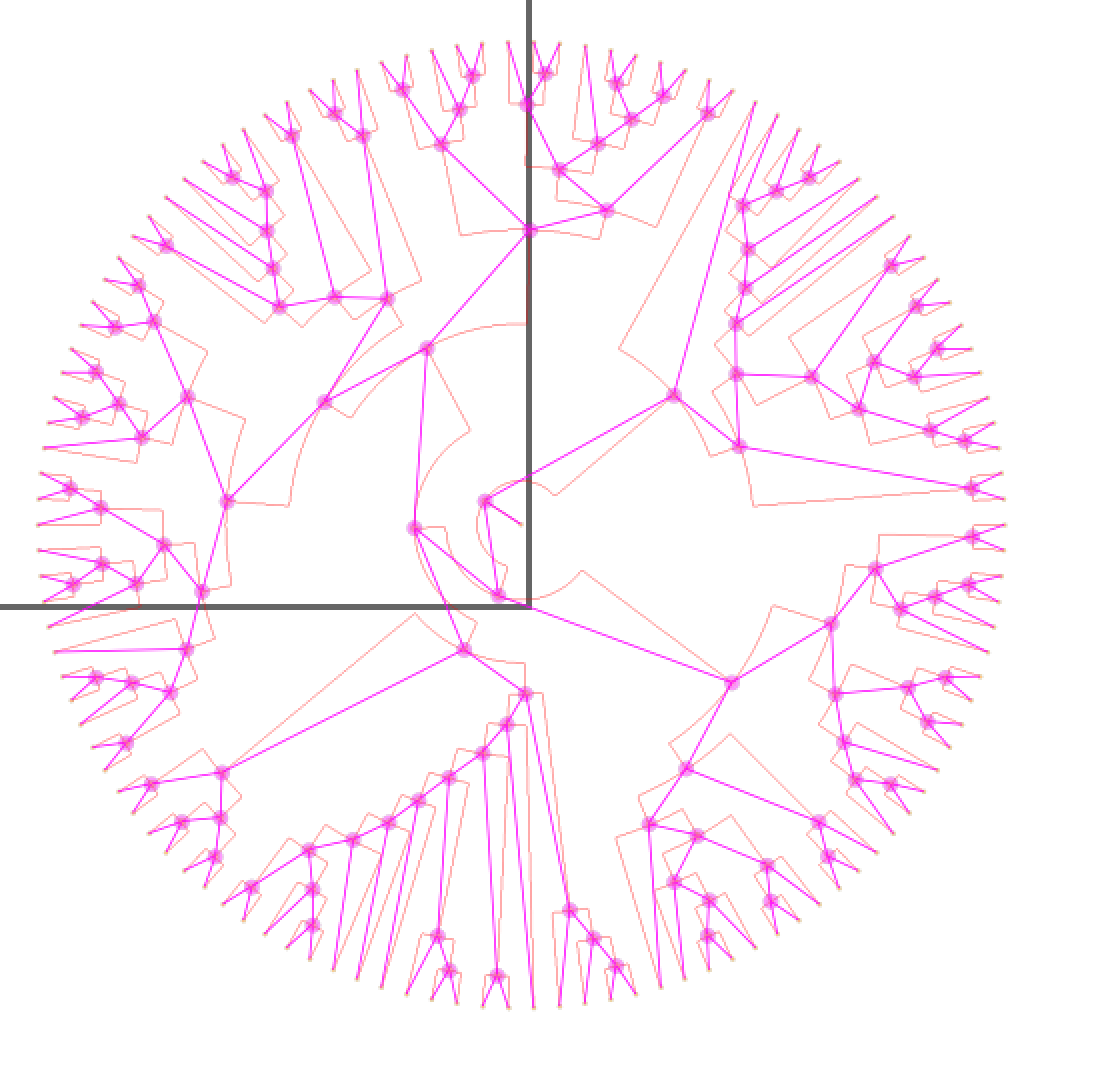
[The black lines are artifacts of Inkscape]. So we have identified every node and every edge. The next thing is to trace the edges – that’s easy if they are straight, but here they are curved. Ideally we plan to fit circles, but we’ll use segments for the time being:
The curves are actually straight-line segments, but… no matter.
It’s now a proper phylogenetic tree! And we can serialize it as Newick (or NexML if we wanted).
((n122,((n121,n205),((n39,(n84,((((n35,n98),n191),n22),n17))),((n10,n182),((((n232,n76),n68),(n109,n30)),(n73,(n106,n58))))))),((((((n103,n86),(n218,(n215,n157))),((n164,n143),((n190,((n108,n177),(n192,n220))),((n233,n187),n41)))),((((n59,n184),((n134,n200),(n137,(n212,((n92,n209),n29))))),(n88,(n102,n161))),((((n70,n140),(n18,n188)),(n49,((n123,n132),(n219,n198)))),(((n37,(n65,n46)),(n135,(n11,(n113,n142)))),(n210,((n69,(n216,n36)),(n231,n160))))))),(((n107,n43),((n149,n199),n74)),(((n101,(n19,n54)),n96),(n7,((n139,n5),((n170,(n25,n75)),(n146,(n154,(n194,(((n14,n116),n112),(n126,n222))))))))))),(((((n165,(n168,n128)),n129),((n114,n181),(n48,n118))),((n158,(n91,(n33,n213))),(n87,n235))),((n197,(n175,n117)),(n196,((n171,(n163,n227)),((n53,n131),n159)))))));
And here is an interactive tree by posting that string into http://www.trex.uqam.ca/ (try it yourself).
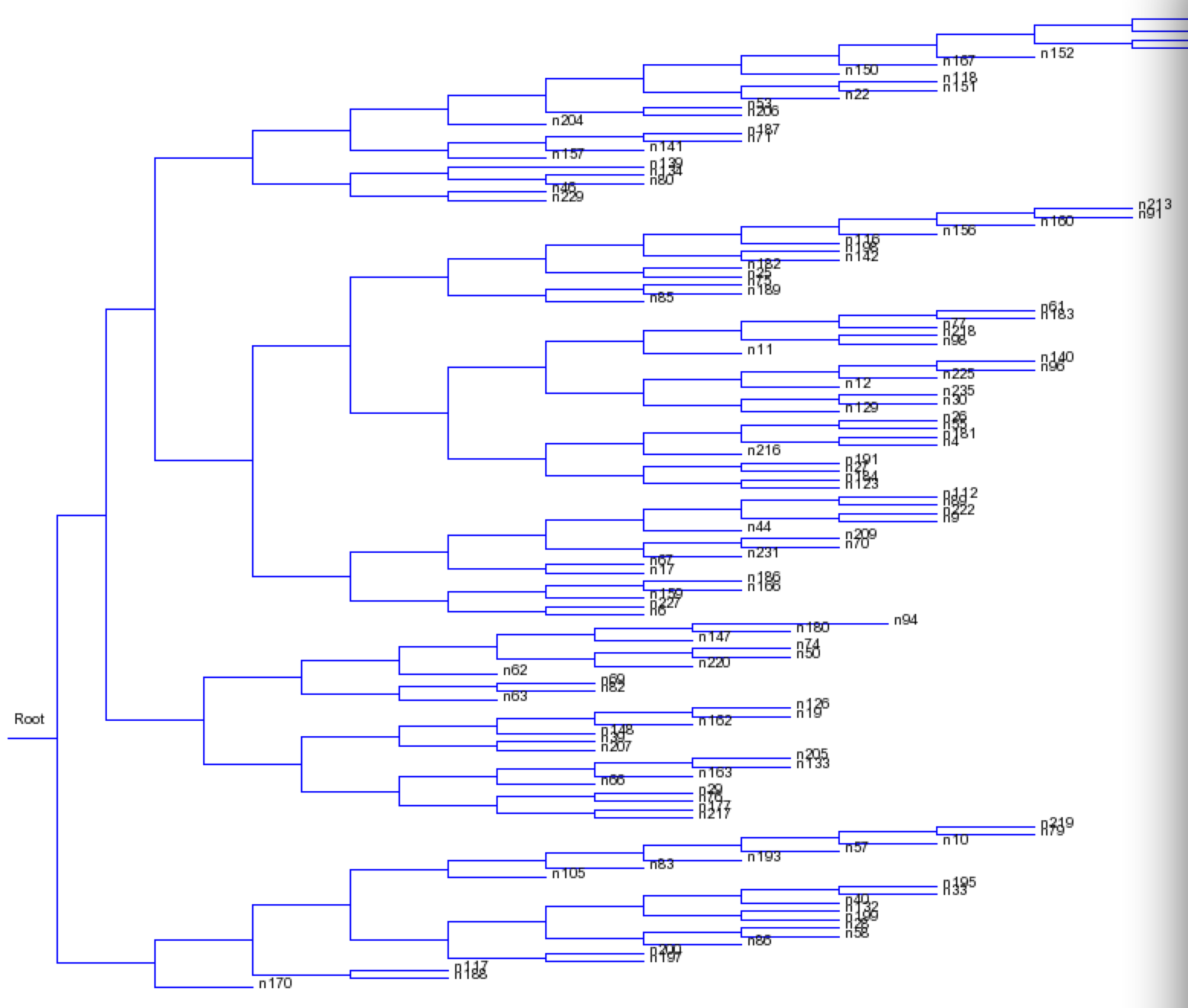
So – to summarize – we have taken a phylogenetic tree – that may have taken hundreds of hours to compute and extracting the key data. (Smart people will ask “what about the text labels?” – be patient, that’s coming).
… in a second.
That scales to over a million images per year on my single laptop! And the technology scales to many other disciplines and it’s completely Open Source (Apache2). So YOU can use it – as long as you give us the credit for writing it.
Pingback: Friday SNPpets | The OpenHelix Blog
Pingback: Content Mining: we can now mine images (of phylogenetic trees and more) – ContentMine