The proposed reforms to European Copyright will be disastrous. If you don’t know about them the links below are the seminal introductions. When you understand, then write to your MEPs as well. You are welcome to refer to this letter and copy some or all.
See Glyn Moody’s comprehensive and accurate arguments against the articles: https://boingboing.net/2018/06/07/of-dogs-breakfasts-article.html
Thanks to the wonderful http://writetothem.org which makes this easy and professional
[Cambridge]
Thursday 7 June 2018
Dear David Campbell Bannerman, Stuart Agnew, Patrick O’Flynn, Tim Aker, John Flack, Alex Mayer and Geoffrey Van Orden,
Articles 3, 11 and 13 of the Proposed Copyright Directive
I write as a scientist, Reader Emeritus of the University of Cambridge and also as founder of a Cambridge non-profit contentmine.org which employs high-tech staff in Cambridge.
I am desperately concerned about the proposed copyright reforms on which you will soon vote. The issues are concisely summarised by MEP Julia Reda https://juliareda.eu/eu-copyright-reform/ . (I have corresponded with Julia for 5 years and she understands all the issues both technical and political. She has installed and run our software!).
In summary the proposals are a mess, and unworkable. They bring confusion, rather than clarity and by default bring total power to “copyright owners”. If they are passed they will destroy knowledge-based innovation in Europe which will pass either to Silicon Valley, SE Asia or the Middle East. Knowledge innovators and companies in Europe are now “chilled” by copyright law and fearful of action. By default they will move to countries with more permissive laws, or simply close.
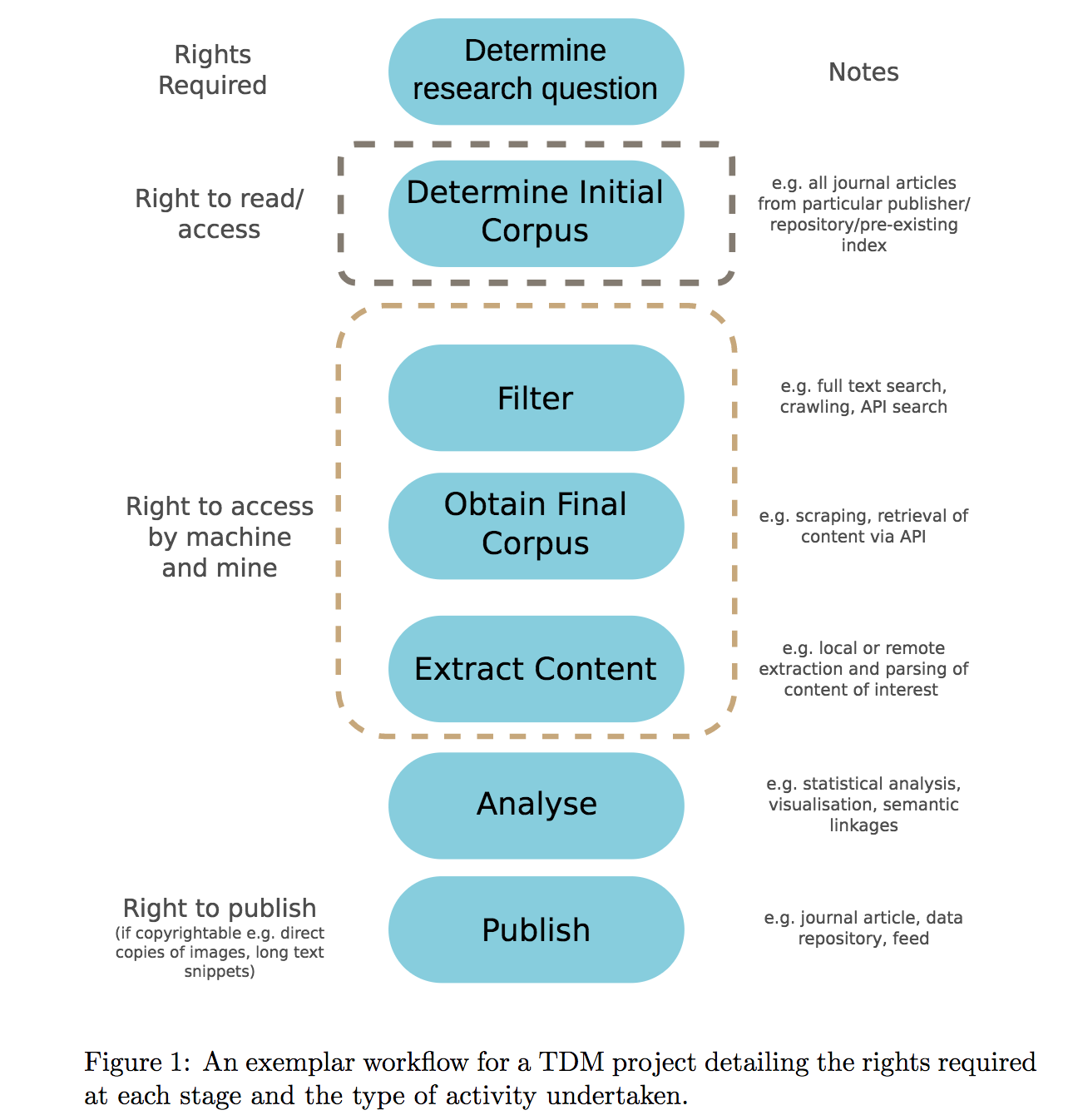
I am one of the most prominent TDM experts In Europe who both develops software and applications and also publicly campaigns for European Copyright reform. My, and ContentMine’s, goal is to develop machine technology which reads the whole scientific / medical literature and extracts validated factual knowledge for the benefit of us all on a daily basis (environment, health, bioscience, etc.). We have been partners in the H2020 project “FutureTDM” which analysed the problems that European TDM faces.
Europe spends 100 Billion Euro on STEM research but much of it (perhaps 80%) is underutilised because we need machines to help us. We work with clients who have to review 50,000 medical articles – taking months – to advise Medicine agencies about treatments and drugs. We build machine-assisted knowledge tools to speed this process by 10-fold or even more. Article 3 will kill this.
And if we use machines we are likely to fall foul of copyright law and be chilled or even face prosecution (as has happened elsewhere). As an example we have had several approaches from companies around the world who want us to mine the literature for them. We always have to consider the copyright problems upfront. For example TDM can only be carried out (without permission) by “Public Interest Research Organizations” for “non-commercial” purposes. Is PM-R a PIRO? Is ContentMine.org? If not then citizen-based innovation is being killed. Are we non-commercial? The only way to find out is to be taken to court. Julia Reda has proposed that every citizen should be allowed to carry out TDM for any purpose. That, and only that, is legal certainty.
Do we have to limit our innovation because of the lobbying by European “publishers”, many of whom do not even create their own content but act as rent collectors on 100 B Euro of publicly funded science and medicine?
- Article 13 stops us publishing knowledge
- Article 11 stops us telling people about knowledge
- Article 3 stops us reading knowledge.
Please oppose the current drafts and work with Julia Reda for a positive innovative copyright future for Europe. With your help we can be world leaders
Yours sincerely,
Peter Murray-Rust