Pandora is a researcher (won’t say where, won’t say when). I don’t know her field – she may be a scientist or a librarian. She has been scanning the spreadsheet of the Open Access publications paid for by Wellcome Trust. It’s got 2200 papers that Wellcome has paid 3 million GBP for. For the sole reason to make them available to everyone in the world.
She found a paper in the journal Biochemistry (that’s an American Chemical Society publication) and looked at http://pubs.acs.org/doi/abs/10.1021/bi300674e . She got that OK – looked to see if they could get the PDF – http://pubs.acs.org/doi/pdf/10.1021/bi300674e – yes that worked OK.
What else can we download? After all this is Open Access, isn’t it? And Wellcome have paid 666 GBP for this “hybrid” version (i.e. they get subscription income as well. So we aren’t going to break any laws…
The text contains various other links and our researcher follows some of them. Remember she’s a scientist and scientists are curious. It’s their job. She finds:
<span id="hide"><a href="/doi/pdf/10.1046/9999-9999.99999"> <!-- Spider trap link --></a></span>
Since it's a bioscience paper she assumes it's about spiders and how to trap them.
She clicks it. Pandora opens the box...
Wham!

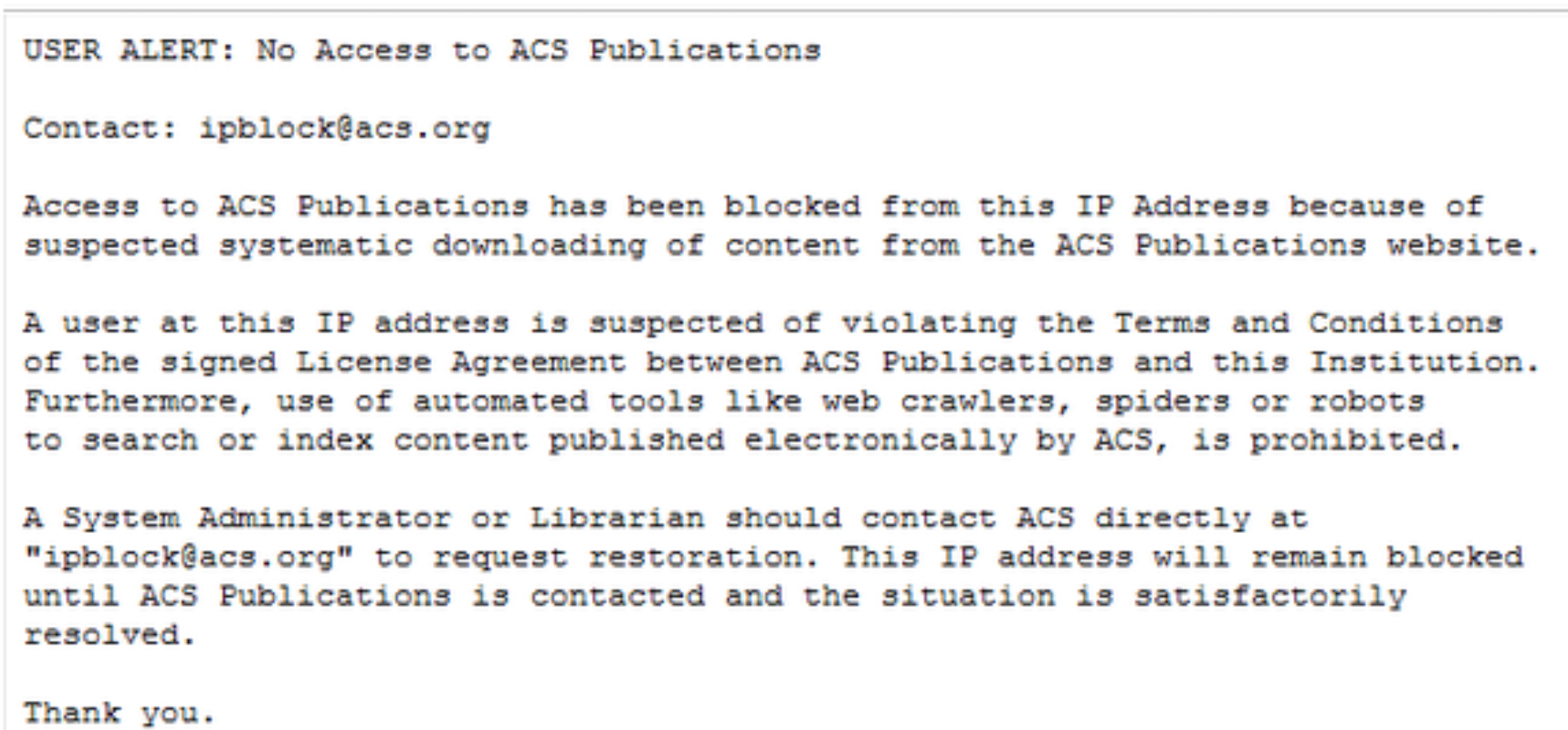
The whole university got cut off immediately from the whole of ACS publications. "Thank you", ACS
The ACS is stopping people spidering their site. EVEN FOR OPEN ACCESS. It wasn't a biological spider.
It was a web trap based on the assumption that readers are, in some way, basically evil..
Now *I* have seen this message before. About 7 years ago one of my graduate students
was browsing 20 publications from ACS to create a vocabulary.
Suddenly we were cut off with this awful message. Dead. The whole of Cambridge University. I felt really awful.
I had committed a crime.
And we hadn't done anything wrong. Nor has my correspondent.
If you create Open Access publications you expect - even hope - that people will dig into them.
So, ACS, remove your spider traps. We really are in Orwellian territory where the point of Publishers is to stop people reading science. I think we are close to the tipping point where publishers have no value except to their shareholders and a sick, broken, vision of what academia is about. UPDATE: See comment from Ross Mounce:
The society (closed access) journal ‘Copeia’ also has these spider trap links in it’s HTML, e.g. on this contents page:http://www.asihcopeiaonline.org/toc/cope/2013/4
you can find
<span id="hide"><a href="/doi/pdf/10.1046/9999-9999.99999"> <!-- Spider trap link --></a></span>
I may have accidentally cut-off access for all at the Natural History Museum, London once when I innocently tried this link, out of curiosity. Why do publishers ‘booby-trap’ their websites? Don’t they know us researchers are an inquisitive bunch? I’d be very interested to read a PDF that has a 9999-9999.9999 DOI string if only to see what it contained – they can’t rationally justify cutting-off access to everyone, just because ONE person clicked an interesting link?
PMR: Note - it's the SAME link as the ACS uses. So I surmise that both society's outsource their web pages to some third-party
hackshop. Maybe 10.1046 is a universal anti-publisher.
PMR: It's incredibly irresponsible to leave spider traps in HTML. It's a human reaction to explore.
The society (closed access) journal ‘Copeia’ also has these spider trap links in it’s HTML, e.g. on this contents page: http://www.asihcopeiaonline.org/toc/cope/2013/4
you can find
I may have accidentally cut-off access for all at the Natural History Museum, London once when I innocently tried this link, out of curiosity. Why do publishers ‘booby-trap’ their websites? Don’t they know us researchers are an inquisitive bunch? I’d be very interested to read a PDF that has a 9999-9999.9999 DOI string if only to see what it contained – they can’t rationally justify cutting-off access to everyone, just because ONE person clicked an interesting link?
The HTML I typed didnt render properly. If you look at the source HTML for http://www.asihcopeiaonline.org/toc/cope/2013/4 you’ll see
“/doi/pdf/10.1046/9999-9999.99999”><!– Spider trap link
In commentary elsewhere (in which I lamented the situation), a colleague pointed out that these “traps” are in place to prevent automated programs from eating up all of the bandwidth on a server. So, these spider traps do serve a legitimate function. I guess the question for those more knowledgeable than I is how the need to curb server costs can best be balanced with the need to make online resources as openly available as possible.
I believe there are much better ways of managing this than spider traps but I will blog it
If the problem is that programs are “eating up” bandwidth, then LIMIT THE BANDWIDTH of each user!
Remember people, if your legal service suddenly shuts you off, there’s always bittorrent. It’s not piracy if you’ve paid for the info, since you’re only buying the “license”, not the method of delivery.
That’s just not true. There are well-known ways to implement rate limiting and this is not one of them.
Your colleague gave an incorrect opinion about a technical subject. A spider trap as a solution and the problem of automated programs using excessive bandwidth are unrelated. A much better fix would be to rate limit when too much bandwidth is being used.
I am incredibly tempted to click that link, to highlight the craziness of this so-called ‘solution’, but I won’t. Even worse, one could share this link on Google+ with a big DO NOT CLICK THIS LINK, and see how many people do. If there’s a spike in ACS subscribers having to let ACS know that they are IP-blockd because their researchers are scientifically curious, then perhaps it will prompt a rethink of this practice…
PS I’m not advocating this course of action. Just pointing out that it is an interesting thought experiment. Also, it would be instructive for researchers that don’t have to think about paywalls because their library subscribes, but not in a pleasant way.
Totally agreed – as responsible as putting a bottle on the dinner table marked “CYANIDE – do not drink”. That would lead you to jail.
I cannot help contrast this comment of yours with your defence of Ross Mounce’s actions: here you seem to imply that David Roberts’ (or Roberts’s ?) tentative thought of posting it with “DO NOT CLICK” disclaimers would land him in jail, whereas the anger at Ross’ (or Ross’s?) actual posting of the link with a not so subtle hint of “CLICK THIS” seems to you “unfair”….
If you were to publish the link, and say some students/researchers from most or all universities were to go and click it, what would happen?
If it only takes one user from each university to cut off access to the university, it would be reasonably trivial, especially if the information became widespread, to pretty anonymously disable access to the publications to every university.
If every university is blocked from accessing them, then what is the purpose of them? How could the publisher respond? Would they go “Hah, now nobody can read anything we publish!”, or would they grant access to them and correct the faulty trap?
If only one facility has their access accidentally blocked, nobody will be motivated to do anything about it, and it won’t hurt anyone but that facility. If everyone does, it won’t seriously hurt anyone but the publisher.
I think the problem with your analogy is that the “bottle” isn’t actually on the table. The links are in the source code. I don’t really understand why a biochemistry researcher is digging around in the source code of the webpage. Is that a normal or sensible way to locate research articles?
So, to make your analogy fit, the bottle marked “CYANIDE – do not drink” is not on the dinner table at all, but in the back of the pantry where your dinner host never expected you would be snooping around.
…or am I missing something??
It’s reasonable to download and analyse visible pages in front of a paywall – this is how search engines work. IMO it’s reasonable to follow links as long as it doesn’t actively attempt to break the site. It’s reasonable to work out what links are worthwhile rather than simply wget the whole site.
We do this with publishers such as BMC and PLoS – they welcome what we are doing.
“Maybe 10.1046 is a universal anti-publisher. ” no its not 666, its n.o.t a gate to h.e.l.l.
10.1021 is ACS and 10.1046 is Wiley-Blackwell
Its the spider anti-scientist trap.
see: http://en.wikipedia.org/wiki/Wiley-Blackwell
see: http://www.weizmann.ac.il/home/comartin/doi.html
see: http://www.banbots.com/Spider-Traps.htm
BTW the correct link (click here) is:
http://informahealthcare.com/doi/pdf/10.1046/9999-9999.99999
“Since it’s a bioscience paper she assumes it’s about spiders and how to trap them.”
That gave me a good laugh. Perfectly understandable.
Spider traps are not a reliable method to manage access control to a website. They are more useful for detecting unusual activity behind a firewall or secure area of a site. For example, Edward Snowden may have been detected downloading classified documents with his bot software if the US government had the foresight to include obscure, dynamic spider trap files in their databases.
Don’t rely on a CSS rule (span id=”hide”) to hide the link. If the CSS file is not downloaded, the link will be visible. For example, a text browser (Linx) or a screen reader for the sight impaired may not download the CSS file the rule is embedded in. The JavaScript rule will render the link inoperative even if it is visible, assuming JavaScript is enabled in the browser. None of these solutions will prevent a person from cutting and pasting a link from the page HTML source code into a browser and banning themselves (and any other users who may be using the same IP). Hopefully a better warning will deter curious researchers from following the spider trap link in the future.
There are bots crawling this site. I have detected numerous ones that have visited the banbot site by following the link on this page. Publishers have the right (and I would argue the responsibility) to protect their content and to conserve bandwidth for legitimates users of the site. There are some really nasty bots traversing the Internet. Many of these are mining your names, email addresses, links, phone numbers, and other information that is posted.
There are more effective ways to deny access to illegitimate visitors without disrupting access to authorized users. I would suggest the ACS explore other alternatives to manage user access to the resources they wish to protect.
>>Don’t rely on a CSS rule (span id=”hide”) to hide the link. If the CSS file is not downloaded, the link will be visible. For example, a text browser (Linx) or a screen reader for the sight impaired may not download the CSS file the rule is embedded in. The JavaScript rule will render the link inoperative even if it is visible, assuming JavaScript is enabled in the browser. None of these solutions will prevent a person from cutting and pasting a link from the page HTML source code into a browser and banning themselves (and any other users who may be using the same IP). Hopefully a better warning will deter curious researchers from following the spider trap link in the future.
Excellent points.
Ross: putting the link out on twitter without any context was a bit of a questionable move… Would have been nice to know I was engaging in activism before clicking (although I guess that’s part of the point…).
Hope noone at Uni wants ACS access!
They seem to have now lifted the ban.
Ooops… I just blocked my IP to Copeia. I’d better check to see what damage I’ve done.
Thank you for alerting us to the finding shared by your reader. We are exploring and are committed to providing text and data mining solutions for readers of our open access content. In the meantime, for those who have unfortunately clicked on the link referenced and received the spider message, please email support@services.acs.org with your institution name and we will work to reinstate access at your institution as quickly as possible.
Darla Henderson, Ph.D.
Asst. Director, Open Access Programs
American Chemical Society
Thank you,
It will be important to know the cause of this and we hope and expect you will report.
It’s clear that no-one expects a single click to cut off a whole institution and I hope you can assure us that this can’t happen again.
Thanks! Have just emailed. I unintentionally blocked our office, which is a tad inconvenient for a publishing company… (We now can’t see the ACS papers we’ve previously linked from our sites and in journal citations!)
No one is quite sure what’s going on. I will blog my latest analysis soon.
With a bit of spoofing I’m sure you can DDoS this thing and probably block the entire internet from ACS.
For a bit of fun, you could especially spoof the own ACS IPs to stir things up a little.
I don’t think this would be a good idea, though funny. I wonder how they test this? Does the QA click, listen for all the other dev’s to groan “WTF!”, then he knows the link works?
Actually, the US Dept. of Justice holds that following non-obvious links you find by manually exploring HTML is a federal crime under the Computer Fraud and Abuse Act (18 U.S. Code § 1030). They have actually put people in jail for actions similar to this, see https://www.eff.org/deeplinks/2013/07/weevs-case-flawed-beginning-end .
I am not saying this is how things should be but this is how the federal government interprets it.
While a person has been put in jail, the judgement is not apparently without controversy and a lot of legal attention – so I wouldn’t count on it being “the law”. The one side is for preventing computer fraud with cryptic links that are basically functional. They don’t completely solve the problem for at least one group of people. On the other hand, there is now a third class of individual, one who is keenly aware of how to filter for these things by simply searching for “Spider trap link” and will now design scraper software to ignore those.
So anyhoo, I think all parties could have their issues solved by using terms that are generic enough that they can be interchanged about for something usual, but a human will read it as something not so great. I certainly don’t want to _do_ something like contact anyone just for visiting a link.
“Spider Trap Link” could be “You will have to contact us if you visit this”
The solution to this is simple. If your university uses any sort of content filtering software, just block that one URL at the gateway. Problem solved*.
* Under almost any circumstances, I would giving a standing ovation to any organization that does not use packet inspection/DPI or content filtering on their users. And fortunately, the spirit of freedom of information and privacy remains strong at many universities. This particular situation is one of a very, extremely tiny set of exceptions in which I would not be bothered by the use of filtering. Unfortunately, the reality is, once you have the capability to filter, and once you’ve done it a little bit, it suddenly seems like such a good solution to so many other problems instead of more intangible, ephemeral solutions like user education…
“The text contains various other links and our researcher follows some of them. Remember she’s a scientist and scientists are curious. It’s their job. She finds:
”
I’m curious. Where, exactly, did Pandora find this link? I’ve looked at the page source of http://pubs.acs.org/doi/abs/10.1021/bi300674e and searched it for the above code. It isn’t there. So what “various other links” did she have to follow to get to this?
I think it was inserted by the Atypon server as part of their service to ACS . After the meltdown I think they have removed the insertion module. Whetehr that’s try for all pubs I don’t know.