This is the first post of probably several in my concern about textmining. You do NOT have to be a scientist to understand the point with total clarity. This topic is one of the most important I have written about this year. We are at a critical point where unless we take action our scholarly rights will be further eroded. What I write here is designed to be submitted to the UK government as evidence if required. I am going to argue that the science and technology of textmining is systematically restricted by scholarly publishers to the serious detriment of the utilisation of publicly funded research.
What is textmining?
The natural process of reporting science often involves text as well as tables. Here is an example from chemistry (please do not switch off – you do not need to know any chemistry.) I’ll refer to it as a “preparation” as it recounts how the scientist(s) made a chemical compound.
To a solution of 3-bromobenzophenone (1.00 g, 4 mmol) in MeOH (15 mL) was added sodium borohydride (0.3 mL, 8 mmol) portionwise at rt and the suspension was stirred at rt for 1-24 h. The reaction was diluted slowly with water and extracted with CH2Cl2. The organic layer was washed successively with water, brine, dried over Na2SO4, and concentrated to give the title compound as oil (0.8 g, 79%), which was used in the next reaction without further purification. MS (ESI, pos. ion) m/z: 247.1 (M-OH).
The point is that this is a purely factual report of an experiment. No opinion, no subjectivity. A simple, necessary account of the work done. Indeed if this were not included it would be difficult to work out what had been done and whether it had been done correctly. A student who got this wrong in their thesis would be asked to redo the experiment.
This is tedious for a human to read. However during the C20 there have been large industries based on humans reading this and reporting the results. Two of the best known abstracters are the ACS’s Chemical Abstracts and Beilstein’s database (now owned by Elsevier). These abstracting services have been essential for chemistry – to know what has been done and how to repeat it (much chemistry involves repeating previous experiments to make material for further synthesis , testing etc.).
Over the years our group has developed technology to read and “understand” language like this. Credit to Joe Townsend, Fraser Norton, Chris Waudby, Sam Adams, Peter Corbett, Lezan Hawizy, Nico Adams, David Jessop, Daniel Lowe. Their work has resulted in an Open Source toolkit (OSCAR4, OPSIN, ChemicalTagger) which is widely used in academia and industry (including publishers). So we can run ChemicalTagger over this text and get:

EVERY word in this has been interpreted. The colours show the “meaning” of the various phrases. But there is more. Daniel Lowe has developed OPSIN which works out (from a 500-page rulebook from IUPAC) what the compounds are. So he has been able to construct a complete semantic reaction:
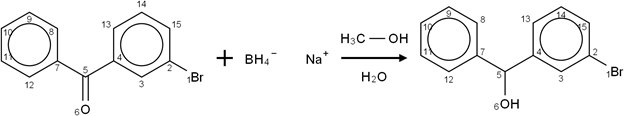
If you are a chemist I hope you are amazed. This is a complete balanced chemical reaction with every detail accurately extracted. The fate of every atom in the reaction has been worked out. If you are not a chemist, try to be amazed by the technology which can read “English prose” and turn it into diagrams. This is the power of textmining.
There are probably about 10 million such preparations reported in the scholarly literature. There is an overwhelming value in using textmining to extract the reactions. In Richard Whitby’s Dial-a-molecule project (EPSRC) the UK chemistry community identified the critical need to text-mine the literature.
So why don’t we?
Is it too costly to deploy?
No.
Will it cause undue load on pubklisher servers.
No, if we behave in a responsible manner.
Does it break confidentiality?
No – all the material is “in the public domain” (i.e. there are no secrets)
Is it irresponsible to let “ordinary people” do this/
No.
Then let’s start!
NO!!!!
BECAUSE THE PUBLISHERS EXPRESSLY FORBID US TO DO TEXTMINING
But Universities pay about 5-10 Billion USD per year as subscriptions for journals. Surely this gives us the right to textmine the content we subscribe to.
NO, NO, NO.
Here is part of the contract that Universities sign with Elsevier (I think CDL is California Digital Library but Cambridge’s is similar) see http://lists.okfn.org/pipermail/open-science/2011-April/000724.html for more resources
The CDL/ Elsevier contract includes [@ "Schedule 1.2(a)
General Terms and Conditions "RESTRICTIONS ON USAGE OF THE LICENSED PRODUCTS/ INTELLECTUAL PROPERTY RIGHTS" GTC1]
"Subscriber shall not use spider or web-crawling or other software programs, routines, robots or other mechanized devices to continuously and automatically search and index any content accessed online under this Agreement. "
What does that mean?
NO-TEXTMING. No INDEXING. NO ROBOTS. No NOTHING.
Whyever did the library sign this?
I have NO IDEA. It’s one of the worst abrogations of our rights I have seen.
Did the libraries not flag this up as a serious problem?
If they did I can find no record.
So the only thing they negotiated on was price? Right?
Appears so. After all 10 Billion USD is pretty cheap to read the literature that we scientists have written. [sarcasm].
So YOU are forbidden to deploy your state-of-the art technology?
PMR: That’s right. Basically the publishers have destroyed the value of my research. (I exclude CC-BY publishers but not the usual major lot).
What would happen if you actually did try to textmine it.
They would cut the whole University off within a second.
Come on, you’re exaggerating.
Nope – it’s happened twice. And I wasn’t breaking the contract – they just thought I was “stealing content”.
Don’t they ask you to find out if there is a problem?
No. Suspicion of theft. Readers are Guilty until proven innocent. That’s publisher morality. And remember that we have GIVEN them this content. If I wished to datamine my own chemistry papers I wouldn’t be allowed to.
But surely the publishers are responsive to reasonable requests?
That’s the line they are pushing. I will give my own experience in the next post.
So they weren’t helpful?
You will have to find out.
Meanwhile you are going to send this to the government, right?
Right. The UK has commissioned a report on this. Prof Hargreaves. http://www.ipo.gov.uk/ipreview-finalreport.pdf
And it thinks we should have unrestricted textmining?
Certainly for science technical and medical.
So what do the publishers say?
They think it’s over the top. After all they have always been incredibly helpful and responsive to academics. So there isn’t a real problem. See http://www.techdirt.com/articles/20111115/02315716776/uk-publishers-moan-about-content-minings-possible-problems-dismiss-other-countries-actual-experience.shtml
Nonetheless, the UK Publishers Association, which describes its “core service” as “representation and lobbying, around copyright, rights and other matters relevant to our members, who represent roughly 80 per cent of the industry by turnover”, is unhappy. Here’s Richard Mollet, the Association’s CEO, explaining why it is against the idea of such a text-mining exception:
If publishers lost the ability to manage access to allow content mining, three things would happen. First, the platforms would collapse under the technological weight of crawler-bots. Some technical specialists liken the effects to a denial-of-service attack; others say it would be analogous to a broadband connection being diminished by competing use. Those who are already working in partnership on data mining routinely ask searchers to “throttle back” at certain times to prevent such overloads from occurring. Such requests would be impossible to make if no-one had to ask permission in the first place.
They’ve got a point, haven’t they?
PMR This is appalling disinformation. This is ONLY the content that is behind the publisher’s paywalls. If there were any technical problems they would know where they come from and could arrange a solution.
Then there is the commercial risk. It is all very well allowing a researcher to access and copy content to mine if they are, indeed, a researcher. But what if they are not? What if their intention is to copy the work for a directly competing-use; what if they have the intention of copying the work and then infringing the copyright in it? Sure they will still be breaking the law, but how do you chase after someone if you don’t know who, or where, they are? The current system of managed access allows the bona fides of miners to be checked out. An exception would make such checks impossible.
[“managed access” == total ban]
If you don’t immediately see this is a spurious argument, then read the techndirt article. The ideal situation for publishers is if no-one reads the literature. Then it’s easy to control. This is, after all PUBLISHING (although Orwell would have loved the idea of modern publishing being to destroy communication).
Which leads to the third risk. Britain would be placing itself at a competitive disadvantage in the European & global marketplace if it were the only country to provide such an exception (oh, except the Japanese and some Nordic countries). Why run the risk of publishing in the UK, which opens its data up to any Tom, Dick & Harry, not to mention the attendant technical and commercial risks, if there are other countries which take a more responsible attitude.
So PMR doing cutting-edge research puts Britain at a competitive disadvantage. I’d better pack up.
But not before I have given my own account of what we are missing and the collaboration that the publishers have shown me.
And I’ll return to my views about the deal between University of Manchester and Elsevier.
Dear Peter, I agree that it’s a scandal. And the libraries did flag this up as a serious problem advocating for a new copyright limitation and exception for text and data mining – see the responses from the British Library, Libraries and Archives Copyright Alliance and JISC to the Hargreaves Review of IP http://www.ipo.gov.uk/ipreview/ipreview-c4e.htm.
But did libraries alert wider academia *at the time* when these restrictive clauses were introduced into the contracts? Was the academic body alerted? Because at least *I* would have made a fuss.
This issue is an interesting one and the publishers are about to take both barrels to each foot. They cannot defend an obsolete business model, no industry in history has ever succeeded in doing that and they won’t be an exception. They exist only because they have become an integral part of the peer reviewed publishing cycle because a decade or so ago there was no easy way to work without publishers. In other words publishers made science easier for scientists by providing a trusted outlet for their research.
Any second now the scientific and government communities will wake up to the fact that publishers are now making the work of researchers harder than it needs to be and a new business model will emerge leaving traditional publishers looking like the booksellers when Amazon turned up, unless of course the publishers reinvent themselves, but this blog doesn’t suggest that’s an imminent event!
Thanks John,
Delighted for your comment (I wish more people commented like you!) and optimism. I share this optimism, though the timescale is unpredictable. Unfortunately one of the greatest challenges is academia themselves – they don’t care in sufficient numbers.
SOLUTION: TEXT-MINE THE AUTHOR’S SELF-ARCHIVED FINAL DRAFT (GREEN OA)
Sixty percent of journals (including all Elsevier journals) have already endorsed immediate, unembargoed “green” open access self-archiving of the author’s refereed, accepted final draft in the author’s institutional.
A further 30% have endorsed open access self-archiving of the author’s unrefereed preprint.
That’s 90% of the literature right there.
Why not start text-mining that?
And meanwhile, why not push for something more immediately reachable than publisher copyright reform, namely the adoption of green open access self-archiving mandates by all research institutions and funders?
Once green open access is universally mandated, publisher green OA embargoes will die their natural and well-deserved deaths soon thereafter, and copyright reform will not be far behind.
Stevan,
You already know my answer:
(a) in a recent survey of bioscience only 2% of the closed literature is actually posted as Green Open Acess. Your figures are misleading. Even if 100% of people are allowed to self-archive – only 2% actually do. So there isn’t anything to textmine. Green OA simply isn’t working in many areas and there is no indication that it ever will.
(b) Secondly it breaks the law. Any publisher’s copy is copyright the publisher. I cannot legally textmine them. I know your position is “do it anyway – who cares about copyright?” I am afraid I have to – I wish I didn’t
(c) it is impossible to discover these articles in a systematic manner. If you think it is, please answer this question for me:
“Find me all articles in Cell/Nature/Science” which have been self archived by the authors and give me the URLs for those articles. I am currently (manually) trying to do this for all MRC papers in Cell. – so far I have found 5. None are Openly readable. I have no idea whether these have been self-archived. And remember that I want to do this on a large scale. I do not start with a list of 2-3 seminal papers. I start with a list of journals and want to find all open articles. and all self-archived articles in them. I want to trawl hundreds of thousands.
If you can answer(c) I will be grateful. If you don’t I will assume it’s because you cannot achieve this.
typo para 1 above: …institutional repositories.
Pingback: Unilever Centre for Molecular Informatics, Cambridge - Textmining: My years negotiating with Elsevier « petermr's blog
In physics, open archival is the norm. It could become the norm in the life sciences as well; it’s \just\ a question of making it the expected thing to do. That is to say, it’s an awareness thing.
Establishing the analog to Arxiv.org for the life sciences would be a good start, actually.
Fully agreed,
Most of the problems are social ones. It has been suggested multiple times. But many scientists won’t post in advance of publication for fear of being scooped. And some publishers forbid it
What about implementing this as a browser extension that talks to a web service (like Google Translate)? The service is not subject to any terms of use, since it wouldn’t be affiliated with any organization that’s signed a contract saying they can’t textmine. Each individual user would technically be violating that contract, but since going after individual users is rarely profitable (the whole business model of charging money to read papers goes away when you cut off all your subscribers for violating the letter of your contract), it could all work out anyway.
We wouldn’t tell blind people they can’t use screen readers, so why restrict what tools anyone can use to better understand science? Restricting textmining is unfair and makes the world a worse place. And if the “violators” are individuals, there’s not a whole lot the journals will do about it.
I have seriously thought about this. It works where the textmining can be done on a distributed model – where we can aggregate the micro-mines. It doesn’t work where a single user wants to mine a large amount – the publisher robots may spot this. The main problem is getting people to install the extension. It has to provide them with a useful purpose.
Mind you I think we are starting to develop these.
I think it comes down to money. (It always does.)
If you are successful in data-mining all their content, and your results are freely available outside their protected paywalls, then their revenue is likely to go down. It may be, once the content is liberated, they will go out of business within 5 years.
So don’t ever expect them to let you index or data-mine their content unless forced to by law. It’s the goose that laid the golden egg for them.
Saying the data is in the “public domain” is very confusing. Public domain means not copyrighted. I understand that’s the reason for the quotes, but it would be much clearer to say it’s published so not secret.
If you are an academic and wish to do something about this, there is an ongoing boycott of Elsevier (one of the worst offending publishers) at http://thecostofknowledge.com/
You can read a summary of the activities of these companies by George Monbiot at http://www.monbiot.com/2011/08/29/the-lairds-of-learning/
I have signed the Elsevier boycott
Two recent related petitions:
Scientists sign petition to boycott academic publisher Elsevier: http://www.guardian.co.uk/science/2012/feb/02/academics-boycott-publisher-elsevier
Public Access To Publicly Funded Research Should Stay Free and Open: http://forcechange.com/11079/public-access-to-publicly-funded-research-should-stay-free-and-open/
By the way, such indexing might also lead to trouble in the music industry.
Great read, hope you manage to get a positive resolution to this. Good luck!
You should take the time to discuss a bit with your librarian. As I did my PhD in Denmark (DTU), I naively wrote a robot to download the issues of a well known chemical data journal. In about a week of balanced usage, I went to discuss with our librarian. He had seen my usage, was nice not to talk about it, but told me this: I downloaded more than the entire university in a year… and it was not a lot. It means that at that time, they paid a bit less than the $35 per article price.
What is really important to notice is that Elsevier are not selling knowledge for most of the scientific communities but influence. That is, you are published, cited, you get ranking and your university reward you. This is what we need to address if we want to have really open access. We need a better way to “sell” influence to the university researchers and deans.
As I am building Cheméo http://chemeo.com a chemical data search engine, I suffer too. It is maybe time to unit and propose a legal, efficient and rewarding way for the researchers to publish their papers. We can do that on the side and let our influence grow.
I see a successful yc/kickstarter project here. A standard format for self published research on a platform with access control, versioning and open licensing. Go Wikipedia on their asses. $10 Billion is plenty of hosting 🙂
Pingback: My submitted HowOpenIsIt? comments - Ross Mounce