Scraped/typed into Arcturus
As we are making progress I thought we’d let you have a look at what we are doing. Because we believe in Openness we’re wearing our heart in the Open and telling you as it is created. This is OpenNotebook chemical informatics. Let’s count:
- The raw data are Open (patents)
- The code is Open (bitbucket)
- We’ve invited anyone who wants to be involved to join – and there’s good membership from the Blue Obelisk community and others
- We sync our contributions on Etherpad which is immediate and Openly visible
We are working on patents. The details can be found on the Etherpad (http://okfnpad.org/solo10 or http://okfnpad.org/openPatents ). A European Patent (EP) consists of:
An index file, with a name like:
EPO-2000-12-20.xml
This is a fully semantic, consistent name (EPO+date). You start to get a warm feeling. The data are well structured. However the indexfile itself is a nasty shock. It starts:
<ep-patent-document-list>
<ep-patent-document-ref>
<publication-reference>
<document-id lang=”en”>
<country>EP</country>
<doc-number>000000002141978</doc-number>
<kind>A1</kind>
<original-kind />
<correction-code />
<sequence />
<original-sequence />
<date>20100113</date>
</document-id>
</publication-reference>
<application-reference appl-type=”patent”>
<document-id>
<country>EP</country>
<doc-number>000000008724152</doc-number>
<date>20080331</date>
</document-id>
</application-reference>
<classification-ipc>
<text>A01D003464 A01B007300 A01B0059048</text>
</classification-ipc>
</ep-patent-document-ref>
Well we are used to non-semantic identifiers and they’re a good thing. Except that the identifiers have implicit semantics. You have to pull these strings apart to discover whether the document is a chemical one or not. It’s hideous – and I’m publicly grateful to David Jessop who has written the deconstruction code. David’s written stuff which downloads the Zips – it’s not trivial. It’s anything but trivial and involves repeated HTTP polling of the site to determine where the zipped patents are. I suspect we are losing some downloads because of the arcane nature of the index. But at least it can’t get much worse….
EP 1060157B1.zip
Oh yes it can. This is the filename of a downloaded zip. It’s got a SPACE in it. But not your honest to goodness char(32). Or char(8), but a beautiful char(160) hamburger space. A gold-plated non-breaking nbsp space. On we go…
- A Zip file which contains an unpredictable (or at least variable) number of goodies with names and labels you generally have to guess at. We haven’t worked out the whole crypanalysis but there are normally
- DOCUMENT.PDF. PDFs are normally human-readable but not machine-readable. These PDFs stretch the definition of human-readable. There are misspellings, illiteracies and the images are a delight for those who like hamburgers rather than cows. Reassembling the cow is not for the faint-hearted. Here’s a snippet
- Luckily (or since we pay taxes for it, in addition) there is:
- DOC00001.xml or something like EP00401685NWA1.xml. There are clearly at least two independent nomenclature systems for the files. These are XML files the EPO has created from the PDF. It’s done by humans – I have visited the office where they do it (it’s probably outsourced by now). A huge barn where humans are given the OCR of the patent and have to correct the text line by line (and add the line number).
- And there are between 0 and 2000 images. These are not only non-semantic but a veritable chamber of horrors. Here are two. The first is typical. Its quality is awful
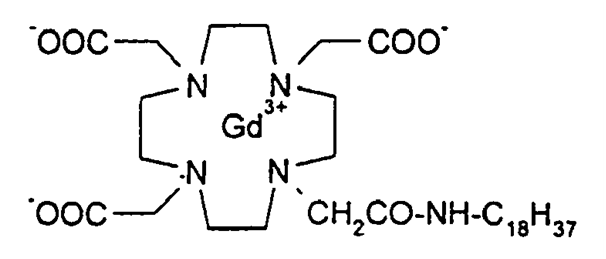
How many minus signs (as opposed to single bonds) are there in that picture? (HINT: There are some).
You think that’s bad? Here’s a chemical formula:
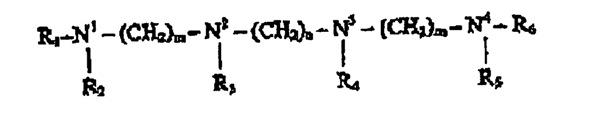
Now it wasn’t that bad when the author drew it. It has probably been deliberately obfusticated so that the patent is harder to understand. I THINK the characters are taken from only N,C,H,R, (,),1,2,3,4,5 m and n. I don’t think anyone on the planet can be absolutely sure what they are.
But then there is the one I posted some days ago and Egon cracked the puzzle. The quality was SO BAD that chemical bonds are simply missing.
This is the level of quality that is endemic in chemical informatics. (and patents).
However the XML is a lifeline and I’ll show you where we have got to in a following post
Ah, well