Andy Howlett and Mark Williamson in our group have been developing fantastic software.
It can read the whole scientific literature and analyse it in minute detail. One of the things we are starting with is chemistry. ChemVisitor (part of AMI2) can read chemical structure diagrams and chemical names and work out what they mean.
It takes less than a second. That’s pretty impressive, and we’ll be reporting this at the ACS meeting next month. Here’s the first picture we chose.
Our software can read the whole chemical literature every day and work out all the compounds. And I can do it on my laptop.
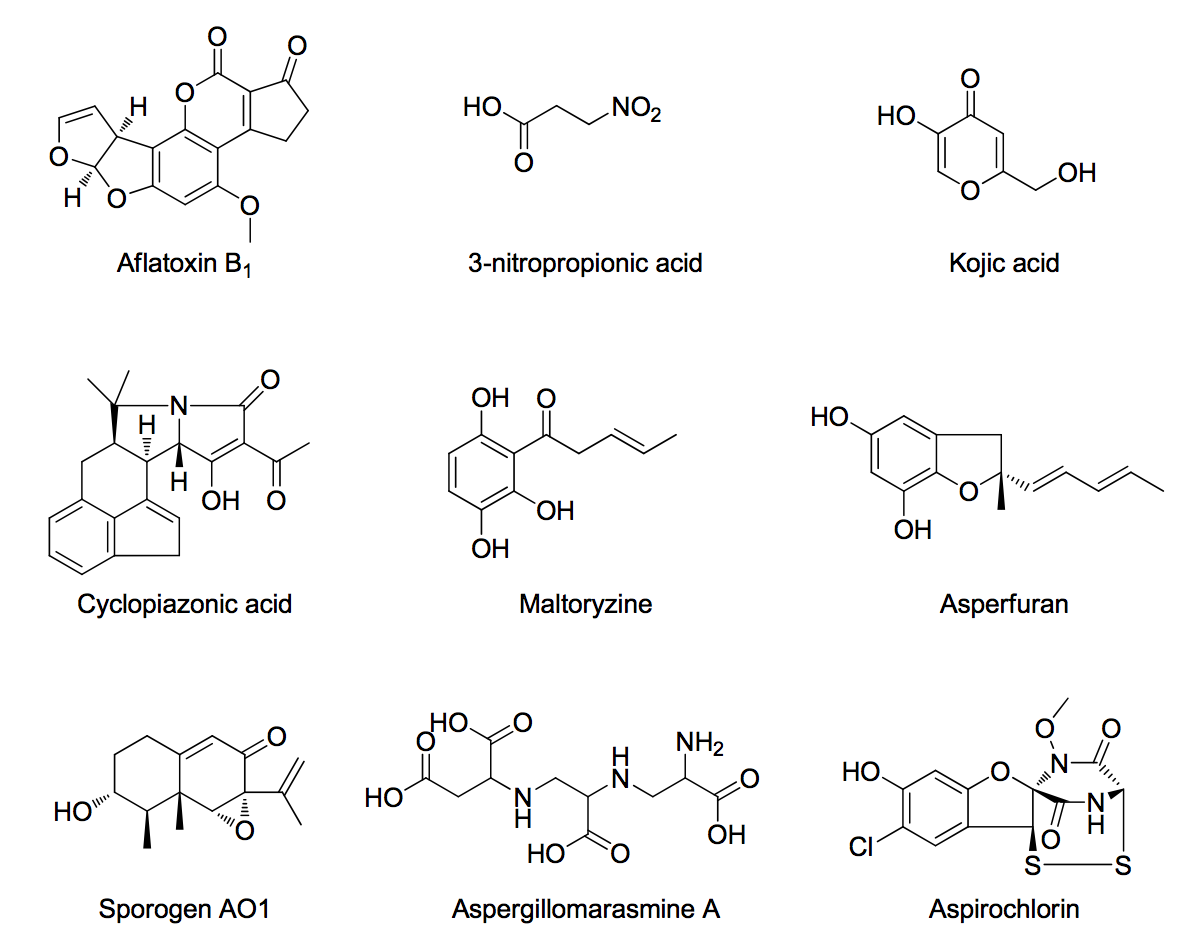
Hey – hang on – you’re violating copyright! And copyright is more important than science, isn’t it? Well, actually I am not violating it here, because this is from a CC-BY paper (I omit the attribution for a reason you’ll see). But yes, if it was from a Tetrahedron (Elsevier) article or J. American Chemical Society I would have to get permission. I’d probably have to pay. I wouldn’t be allowed to do X, Y or Z… It would take days without any likelihood of success.
And all I am doing is science. Note that chemical structure diagrams are NOT creative works. They are data. They are the only effective way of communicating what the compound is. But Elsevier and ACS and Nature and Science and … will all challenge me with lawyers if I take diagrams from non-CC-BY articles (e.g from Nature).
Now Andy has just mailed to say that this diagram is wrong. One of the compounds is incorrectly drawn. He’s contacted the author who has agreed. The error matters. These are compounds that many of you may eat. If the compound has the wrong name or formula then the science is badly flawed. And that can mean people die.
So try it for yourself. Which compound is wrong? (*I* don’t know yet) How would you find out? Maybe you would go to Chemical Abstracts (ACS). Last time I looked it cost 6USD to look up a compound. That’s 50 dollars, just to check whether the literature is right. And you would be forbidden from publishing what you found there (ACS sent the lawyers to Wikipedia for publishing CAS registry numbers). What about Elsevier’s Reaxys? Almost certainly as bad.
But isn’t there an Open collection of molecules? Pubchem in the NIH? Yes, and ACS lobbied on Capitol Hill to have it shut down as it was “socialised science instead of the private sector”. They nearly won. (Henry Rzepa and I ran a campaign to highlight the issue). So yes, we can use Pubchem and we have and that’s how Andy’s software discovered the mistake.
This was the first diagram we analysed. Does that mean that every paper in the literature contains mistakes?
Almost certainly yes.
But they have been peer-reviewed.
Yes – and we wrote software (OSCAR) 10 years ago that could do the machine reviewing. And it showed mistakes in virtually every paper.
So we plan to do this for every new paper. It’s technically possible. But if we do it what will happen?
If I sign the Elsevier content-mining click-through (I won’t) then I agree not to disadvantage Elsevier’s products. And pointing out publicly that they are full of errors might just do that. And if I don’t?…
Elsevier will cut off the University of Cambridge and the University will then contact me and tell me I have broken the sacred conditions that they have signed. Because no University ever challenges conditions that publishers set. The only thing that matters is price. So all universities have agreed with the publishers that readers cannot carry out text and data mining. They didn’t ask me – they just signed my rights away. If I continue I’ll probably face disciplinary action.
And the scientific literature will continue to be stuffed full of errors. And people will continue to die because of them.
Does anyone care? I don’t think so as no-one (ZERO) from a University has commented on my analysis of Elsevier’s restrictive TDM licence. They’ll just go ahead and sign it. Because it’s the easiest thing to do.
-
Recent Posts
-
Recent Comments
- pm286 on ContentMine at IFLA2017: The future of Libraries and Scholarly Communications
- Hiperterminal on ContentMine at IFLA2017: The future of Libraries and Scholarly Communications
- Next steps for Text & Data Mining | Unlocking Research on Text and Data Mining: Overview
- Publishers prioritize “self-plagiarism” detection over allowing new discoveries | Alex Holcombe's blog on Text and Data Mining: Overview
- Kytriya on Let’s get rid of CC-NC and CC-ND NOW! It really matters
-
Archives
- June 2018
- April 2018
- September 2017
- August 2017
- July 2017
- November 2016
- July 2016
- May 2016
- April 2016
- December 2015
- November 2015
- September 2015
- May 2015
- April 2015
- January 2015
- December 2014
- November 2014
- September 2014
- August 2014
- July 2014
- June 2014
- May 2014
- April 2014
- March 2014
- February 2014
- January 2014
- December 2013
- November 2013
- October 2013
- September 2013
- August 2013
- July 2013
- May 2013
- April 2013
- March 2013
- February 2013
- January 2013
- December 2012
- November 2012
- October 2012
- September 2012
- August 2012
- July 2012
- June 2012
- May 2012
- April 2012
- March 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- September 2011
- August 2011
- July 2011
- May 2011
- April 2011
- March 2011
- February 2011
- January 2011
- December 2010
- November 2010
- October 2010
- September 2010
- August 2010
- July 2010
- June 2010
- May 2010
- April 2010
- August 2009
- July 2009
- June 2009
- May 2009
- April 2009
- March 2009
- August 2008
- July 2008
- June 2008
- May 2008
- April 2008
- March 2008
- February 2008
- January 2008
- December 2007
- November 2007
- October 2007
- September 2007
- August 2007
- July 2007
- June 2007
- May 2007
- April 2007
- December 2006
- November 2006
- October 2006
- September 2006
-
Categories
- "virtual communities"
- ahm2007
- berlin5
- blueobelisk
- chemistry
- crystaleye
- cyberscience
- data
- etd2007
- fun
- general
- idcc3
- jisc-theorem
- mkm2007
- nmr
- open issues
- open notebook science
- oscar
- programming for scientists
- publishing
- puzzles
- repositories
- scifoo
- semanticWeb
- theses
- Uncategorized
- www2007
- XML
- xtech2007
-
Meta
I don’t agree that if you run such error-correcting software you will be sued for copyright infringement, because what is being reproduced is indeed facts, and facts are not subject to copyright. I do agree that if you foolishly signed a licence agreement that prohibited you from undertaking such TDM, you will be in breach of the licence, and so might permanently lose access to the database. So in my view, your headline statement is over-dramatic (because you won’t be sued, but you might lose access to the database), but that does not in any way weaken your message that these licences are unacceptable.
What we need is a case where a complaint is made that publisher with restrictive TDM licence is in breach of unfair contracts law.
Thanks Charles,
I agree that it is unlikely that I would be successfully sued, but that doesn’t alway stop publishers trying. And IMO Aaron Swartz hadn’t broken any law – he was preparing for legitimate TDM and loo what happened.
I absolutely agree that signing the click-through licence is extremely foolish.
Yes – the headline may be overly dramatic. But the silence from the universities has been deafening and this at least raises the question.
Yes, I wish someone would challenge publishers.
The fact that those problems *never* gets addressed is quite annoying.
So it is still not the case that private company locking away public research is forbidden ?
It is funny to see the intertwine of different responsibility level.
If publisher had to negotiate with the government, they’d loose, because of the absurdity involving money.
With you it seems you would not comply either, and by now researchers would have organized against it anyway.
But they go to a third point, the university. I am sure some are bothered but it is probably not their job to deal with issues like that (they think) which they might perceive as too big for them.
But it is no accident that they found the sweet spot.
>> So it is still not the case that private company locking away public research is forbidden ?
It is not against the criminal law AFAIK. So you have to take a private civil action. Which is expensive and may fail.
> Elsevier will cut off the University of Cambridge
As a Cambridge PhD alumni, I say what the hell: get us banned from Elsevier. Half of what they publish is poorly reviewed dross anyway.
As for the rest, well, reforming Elsevier et al. is impossible. They are incorrigible copyright thieves who have outlived the usefulness they once had. The sooner major universities stop paying them and stop their academics agreeing to their conditions, the sooner they will die. One simple starters: no peer-reviewing for journals or conferences that are not open access on publicly-funded time.
So, if you can take the heat, do it. Make the problem worse.
You academics should stop signing over your own research to Elsevier if you don’t want it locked up forever. Perhaps that also means not working for a university like Cambridge if they demand Elsevier published staff.
So, why did you omit the attribution on that diagram?
Because I was going to see if people could fins the article! Here it is: Metabolites 2012, 2, 39-56; doi:10.3390/metabo2010039 (And despite Beall I assert this is a reputable paper)
What the science community needs is a sufficiently large self-owned non-profit publishing organization – at least I think so.
It might be (most probably is the case) that publishing scientific papers is quite a lot of work and cannot be done by volunteers only (while all the peer reviewing is already done by unpaid collabprators, AFAIK). It will need a professional organization that may be financed by a foundation.
I admit to have zero experience with foundation but there should be some persons out there with some money to donate to setup such a foundation! That might be a way to open science…
You mean the way the ACS happens to be a non-profit publishing organization “owned” by it’s members? Elsevier didn’t happen to attack Wikipedia the way the non-profit ACS did.
The straightforward way is to make a law that forces recipients of grants to publish in open access journals.
For what it’s worth, it appears that the incorrect structure is cyclopiazonic acid. It is missing a nitrogen atom in the lower five-membered ring.
Briliiant! Thanks. Nice to have verification.
“Because no University ever challenges conditions that publishers set.”
I’m sorry, no. University librarians have been challenging publishers on licensing conditions for over a decade. Kenneth Frazier, former director of the libraries at UW-Madison, first encouraged librarians not to accept terms for what they call the “Big Deal” in D-Lib Magazine in 2001.
http://www.dlib.org/dlib/march01/frazier/03frazier.html
Choice quote from the article:
“Academic library directors should not sign on to the Big Deal or any comprehensive licensing agreements with commercial publishers.”
Much more has been written on the subject since, and recently some university libraries have dropped subscriptions completely because the publisher’s terms were unacceptable, or like Harvard, have encouraged faculty to publish in open-access journals instead of paywalled publications: http://www.theguardian.com/science/2012/apr/24/harvard-university-journal-publishers-prices
It seems you me you can get around the copyright issue by encouraging people to run the analyzer on the papers they read/cite/write themselves. Presumably if someone has the right to read a paper, they can also run that paper through your analyzer.
And if it prevents them from citing or submitting faulty papers, it’ll probably become standard practice.
Copyright issues bypassed!
“Because no University ever challenges conditions that publishers set.”
I realize you’re being hyperbolic here, but I feel it unfairly maligns university librarians. University librarians have been challenging publishers on licensing conditions for over a decade. Kenneth Frazier, former director of the libraries at UW-Madison, first encouraged librarians not to accept terms for what they call the “Big Deal” in D-Lib Magazine in 2001. You can read it at http://www.dlib.org/dlib/march01/frazier/03frazier.html
Choice quote from the article:
“Academic library directors should not sign on to the Big Deal or any comprehensive licensing agreements with commercial publishers.”
Can’t get much more straightforward than that.
Much more has been written on the subject since, and recently some university libraries have dropped subscriptions completely because the publisher’s terms were unacceptable, or like Harvard, have encouraged faculty to publish in open-access journals instead of paywalled publications: http://www.theguardian.com/science/2012/apr/24/harvard-university-journal-publishers-prices
Is ChemVisitor Open Source / Downloadable? The other way to achieve the same goal of higher standards in papers would be to allow people to run this software against their own papers (individual contributors before they submit like a spell checker, I’m assuming honest typo mistakes and not necessarily fundamental issues with the research, or even institutions like Elsevier to use against all the submissions). I understand if there are licensing issues with the Universities lawyers or if your PostDoc doesn’t want to release it, but it might be an idea.
YES
YES
No restrictions
http://www.bitbucket.org/petermr/ami
http://www.bitbucket.org/petermr/xhrml2stm-dev
Great. Good work.
BTW: The second link is wrong, I think you meant to type xhtml.
The software sounds amazing. Are you saying it’s capable of scanning images for diagrams info and reliably extract the compounds? This wouldn’t be opensource per chance?
If you made your software open source, would that not allow others from many universities to do the same thing? If enough people breached the licence conditions en masse, would it create enough pressure on Elsevier?
All my software IS Open Source and is designed for others to build on it. You convince the others and I’ll show them how to use the software.
“Elsevier will cut off the University of Cambridge and the University will then contact me and tell me I have broken the sacred conditions that they have signed.”
So basically what you’re saying is, we just need to find somebody who has nothing to lose. Cambridge has plenty of them at this time of the year: final year undergrads (esp. 4th year scientists, mathmos, and engineers) who have already landed a job outside academia for next year. There are plenty of free-copyright enthusiasts at SRCF, CUCaTS, and CUWPS who would love this challenge. I myself would’ve happily taken on this challenge if you posted this last year, when I was still a current member of the university!
Brilliant.
My feelings exactly. I deliberately didn’t push this idea myself but am very happy to endorse it.
These are the free thinkers who can change the world. Can you reach them?
Love & respect the skills and the attitude.
“Does anyone care? I don’t think so as no-one (ZERO) from a University has commented on my analysis of Elsevier’s restrictive TDM licence”. Keep it up, and employ any sort of tactics available. These vectorialists need to go down.
As a computational/theoretical chemist I do appreciate such a neet piece of software and I would love to see it in regular use by all publishers. I guess hardly any reviewer will check every structer in detail anyway. But one should always “trust but verify” when working with automated processes. After all the software can only detect a missmatch between a name and a structure (name might be wrong, too). When a structure drawing is not directly associated with a name but with a number later mentioned in the text it might miss errors that could be detected by a chemist.
Thanks,
I agree it won’t be perfect but neither are the humans. The machie can check very rapidly that the following are consistent:
* molecular mass (of various sorts)
* compositional formula
* structure diagram
* structure name
and also check that values reported have the right range (e.g. HOMO-LUMO, Dipole, deltaHf, etc.)
It will also check units and the non/existence of reported quantities.
Also we can content-mine LOGfiles.
It’s all free and we are starting to deploy it
Peter, I couldn’t find an e-mail address for you so I’ll respond via this blog. A few things you might consider before you present this.
Most if not all of the mistakes to be corrected are with the authors, not necessarily the publishers (although admittedly their reviewers should have caught them. As for the secondary publishers (CAS, Elsevier), the former has considerable resources to check structures. Beilstein, now part of Reaxys, used to have excellent redaction but I’m not so sure that Reaxys does. CAS does accept and welcomes corrections.
PubChem is open but the number of contributors of structures is immense. Any corrections must be made through the contributor (NCI only accepts corrections of data).
How do you choose where to run your programs? How is it determined that structures have errors?
Thanks for commenting Robert,
>>Most if not all of the mistakes to be corrected are with the authors,
Completely agree. Few publishers check anything.
>>not necessarily the publishers (although admittedly their reviewers should have caught them.
Yes, but if you have 100 compounds synthesised in a paper do you check every spectral peak?
>>As for the secondary publishers (CAS, Elsevier), the former has considerable resources to check structures. Beilstein, now part of Reaxys, used to have excellent redaction but I’m not so sure that Reaxys does. CAS does accept and welcomes corrections.
Since you can’t get access to CAS without paying we don’t know what is wrong.
>>PubChem is open but the number of contributors of structures is immense. Any corrections must be made through the contributor (NCI only accepts corrections of data).
>>How do you choose where to run your programs? How is it determined that structures have errors?
The following must all be internally consistent:
* name
* compositional formula
* chemical structure diagram
* elemental analysis
* formula mass
* expected outcomes of reactions
… and …
* spectral peaks (esp NMR)
* crystallography
There are also within-paper comparison – how are compounds 3a, 3b, 3c related to 4a, 4b, 4c and so on
We plan to do the whole literature, every day. For synthesis probably ca 10,000 new syntheses per day. that’s one every 8 secs – can do that on a laptop
Obviously this is a job for Anonymous white-hat hacking
Here is an article explaining white-hat hacking – basically motivated by public interest but not necessarily legal. http://websearch.about.com/od/anonymoussurfingsafety/a/what-is-a-hacker.htm
Is Elsevier’s recent announcement to make text mining easier on the technical level – http://www.nature.com/news/elsevier-opens-its-papers-to-text-mining-1.14659 – a reason for hope in this context, or is the “don’t disadvantage our products”-clause still in there?
It’s still a licence written to protect Elsevier. Read the last few blogs on this blog!
Pingback: Weekend reads: How much can one scientist publish? And more stem cell misconduct | Retraction Watch
Pingback: Augenspiegel 10-14: Forschungsglück, Kontinental-Alternativen und StarTrek auf dem Mars - Augenspiegel