The average large STM publisher receives several thousand USD (either in subscriptions or in author processing charges (APC)) to process an article. This huge and unjustified sum contains not only obscene profits (30-40 %) but also gross inefficiencies and often destruction of scientific content. The point is that publishers decide what THEY want to do irrespective of what authors or sighted human readers want (let alone unsighted readers or machines).
I am highly critical of publishers’ typesetting. Almost everything I say is conjecture as typesetting occurs in the publisher’s backroom process, possibly including outsourcing. I can only guess what happens. I’ve tried to estimate the per-page cost and it’s about 8-15 USD. So the cost per paper in typesetting alone is well over 100 USD. And the result is often awful.
The purpose of typesetting is to further the publisher’s business. I spoke to one publisher and asked them “Why don’t you use standard fonts such as Helvetica (Arial) and Unicode)” Their answer (unattributed) was:
“Helvetica is boring”.
I think this sums up the whole problem. A major purpose of STM typesetting is for one publisher to compete against the others. For me, scientific typography was solved (brilliantly) by Don Knuth with TeX and Metafont about 40 years ago. Huge numbers of scientists (especially physicists) and mathematicians communicate in (La)TeX without going near a typesetter. When graduate students write their theses they use LaTeX.
Or Word. I’ve read many student theses in Word and it’s perfectly satisfactory. Why shouldn’t we use LaTeX and Word for scientific communication?
Well, of course we do. That’s what ArXiV takes. If scientists ran publishing it would cost a fraction of the cost and increase scientific communication. That’s what Tim Gowers and colleagues plan to do – dump the publishers completely. I completely support this of course.
The publishers have grown an artificial market in creating “final PDFs”. They are often double-column. Why!? Because they can be printed. We are in the C21 and publishers are creating print. D-C PDF is awful on my laptop. Wrong aspect ratio and I have to scroll back for every page. It’s destroying innovation and we are paying hundreds of millions.
And of course every publisher has to be different. It would make sense for authors to use a standard way of submitting bibliography. There is, of course. It’s http://en.wikipedia.org/wiki/BibTeX. Free as in beer and free as in speech. Been going for nearly 40 years .
But its main problem is that it makes publishing too democratic and easy. Publishers would have nothing create gatekeeper rituals with. So instead they ask authors to destroy their bibliographic information by perpetuating arcane ways of “formatting references”. Here’s an example from Dino Mike’s paper (https://peerj.com/articles/36.pdf ) in PeerJ – and remember PeerJ is only a month or two old. But they still use the same 100-year approach to typesetting. Here’s a “citation” from Mike’s bibliography to a PLoS paper:

This is an example of the publisher-imposed wastage of human effort. What is the 5(10)? I actually have no idea (I can guess). It’s not needed – the DOI is a complete reference. It’s a redundant and error-prone librarian approach. But Mike had to type these meaningless numbers into the paper. And, not surprisingly, he got it wrong (or at least something is wrong). Because the target paper says:

“5(11)”. It’s a waste of Mike’s time to ask him to do this. And the reason is simple. Publishers and metapublishers make huge amounts of money by managing bibliography, and they do it in company-specific ways. So the whole field is far more complex and error-prone than it should be. Muddle the field and create a market. (Or historically, perpetuate a muddled market). It’s criminal that bibliography is still a problem.
Back to the typography:
- Mike wrote his paper in LaTeX. Word (see comments) He used Ticks (U+2713) [See comments after my blog post for what follows]. His Unicode ticks were converted by the publisher (Kaveh) into “Dingbats”. (Dingbats is not a standard PDF font – ZapfDingbats is and I have to guess they are the same (there are mutants of Dingbats).
-
I haven’t met Kaveh, but I have considerable respect for his company. But I do not accept his argument: he justifies typesetting by: “But the primary reason for “typesetting” is to produce an attractive “paginated” form of the information, according to traditions of hundreds of years
It is precisely “hundreds of years” that is the problem. We should be looking to the present and future. And I will show you a typical example of the irresponsible destruction of scientific information. But first I will comment that IMO publishers treat unsighted humans with apparent disregard. In analysing several thousands of papers I have come across huge numbers of characters which I am absolutely sure could not be interpreted by current tools. Here’s an example that I would be amazed if any machine-reader in the world could interpret correctly. It ought to speak “left-paren epsilon subscript(400) equals 816 plus-or-minus 56 cm superscript -1. ”
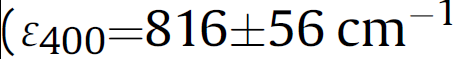
But it doesn’t get the “epsilon”. The true interpretation is so horrible that I hesitate to post it – and will leave it as an exercise for you to guess. I am almost sure that the horror has been introduced by the publisher as they use a special font (AdvOTb92eb7df.I) which I and no-one else has ever heard of.
Who’s the publisher? Well it’s one with a Directorate of Universal Access.
But that doesn’t seem to provide accessibility for unsighted humans or machines. And it’s even beaten our current pdf2svg software – it needs matrix algebra to solve.
UPDATE:
Villu has got it right. “So this “epsilon” is actually “three (italic)”, which is first flipped horizontally and then vertically? The italic-ness can be determined after the name of the font (ends with “.I”), and the number of flips by observing the fat tail of the stroke (should be at the lower left corner, but is at the upper right corner)?” PMR: It’s only flipped once – see chunk below where you can see that FakeEpsilon and 3 are the same way up.

PMR: The fontMatrix is actually FLIP * SKEW so comes out as
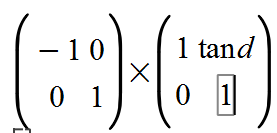
(d is the skew angle) Which gave me a negative font size (so failed to show in the output. Could a speech reader detect that and convert the “3” to an italic epsilon? Not a chance.
For the record Unicode has every character you could conceivably want in normal scientific use. Here are the epsilons from http://www.fileformat.info/info/unicode/ :





I’m getting bored. There are several more pages of UNICODE epsilons. It’s inconceivable that one of those wouldn’t be suitable. But no, the publisher takes our money to produce an abomination.
For the record, our manuscript was written in OpenOffice(*), and saved and submitted in MS-Word format, not LaTeX. I have used LaTeX in the past for a short paper or two and some longer reports, but as a format for a co-authored paper in palaeo, it is (sadly) a non-starter. No-one knows it except the very few of us with a background in computer science.
(*) Specifically, NeoOffice on my MacBook, LibreOffice on my Ubuntu Linux desktop box, and whatever Matt has on his various computers.
Thanks,
But you still used Unicode
So this “epsilon” is actually “three (italic)”, which is first flipped horizontally and then vertically? The italic-ness can be determined after the name of the font (ends with “.I”), and the number of flips by observing the fat tail of the stroke (should be at the lower left corner, but is at the upper right corner)?
A shameless plug regarding the BibTeX data format – I’ve been developing a FOSS Java library called JBibTeX for reading and writing *.bib files (http://www.jbibtex.org). Turns out that BibTeX is not so standard data format after all, because “major players” such as the Microsoft Academic Research have introduced their own variations of it. If you happen to maintain some *.bib files, then it would be interesting to see if you can manage to “break” my library.
Finally, how can I resolve a DOI to a full bibliographic record (eg. upload a DOI and get back a BibTeX file with the corresponding record)? I don’t know any free web service that could do that, but it would help me a lot if there was one.
> How can I resolve a DOI to a full bibliographic record (eg. upload a DOI and get back a BibTeX file with the corresponding record)? I don’t know any free web service that could do that, but it would help me a lot if there was one.
curl –location –header ‘Accept: application/x-bibtex’ ‘http://data.crossref.org/10.1371/journal.pone.0013982’
^ that should be two hyphens in front of each argument, and straight quotes rather than curly quotes; unfortunately my comment appears to have been “typeset”.
Try https://gist.github.com/hubgit/5012462 instead.
It’s worth pointing out that this will not work for all DOIs. Try for instance:
curl –location –header ‘Accept: application/x-bibtex’ ‘http://dx.doi.org/10.1000/182’
This is the DOI for “The DOI Handbook”. Finally, even if it does work, the data is coming from
more than one place, and there can be differences in the encoding.
I could explain why (well Alf already knows I am sure), but I’d die of boredom half-way through.
True, anything with the “10.1000” prefix probably won’t have metadata, as it seems to be used for example DOIs.
The DOI handbook? Example?
The problem is that the content negotiation is provided by CrossRef or DataCite. There are other
DOI agencies. mEDRA, for example, provide some DOIs for academic literature, and the DOI foundation provides that one. It’s not that there is no metadata; your content headers are just being ignored.
See, told you it was boring.
Thanks, that’s exactly what I’ve been looking for. I tested this approach with sample DOIs that correspond to Closed Access journal articles, and they all resolved very nicely to BibTeX bibliography records.
>>A shameless plug regarding the BibTeX data format – I’ve been developing a FOSS Java library called JBibTeX for reading and writing *.bib files (http://www.jbibtex.org). Turns out that BibTeX is not so standard data format after all, because “major players” such as the Microsoft Academic Research have introduced their own variations of it. If you happen to maintain some *.bib files, then it would be interesting to see if you can manage to “break” my library.
Have a look at BibJSON (http://www.bibjson.org/ ) it’s designed to tackle this problem and interoperate with BibTEX.
>>Finally, how can I resolve a DOI to a full bibliographic record (eg. upload a DOI and get back a BibTeX file with the corresponding record)? I don’t know any free web service that could do that, but it would help me a lot if there was one.
DOIs are resolved by commercial organization so the best you will get is free-gratis not free-libre. Academia woiuld rather pay organizations to create walled gardens than manage its own output.
There is a point to having a long reference, besides the URI, or other DOI. Humans are not very good at checking URIs, so turning this into a full reference gives your redundancy; if the URI is wrong, you
could probably still find the reference.
This is the logic behind my kcite plugin for wordpress. Under the hood, I reference using URI, or other identifier (including DOIs). Then, it produces the reference list for me. If I get the DOI wrong, the reference appears wrong. So it becomes in my interest, as the author to get the identifier correct, and the computer is helping me to check that it is correct. This has helped me to correct problems many times, including picking up broken DOIs in some cases. I use the same metadata, incidentally, (formatted as bibtex) when authoring to look up references.
Incidentally, on the walled garden approach of DOIs, it is not the only way. For instance, this link:
http://greycite.knowledgeblog.org/bib?uri=%2Fpmr%2F2013%2F02%2F21%2Fwhy-should-we-continue-to-pay-typesetterspublishers-lots-of-money-to-process-and-even-destroy-science-and-a-puzzle-for-you%2F
returns a bib file for your article. All the metadata comes from you. Anyone else could get it as well.
Peter
I think the word “typesetting” is partly to blame for the perception that the process is simply what has been in place for decades. In some cases that is largely true, but in the main, a lot more goes on from delivery of author files to the final products. It is now rare that the PDF is the only deliverable. Almost every publisher now demands XML, and rightly so. One of the challenges is to ensure that the XML and the PDF match precisely in content, and that is no easy task.
Our aim is to produce beautiful pages, which makes a paper a pleasure to read, on screen or on paper, and also to have structured data that is machine readable, and reliably archivable.
I agree that the details of what typesetters do is not publicized much. I think I will write a blog post with details of what happens, at least in our company. I promise to do that soon. 😉
Kaveh,
Thanks very much for your continued engagement. As I said I have respect for what you personally do (from the small amount I can see). The only published I know you service is PeerJ and that seems to have a high degree of adherence to Unicode. Since everything is a black art in closed rooms what follows is guesses.
>>I think the word “typesetting” is partly to blame for the perception that the process is simply what has been in place for decades. In some cases that is largely true, but in the main, a lot more goes on from delivery of author files to the final products. It is now rare that the PDF is the only deliverable.
Perhaps. But it’s often the only deliverable to the public.
>>Almost every publisher now demands XML, and rightly so. One of the challenges is to ensure that the XML and the PDF match precisely in content, and that is no easy task.
Agreed. The XML is almost never provided by the publisher (the OA publishers are an exception). So the community is paying for something that the publisher refuses to publish.
>> Our aim is to produce beautiful pages, which makes a paper a pleasure to read, on screen or on paper,
I would be amazed if most STM publications were trivially accessible to unsighted humans. Visual beauty is irrelevant. In contryast I have just analyzed two sets of goverment publications. No wiers fonts. Perfectly readable by sighted humans and at least the words interpretable by unsighted ones.
>> and also to have structured data that is machine readable, and reliably archivable.
I have seen no evidence of this at all. Where is this structured data? Where are the high resolution figures that publishing destroys into JPEGs?
>>I agree that the details of what typesetters do is not publicized much. I think I will write a blog post with details of what happens, at least in our company. I promise to do that soon. 😉
Thank you.
It is not your battle, but typesetting is increasingly an opportunity for publishers tobuild more walled gardens. “You can text-mine our XML but you’ll have to pay extra”. As if we didin’t already pay 15,000,000,000 USD to publishers.
You will have to convince the world that there is no more efficient system of authoring and communicating high-quality information.
>>Thanks very much for your continued engagement. As I said I have respect for what you personally do (from the small amount I can see). The only published I know you service is PeerJ and that seems to have a high degree of adherence to Unicode. Since everything is a black art in closed rooms what follows is guesses.
Thanks for drawing attention to details that are not discussed anywhere else!!
I do agree that having full Unicode compliance is a worthy goal. Perhaps when I write the full story of what we do it will become clear that we are trying to juggle many balls at once and why it has not been the top priority.
[…]
>>>>Almost every publisher now demands XML, and rightly so. One of the challenges is to ensure that the XML and the PDF match precisely in content, and that is no easy task.
>>Agreed. The XML is almost never provided by the publisher (the OA publishers are an exception). So the community is paying for something that the publisher refuses to publish.
This does not make sense to me, except that subscription publishers are thinking that they can repackage the XML in other forms, say Epub, and sell that again. My prediction is that with OA publishers mostly releasing the XML, others will follow before long.
So I am in absolute agreement that publishers should publish XML.
>>>> Our aim is to produce beautiful pages, which makes a paper a pleasure to read, on screen or on paper,
>>I would be amazed if most STM publications were trivially accessible to unsighted humans. Visual beauty is irrelevant. In contryast I have just analyzed two sets of goverment publications. No wiers fonts. Perfectly readable by sighted humans and at least the words interpretable by unsighted ones.
Peter, all else being equal, if you were reading a 50 page paper, whether on screen or on paper, would it not be nice that it was set in a readable font, had been designed to have just the right number of characters per page for reading, and had other typographic niceties embedded? Of course as long as this did not affect other requirements.
I agree that all content should be accessible to all, including the blind. I have attended a conference on “Math for the Blind” for that reason. But we have been concentrating on achieving accessibility not through PDF, but through XML and, perhaps even better, Epub3. So what we have been doing is to create a PDF for humans, and XML and Epub for accessibility and machine reading. (The fact that the XML is invisible to the public is beyond our control.)
>>>> and also to have structured data that is machine readable, and reliably archivable.
>>I have seen no evidence of this at all. Where is this structured data? Where are the high resolution figures that publishing destroys into JPEGs?
Well, if the high res and, vector images are submitted, then they should be available in some form to the reader. (But alternative, low res images will be needed as alternatives for html, low bandwidth etc.)
And the structured data I am referring to is in the XML.
>>It is not your battle, but typesetting is increasingly an opportunity for publishers tobuild more walled gardens. “You can text-mine our XML but you’ll have to pay extra”. As if we didin’t already pay 15,000,000,000 USD to publishers.
>>You will have to convince the world that there is no more efficient system of authoring and communicating high-quality information.
Well, publishers who pay our bills, but I do have my own views of course. So in the end we deliver what the publishers want. And their demands vary. Some want very good structured XML, and some very basic. Unfortunately most of them you cannot see in order to make up your own mind. 🙁
>>I do agree that having full Unicode compliance is a worthy goal. Perhaps when I write the full story of what we do it will become clear that we are trying to juggle many balls at once and why it has not been the top priority.
Any responsible publisher should have insisted on Unicode. We pay 3000 USD for a paper to be published and we deserved better.
>>Agreed. The XML is almost never provided by the publisher (the OA publishers are an exception). So the community is paying for something that the publisher refuses to publish.
>>This does not make sense to me, except that subscription publishers are thinking that they can repackage the XML in other forms, say Epub, and sell that again. My prediction is that with OA publishers mostly releasing the XML, others will follow before long.
No – my prediction is that publishers will charge us for “extra service”. they have dragged their feet over everything. Most offer restrictive “OA” licences.
>>So I am in absolute agreement that publishers should publish XML.
It’s not your battle – it’s mine since few other people care.
>>Peter, all else being equal, if you were reading a 50 page paper, whether on screen or on paper, would it not be nice that it was set in a readable font, had been designed to have just the right number of characters per page for reading, and had other typographic niceties embedded? Of course as long as this did not affect other requirements.
Firstly a 50-page paper is an archaic way of presenting information. Second – very few people read a 50-page paper – they dip into bits. So getting to the right bits is key and PDFs are appalling for this. And what is wrong with LaTeX? default fonts work fine for me and millions of others.
Most of the font-ing from publishers is beacuse they want to look different from each other. This does a disservice to readers, not a service.
>>>> and also to have structured data that is machine readable, and reliably archivable.
>>I have seen no evidence of this at all. Where is this structured data? Where are the high resolution figures that publishing destroys into JPEGs?
Well, if the high res and, vector images are submitted, then they should be available in some form to the reader. (But alternative, low res images will be needed as alternatives for html, low bandwidth etc.)
>>And the structured data I am referring to is in the XML.
Which I can’t see. So I presume you are converting authors’ tables into XML. What other structured data do you do? You do chemistry? You do graphs? You do flow diagrams? You do bar charts? How do you create tables other than simple syntactic formatting?
>>You will have to convince the world that there is no more efficient system of authoring and communicating high-quality information.
>>Well, publishers who pay our bills, but I do have my own views of course. So in the end we deliver what the publishers want. And their demands vary. Some want very good structured XML, and some very basic. Unfortunately most of them you cannot see in order to make up your own mind. 🙁
Yes – my battle is not with you. You give the publishers what they want – which is not what readers want, what authors want, what funders want.
May I discuss XML and EPUB as it is pretty in my field right now? — sorry for being a little bit off topic but I think it is worth sharing.
At the moment, the way a lot of publishers manage xml to make EPUB export is quite pathetic. As a matter of fact, they are killing the EPUB standard/ecosystem. I say publishers but I should say outsourcing companies, who just sell them really really low quality files. They don’t care at all, it’s all about profit.
If publishers still trust those companies in the next years, as the IDPF (in charge of EPUB) and w3c (in charge of web) are trying to work together more closely, then it could impact the standards of the web (and accessibility, etc.) as ebooks crash in the browser in a huge mess.
That is just to say beware to publishers who bet on XML. I’m not blaming the format but the so-called conversion houses who can’t even get HTML basic markup right. Today, a lot of them are just naughty pigs selling us dirt. And they are ruining both XML and EPUB. That must stop, they must be punished. — to tell it frankly, if the IDPF really cared about accessibility, then it would kick the a** of several of its (outsourcing companies) members…
>>May I discuss XML and EPUB as it is pretty in my field right now? — sorry for being a little bit off topic but I think it is worth sharing.
It’s completely in scope.
>>At the moment, the way a lot of publishers manage xml to make EPUB export is quite pathetic. As a matter of fact, they are killing the EPUB standard/ecosystem. I say publishers but I should say outsourcing companies, who just sell them really really low quality files. They don’t care at all, it’s all about profit.
I think you know more about this than I do – any information would be valuable. I have used the word “typesetter” but you are right – it’s outsourcing houses, and yes I completely expect them to do an awful job as there is no quality control from “customers”.
>>If publishers still trust those companies in the next years, as the IDPF (in charge of EPUB) and w3c (in charge of web) are trying to work together more closely, then it could impact the standards of the web (and accessibility, etc.) as ebooks crash in the browser in a huge mess.
I think we are close to a “huge mess” already. STM publishers don’t care about quality so their outsourcing certainly doesn’t.
>>That is just to say beware to publishers who bet on XML. I’m not blaming the format but the so-called conversion houses who can’t even get HTML basic markup right. Today, a lot of them are just naughty pigs selling us dirt. And they are ruining both XML and EPUB. That must stop, they must be punished. — to tell it frankly, if the IDPF really cared about accessibility, then it would kick the a** of several of its (outsourcing companies) members…
I assume IDPF == http://idpf.org/. I know nothing of them. Who does it represent? Publishers? because if so we can’t expect much change.
I think the best chance (it won’t be easy) is to take back control at the authoring level.
P.
Peter
You’ve worked long and hard to show the harm the publishing process does to the ability to use past science to build new science. I applaud and support your efforts, but I think there is another harm that hasn’t been brought up, the harm to the peer review process. I think both harms come from the fact that the present process makes it difficult if not impossible for scientists to use the tools they normally use to either review or read papers. As your posts over the last few months demonstrate, it is a huge task to get a paper into a form that allows the underlying data to be reliably read and manipulated by computer programs. Of course the data almost universally was originally in such a form as almost all data acquisition and analysis these days takes place via computer programs. If you want a scientist to review a paper, it is just these programs that would be the most productive in determining the internal consistency and relevance/relationship of the new data to what is already known, but no reviewer is going to go through the efforts you have been describing. You end up with a process that that prioritizes good looking pages over substance.
Although many publishers are not at all hesitant to take advantage, I wouldn’t want to let the scientific community off too lightly. In a number of major peer review failures, there seems to be a hunt to find a “bad apple” and the whole failure is waved off with some version of “peer review can’t handle deliberate deception”. This ignores the fact that in many cases even a fairly simple attempt to replicate the calculations shows serious problems. You have often said the scientific community should “take back our scholarship”, but I think the first step is for the scientific community to take responsibility for our scholarship.
Completely agree,
It isn’t a “bad apple” , it’s a systems failure. There is no incentive (except in a few disciplines) to do this for the benefit of science.
P.
Pingback: Ignorance As Argument — A Chemist Alleges Publishers Exploit Typography for Money | The Scholarly Kitchen
Pingback: Unilever Centre for Molecular Informatics, Cambridge - The Scholarly Kitchen Challenges me over STM PDFs; I’d like your help « petermr's blog