#animalgarden is mining the content in Open Access articles. [They don’t know what “Open Access” means [PMR: nor do I] so they are using CC-BY ]. They’re using Mike (Dino) Taylor’s papers as it’s about dinosaurs, giraffes and okapis (Chuff: Yeah!). They’ve agreed that the paper is legally minable. Now they are looking to see whether it’stechnically minable (whether the typography is tractable). #animalgarden has found some papers “very hard work” because of the typesetting.
AMI2: I’ve managed to read and translate (to SVG) the paper without errors
Chuff: how long did it take?
A: about 30 seconds for 40 pages. The images took the most time. There were no errors.
C: so the result is correct?
A: We can’t say that. All we know is that PDF read all the characters without throwing exceptions of LOGging errors. We know that for all the known fonts we can automatically convert the characters and for the rest we assume Unicode.
C: How do we check?
A: A human has to read the PDF and compare it to the extracted SVG. If s/he finds visual differences then the characters have been wrongly converted.
C: That’s OK. PMR can do it in 30 seconds.
A: No. PMR’s a human and humans are about 0.001 times as fast as me. So it could take hours to compare the paper.
C: And they get bored and make mistakes. PMR’s always making typos.
A: what does “bored” mean?
C: It means they get slower and slower, start making mistakes, wander off, drink beer, watch cricket, and stop altogether. Maybe we can get PMR to do just a few pages. It’s called “annotating” and “creating a gold standard”.
PMR: I have read the start of the PDF

P: and I have also read AMI’s output

P: They seem to be identical
A: Those are all ANSI characters. They are likely to be correct for most fonts. Check some characters above codepoint 127. Here’s Table 1:
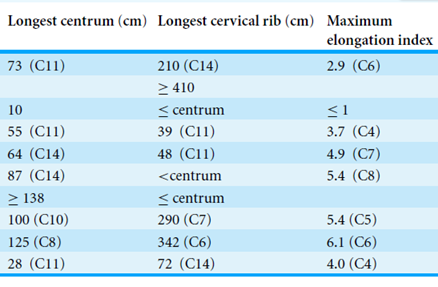
A: What page is it on?
C: I don’t know. There are no page numbers.
PMR: Yes there are. The pages says “2/41”
A: Is that a convention I should know?
P: Yes. But I think only PeerJ does it.
A: So it is more work for me.
P: Yes. Every publisher does it differently.
C: Doesn’t that confuse people
P: Yes. The publishers like to be different from each other. There is no technical reason. It serves no scientific purpose and make things harder and more fragile.
A: How many page syntaxes do I have to learn?
P: Several hundred at least.
A: That will take a long time.
P. And it’s boring. Anyway, what did you find, AMI2?
A: I get the following:

PMR: that looks identical! What are the Unicode characters > 127?
A:
I have looked up 8805 (decimal) in http://fileformat.info . It has all the Unicode codepoints with typical glyphs
PMR: The AMI2-pdf2svg distrib contains over 1000 of the commonest Unicode characters and U+2265 is included.
[long pause]
P: I have been reading the paper and the table of page 30 looks strange:
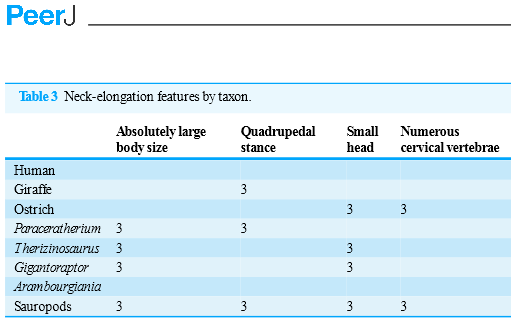
P: Now I have checked with the PDF and it’s different:
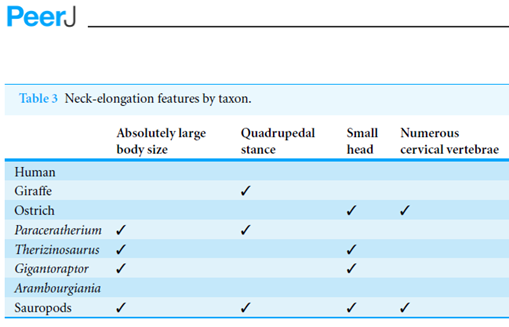
P: What’s happened?
A: Those ticks are Dingbats.
C: I don’t understand. A dingbat is a stupid person.
P: It can be (http://en.wikipedia.org/wiki/Dingbat_%28disambiguation%29 ) But Wikipedia also says (http://en.wikipedia.org/wiki/Dingbat ) …
A dingbat is an ornament, character or spacer used in typesetting, sometimes more formally known as a printer’s ornament or printer’s character.[citation needed] The term continues to be used in the computer industry to describe fonts that have symbols and shapes in the positions designated for alphabetical or numeric characters.[citation needed]
A: Do I have to know about Dingbats?
P: Yes. http://en.wikipedia.org/wiki/Zapf_Dingbats are one of the “Standard Type 1 Fonts (Standard 14 Fonts)”:

A: So I pick Dingbat-3. Is that right?
PMR: I don’t know. It seems murky… let’s close this blog and resume later
> A human has to read the PDF and compare it to the extracted SVG.
> If s/he finds visual differences then the characters have been wrongly converted.
Haven’t you thought about automating that?
Something like that:
1) Change the color scheme of the SVG. For example change all black strokes to red.
2) Paint the SVG to an image file.
3) Paint the PDF over the same image file. You probably cannot use PDFBox for that, because it’s incomplete/unreliable implementation.
4) Take a look at the image. You shouldn’t see any red color (because the red SVG should have been 100% painted over with black PDF). Humans can perceive color differences very fast.
5) Replace humans with image checksums. The checksum of the “PDF image” and the checksum of the “SVG image painted over with the PDF image” should always be equal. If they aren’t, only then bring humans into play.
Great comment, thanks
P>> A human has to read the PDF and compare it to the extracted SVG.
P>> If s/he finds visual differences then the characters have been wrongly converted.
V>Haven’t you thought about automating that?
P: Frequently. And some parts have been
V>Something like that:
>1) Change the color scheme of the SVG. For example change all black strokes to red.
>2) Paint the SVG to an image file.
>3) Paint the PDF over the same image file. You probably cannot use PDFBox for that, because it’s incomplete/unreliable implementation.
P: I would be very interested to know what’s defective in PDFBox. So far I haven’t found much
>4) Take a look at the image. You shouldn’t see any red color (because the red SVG should have been 100% painted over with black PDF). Humans can perceive color differences very fast.
The main problem is that the overlay won’t be exact. The SVG will have slightly different glyphs even for the same codepoint and the kerning will be different (the SVG will have none). Small characters like primes, superscripts, etc may get lost. There’s a moderate amount of work involved,
>5) Replace humans with image checksums. The checksum of the “PDF image” and the checksum of the “SVG image painted over with the PDF image” should always be equal. If they aren’t, only then bring humans into play.
It’s a good idea. It’s probably easier, however, to overlay glyph by glyph (we can extract the glyphmap from the PDF). And I shall need to write software that recognizes glyphs anyway – maybe using shapecatcher.com.
P.
That is strange. The tick characters in the submitted manuscript were not dingbat “3”s, but Unicode check-mark characters U+2713. And indeed if I copy a tick from the table in the published HTML, I can paste it into a plain-text area such as the browser’s URL bar and it displays correctly.
But the PDF, and only the PDF, uses character “3” in the Dingbat font. I wonder why?
(In practice, of course, I assume you’d use the HTML form, or better still the XML at https://peerj.com/articles/36.xml)
This is why I maintain that typesetting of STM papers destroys quality. You provided a perfectly good Unicode character and it is translated to a non-Unicode font – totally pointless.
The good news from this is that if FASTR happens with author-side CC-BY manuscripts the pre-publication mmanuscripts will be of higher typographical and semantic content than the “version of record”. People will realise they don’t need typesetters and save money and time. The animals would be interested in processing your manuscript.
I don’t use HTML/XML for the following reasons:
– most people dont have it – they keep PDFs. You can only get it on OA publishers sites.
– the images are a total destruction of quality , both resolution and semantics. It is a crime against science to turn a line drawing into a JPEG.
So I need the PDF for the vector graphics. I have no idea what the quality of mapping from XML to PDF is – I suspect patchy.
> This is why I maintain that typesetting of STM papers destroys quality.
> You provided a perfectly good Unicode character and it is translated to
> a non-Unicode font – totally pointless.
But the primary reason for “typesetting” is to produce an attractive “paginated” form of the information, according to traditions of hundreds of years. Of course there is good and bad typesetting.
The XML should be available for data mining and of course is useless for human reading.
>
> The good news from this is that if FASTR happens with author-side CC-BY
> manuscripts the pre-publication mmanuscripts will be of higher
> typographical and semantic content than the “version of record”. People
> will realise they don’t need typesetters and save money and time. The
> animals would be interested in processing your manuscript.
How would pre-publication manuscripts be of higher typographic quality than the typeset version? Most author produced PDFs are painful to look at. It is the job of the typesetter to improve that. If not, they are not doing a good job.
> I don’t use HTML/XML for the following reasons:
> – most people dont have it – they keep PDFs. You can only get it on OA publishers sites.
So is the answer not to get the XML from the publishers? They all have it, but only a few release it. And at least for those who do release it (PLOS, Hindawi, PeerJ…) why not use that instead of reverse engineering PDFs, which were originally designed to maintain the look of a page for ever, and nothing else?
> – the images are a total destruction of quality , both resolution and semantics. It is a > crime against science to turn a line drawing into a JPEG.
Vector images should remain as Vector, except for html where they need to be converted. I agree, daft to convert vector to bitmap. (There are exceptional cases where the vector file is an extremely large file and can be reduced in size by conversion.)
> So I need the PDF for the vector graphics. I have no idea what the quality of mapping > > from XML to PDF is – I suspect patchy.
Submitted on 2013/02/15 at 8:24 pm | In reply to pm286.
Thanks for your reply. I’ll take this up in a blog post…
>>But the primary reason for “typesetting” is to produce an attractive “paginated” form of the information, according to traditions of hundreds of years. Of course there is good and bad typesetting.
The primary purpose of a scientific communication should be to communicate science. Attractiveness is secondary. LaTeX communicates science in a fully effective manner.
>>How would pre-publication manuscripts be of higher typographic quality than the typeset version? Most author produced PDFs are painful to look at. It is the job of the typesetter to improve that. If not, they are not doing a good job.
I have read hundreds of theses in Word and LaTeX and they are not painful to look at (visually)
> I don’t use HTML/XML for the following reasons:
> – most people dont have it – they keep PDFs. You can only get it on OA publishers sites.
>>So is the answer not to get the XML from the publishers?
95% of publishers don’t release it so the only way to get it is reconstruct it.
>>They all have it, but only a few release it. And at least for those who do release it (PLOS, Hindawi, PeerJ…) why not use that instead of reverse engineering PDFs, which were originally designed to maintain the look of a page for ever, and nothing else?
Well I might use it to check the validity of my conversion, but there is no point in having a secondary stream that covers 5%
> – the images are a total destruction of quality , both resolution and semantics. It is a > crime against science to turn a line drawing into a JPEG.
>>Vector images should remain as Vector, except for html where they need to be converted. I agree, daft to convert vector to bitmap. (There are exceptional cases where the vector file is an extremely large file and can be reduced in size by conversion.)
In line-drawings the vector image, when compressed, may well be smaller. I agree that for some things, possibly anatomy, histology etc the SVG may be large.
Pingback: Unilever Centre for Molecular Informatics, Cambridge - Why should we continue to pay typesetters/publishers lots of money to process (and even destroy) science? And a puzzle for you. « petermr's blog